
Dieser Artikel enthält Best Practices für Problemstellungen, die sich aus der Datenschutzgrundverordnung (kurz: DSGVO, engl.: GDPR) für Personen ergeben, die für die Sicherstellung von DSGVO-Anforderungen bei der Speicherung und Verarbeitung von Datensätzen mit personenbezogenen Daten verantwortlich sind.
Diese können z. B. sein:
- Software Engineers, die Anwendungen entwickeln, um personenbezogene Daten zu erfassen und diese zu persistieren
- Data Engineers, die personenbezogene Daten aus unterschiedlichen Quellsystemen zusammenführen und für die Verwendung in Datenprodukten aufbereiten
- Data Scientists, die auf Basis personenbezogener Daten Prognosemodelle entwickeln, um eine Entscheidungsfindung zu unterstützen
Im Folgenden werden lediglich ausgewählte Teilaspekte der DSGVO vorgestellt. Der oben definierte Personenkreis ist in der Regel mit diesen ausgewählten Teilaspekten der DSGVO bei der täglichen Arbeit mit personenbezogenen Daten in direkter Weise, jedoch nicht ausschließlich, konfrontiert.
Dieser Artikel dient ausschließlich zu Informationszwecken. Es handelt sich hierbei nicht um Rechtsberatung. inovex GmbH und der Autor übernehmen keine Verantwortung für Handlungen, die auf der Grundlage der in diesem Artikel bereitgestellten Informationen unternommen werden, und können keine Haftung für deren Aktualität, Richtigkeit oder Vollständigkeit übernehmen.
Einführung in die DSGVO
Die DSGVO ist seit 2018 in Kraft und „schützt Grundrechte und Grundfreiheiten natürlicher Personen und insbesondere deren Recht auf Schutz personenbezogener Daten.“ Sie gilt, sobald die „Verarbeitung von personenbezogenen Daten im Rahmen der Tätigkeiten einer Niederlassung eines Verantwortlichen oder eines Auftragsverarbeiters in der (Europäischen) Union erfolgt, unabhängig davon, ob die Verarbeitung in der Union stattfindet“. Personenbezogene Daten sind branchenübergreifend von hoher Relevanz und allgegenwärtig. Die DSGVO bildet den rechtlichen Rahmen, in dem der Umgang mit personenbezogenen Daten für EU-Bürger reguliert ist. Die Umsetzung von DSGVO-spezifischen Anforderungen erfordert kontinuierlichen Aufwand und stellt Entwickler:innen vor nicht triviale Herausforderungen.
Personenbezogene Daten sind laut DSGVO Informationen, die sich auf eine „identifizierte oder identifizierbare natürliche Person beziehen. Als identifizierbar wird eine natürliche Person angesehen, die direkt oder indirekt, insbesondere mittels Zuordnung zu einer Kennung wie einem Namen, zu einer Kennnummer, zu Standortdaten, zu einer Online-Kennung oder zu einem oder mehreren besonderen Merkmalen identifiziert werden kann.“ Ein:e Verantwortliche:r ist laut DSGVO „eine natürliche oder juristische Person, Behörde, Einrichtung oder andere Stelle, die allein oder gemeinsam mit anderen über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten entscheidet.“
Grundsätze der DSGVO
Die DSGVO definiert Grundsätze, die den Rahmen zur Speicherung, Verarbeitung und Nutzung personenbezogener Daten vorgeben. Die Berücksichtigung dieser Grundsätze ist von höchster Priorität, auf der jegliche weitere sich aus der DSGVO ergebende Anforderungen aufsetzen. Im Folgenden werden einige ausgewählte Grundsätze exemplarisch erläutert:
- Der Grundsatz der Zweckbindung legt bspw. fest, dass personenbezogene Daten ausschließlich für festgelegte, eindeutige und legitime Zwecke erhoben werden und dass sie nicht in einer mit diesen Zwecken nicht zu vereinbarenden Weise weiterverarbeitet werden dürfen. Aus der Zweckbindung ergeben sich Konsequenzen auf weitere Grundsätze, wie z. B. dem der Datenminimierung und der Speicherbegrenzung, die im Folgenden beschrieben werden.
- Der Grundsatz der Datenminimierung fordert, dass der Umfang und Inhalt personenbezogener Daten dem festgelegten Zweck angemessen und erheblich sowie auf das für die Zwecke der Verarbeitung notwendige Maß beschränkt sein müssen. So würde es für einen legitimierten Verkauf altersbeschränkter Produkte bspw. ausreichen, statt des exakten Geburtsdatums einer Person lediglich die Information zu speichern, ob diese Person zum Zeitpunkt des Kaufs volljährig ist oder nicht.
- Der Grundsatz der Speicherbegrenzung ergänzt die zeitliche Dimension, indem er u. a. fordert, die Identifizierung der betroffenen Personen nur so lange zu ermöglichen, wie es für die Zwecke, für die sie verarbeitet werden, erforderlich ist. Der Grundsatz der Speicherbegrenzung greift bspw. nach einer Kontolöschung, spätestens, nachdem gesetzliche Aufbewahrungsfristen abgelaufen sind.
Das Prinzip der Datensparsamkeit
Grundsätzlich müssen personenbezogene Daten stets dem vorab festgelegten Zweck ihrer Nutzung entsprechen. Gemäß dem Prinzip der Datensparsamkeit sollte sowohl der Umfang als auch der Informationsgehalt personenbezogener Daten gerade für die Erfüllung dieses Zwecks ausreichend sein. Um auch die zeitliche Dimension der Zweckbindung zu berücksichtigen, sollte ein Prozess etabliert sein, der personenbezogene Daten nach Ablauf eines gewissen Zeitraums automatisch löscht. Dieser Zeitraum orientiert sich am Zweck der Nutzung und dessen Startzeitpunkt kann durch ein auslösendes Ereignis wie z. B. den Ablauf eines Vertrags definiert sein.
Eine vollständige Übersicht aller DSGVO-Grundsätze findet sich hier.
Rechte von betroffenen Personen
In der DSGVO sind neben den Grundsätzen auch Rechte von Personen festgelegt, deren personenbezogene Daten gespeichert und verarbeitet werden. Der oben erwähnte Personenkreis ist u. a. mit folgenden Rechten betroffener Personen bei ihrer täglichen Arbeit mit personenbezogenen Daten konfrontiert:
- Das Auskunftsrecht sichert betroffenen Personen zu, bei einem Verantwortlichen eine Kopie sämtlicher personenbezogener Daten, sowie Informationen zum Verarbeitungszweck, der geplanten Dauer der Speicherung und weiteres anzufragen.
- Das Recht auf Berichtigung sichert betroffenen Personen zu, bei einem Verantwortlichen die unverzügliche Korrektur fehlerhafter personenbezogener Daten zu verlangen.
- Das Recht auf Löschung sichert betroffenen Personen zu, eine unverzügliche Löschung sämtlicher personenbezogenen Daten bei einem Verantwortlichen anzufragen und verpflichtet den Verantwortlichen, dieser Anfrage unverzüglich nachzukommen, sofern es keine rechtlichen Gründe gibt, die die Löschung verbieten. Ein legitimer Grund, einer Löschanfrage nicht nachzukommen, kann bspw. sein, dass die anfragende Person einen laufenden Vertrag (Kreditvertrag, etc.) bei dem Verantwortlichen abgeschlossen hat und es dafür erforderlich ist, bspw. den Namen, die Anschrift oder das Geburtsdatum der Person vorzuhalten.
Eine vollständige Übersicht aller DSGVO-Rechte findet sich hier.
Profiling
Einen besonderen Stellenwert legt die DSGVO im Artikel 22 auf die Rechte betroffener Personen im Falle von automatisierten Entscheidungen und dem sogenannten Profiling. Es geht dabei im Wesentlichen um das Sammeln und Auswerten personenbezogener Daten zur „Vorhersage von Verhalten oder anderen Eigenschaften“ betroffener Personen und einer darauf basierenden, automatisierten Entscheidung, die eine „rechtliche Auswirkung mit einer erheblichen Beeinträchtigung“ für die betroffene Person darstellt. Die DSGVO sichert betroffenen Personen das Recht zu, nicht ausschließlich einer derartigen automatisierten Entscheidung unterworfen zu werden. Beispiele hierfür könnten sein: die Konditionierung und Vergabe eines Kredits oder die Durchführung und Ausgestaltung eines Einstellungsverfahrens (siehe auch: Erwägungsgrund 71).
Herausforderungen
Die zentrale Herausforderung bei der Umsetzung von DSGVO-Anfragen wie Lösch-, Auskunfts- oder Korrekturanfragen ist die Identifikation sämtlicher personenbezogener Daten einer anfragenden Person. Um dies zu gewährleisten, ist es notwendig, einen stets aktuellen und lückenlosen Überblick über sämtliche Systeme und Datensätze innerhalb des Verantwortungsbereiches und eine effiziente Möglichkeit zum Auffinden der angefragten Daten in den jeweiligen Datensätzen zu haben. Je nachdem, wie Daten in einem Unternehmen organisiert sind, kann dies mehr oder weniger aufwendig sein:
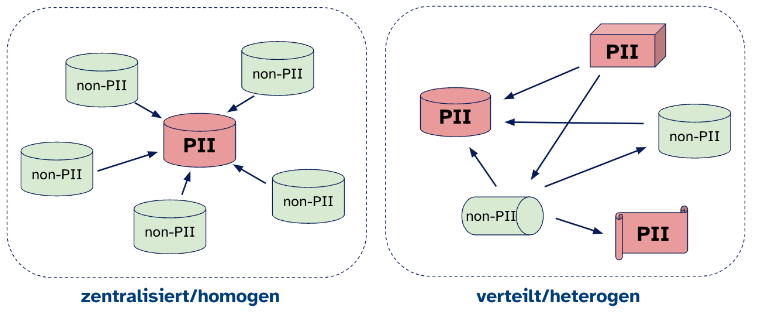
Die obigen Grafiken illustrieren, wie Daten in einem Unternehmen organisiert sein können und stellen die beiden Extreme an den Enden eines Spektrums dar.
Zentralisiert vs. Verteilt
Wenn personenbezogene Daten zentral organisiert sind, so bedeutet es, dass es insgesamt nur wenige Datensätze mit personenbezogenen Daten und darin nur wenig bis gar keine Redundanz gibt. Diese personenbezogenen Datensätze können zur Anreicherung von nicht personenbezogenen Datensätzen verwendet werden. Dies kann z. B. dann erfüllt sein, wenn Datensätze gemäß einer Normalform modelliert sind. Sind personenbezogene Daten hingegen verteilt organisiert, so bedeutet dies, dass sie redundant, also mehrfach und an verschiedenen Stellen, gespeichert sind.
Homogen vs. Heterogen
Sind Daten homogen organisiert, so bedeutet dies, dass nur eine geringe Anzahl von Datenbanksystemen zur Speicherung von personenbezogenen Daten eingesetzt werden. Dies ist bspw. bei klassischen Data Warehouse Ansätzen der Fall, bei denen Daten größtenteils in einzelnen, leistungsstarken, relationalen Datenbanksystemen verwaltet werden. Wenn Daten hingegen heterogen organisiert sind, bedeutet es, dass Daten in unterschiedlichen Systemen und Formaten gespeichert werden. Dies entspricht bspw. eher einer Data Lake Architektur.
Effizienz von Schreiboperationen
Zusätzlich werden bei Speichersystemen, die für große Datenmengen optimiert sind, oftmals keine Schreiboperationen auf einzelnen Einträgen unterstützt. Um einzelne Einträge zu verändern, ist es dann erforderlich, ganze Dateien bzw. Blöcke neu zu schreiben, was entsprechend ressourcenintensiv und ineffizient ist.
Abwägungen bei Architekturentscheidungen
Zusammenfassend lässt sich festhalten, dass das Auffinden sämtlicher personenbezogener Daten einer anfragenden Person umso aufwendiger ist, je mehr der folgenden Merkmale auf eine Datenarchitektur zutreffen:
- Daten liegen in unterschiedlichen Systemen und Formaten vor
- Daten liegen redundant und nicht pseudonymisiert (d. h. in Klartext) vor
- Daten werden von einer Vielzahl von Teams verarbeitet und gespeichert
- Es kann nicht effizient auf Daten zugegriffen werden
Lösungsansätze
Sowohl Lösch- als auch Auskunftsanfragen müssen oftmals über viele Teams und deren Datenprodukte verteilt und von diesen erfüllt werden. Üblicherweise wird dies durch ein sog. Publish/Subscribe Pattern umgesetzt, bei dem es einen zentralen Service für die Annahme von Lösch- und Auskunftsanfragen gibt und welcher diese Anfragen innerhalb des Unternehmens verteilt. Zum Entkoppeln des zentralen Services und der Teams kann ein Message Broker eingesetzt werden, der die Anfragen für eine gewisse Zeit vorhält. Das wesentliche Merkmal dieses Ansatzes ist, dass kein zentrales Wissen über sämtliche eingesetzten Datenbanktechnologien erforderlich ist und jedes Team eigenverantwortlich die DSGVO-Anfragen umsetzt. Eine entsprechende Architektur kann z. B. wie folgt aussehen:

Die GDPR Subscriber konsumieren Lösch- und Auskunftsanfragen und führen die notwendigen Operationen zur Erfüllung der Anfragen auf den jeweiligen Datenbank- bzw. Speichersystemen durch. Da die Operationen auf einzelnen oder einer Teilmenge von Usern basieren, ist ein effizientes Filtern auf die entsprechenden IDs besonders wichtig. Dies kann je nach Datenbank bspw. durch Indizierung, Sortierung oder anderen Techniken wie bspw. Bloom Filtern sichergestellt werden. Generell gilt: je weniger personenbezogene Daten man besitzt, desto kleiner sind die entsprechenden Datensätze und desto weniger aufwendig ist es, spezifische personenbezogene Daten zu identifizieren. Aus diesem Grund ist es von zentraler Bedeutung, sparsam mit personenbezogenen Daten umzugehen, d. h. deren Inhalt auf das Nötigste zu reduzieren und eine automatische Löschung (z. B. durch Retention Policies und TTLs) zu implementieren.
Umsetzung von Löschanfragen
Löschanfragen können grundsätzlich durch Löschen oder durch Anonymisieren aller personenbezogenen Daten einer anfragenden Person erfüllt werden. Aus juristischer Perspektive ist eine Anonymisierung nicht mit einer Löschung personenbezogener Daten gleichzusetzen. In jedem Falle sollte man sich vor der Entscheidung für oder gegen eine Anonymisierung von personenbezogenen Daten Auskunft bei rechtskundigen Personen einholen und sich juristisch absichern. Entscheidet man sich dennoch für eine Anonymisierung, bspw. damit Daten weiterhin für Analysezwecke zur Verfügung stehen, ist es wichtig, dass nach einer erfolgten Anonymisierung unter keinen Umständen mehr auf die ursprünglichen Personen geschlossen werden kann.
Eine Anonymisierung ist deutlich aufwendiger und fehleranfälliger als das simple Löschen der betroffenen Daten. Zur Anonymisierung personenbezogener Attribute stehen verschiedene Möglichkeiten zur Verfügung: so könnte ein Name durch eine Hashfunktion verschlüsselt werden oder eine Postleitzahl auf ihre erste Ziffer trunkiert werden. Zur Erfüllung von Löschanfragen ist es daher besonders wichtig, dass die eingesetzten Datenbanken Delete und/oder Update-Operationen ermöglichen und transaktionssicher sind. Bei einigen Datenbanksystemen muss man zusätzlich nach der Durchführung der Löschanfrage sicherstellen, dass personenbezogene Daten nicht aus der Transaktionshistorie (z. B. durch Time Travelling) rekonstruiert werden können. Genauso müssen auch archivierte Daten und Backups zur Erfüllung von DSGVO-Anfragen berücksichtigt werden. Mehrere Löschanfragen können i. d. R. über einen kürzeren Zeitraum (bspw. einen Tag) gesammelt und anschließend gebündelt durchgeführt werden.
Umsetzung von Auskunftsanfragen
Auch bei Auskunftsanfragen müssen alle personenbezogenen Daten identifiziert werden. Anstatt zu löschen, werden diese jedoch je nach Szenario unverändert oder in aggregierter Form an den GDPR-Service zurückgesendet (im Diagramm nicht dargestellt). Bei kleinerem Umfang lassen sich die personenbezogenen Daten direkt oder über einen Message Broker an den GDPR Service senden. Bei größeren Datenmengen bietet es sich an, diese in komprimierter Form über eine temporäre URL für den GDPR Service abrufbar bereitzustellen. Auf AWS kann das bspw. durch Presigned URLs auf Objekten in S3 Buckets umgesetzt werden. Ab dem Eingang einer Auskunftsanfrage hat der Verantwortliche einige Tage Zeit, um auf diese zu antworten. Es bietet sich daher insb. aus Effizienz- und Kostengründen an, Auskunftsanfragen über eine gewisse Zeit zu sammeln, um diese anschließend gebündelt zu verarbeiten.
Was kann schon schiefgehen?
Bei der Entwicklung von Anwendungen fallen viele Probleme erst während des Betriebs auf. Es ist unmöglich, sämtliche potenzielle Fehlerquellen bereits vor der Produktivierung zu identifizieren und sie bei der Implementierung zu berücksichtigen. Genauso ist das natürlich auch bei der Entwicklung von DSGVO Lösungen. Im Folgenden sind daher einige Problemstellungen gesammelt, die in der Praxis auftreten können:
Nach der Durchführung der Löschanfrage eines Users kommen verspätet weitere Daten dieses Users ins System (Nachzügler)
Oft kann es durch verspätete Daten passieren, dass nach der Löschung noch Daten eintreffen, die eigentlich schon hätten gelöscht sein müssen. Auch durch das „Übersehen“ eines personenbezogenen Datensatzes kann es passieren, dass personenbezogene Daten, die eigentlich schon hätten gelöscht sein sollten, nachträglich noch gelöscht werden müssen. Damit dies auch im Nachhinein noch passieren kann, ist es wichtig, eine Löschanfrage nach ihrer ersten Erfüllung nicht als final abgeschlossen anzusehen, sondern auch bei künftigen Löschoperationen (zumindest über einen gewissen Zeitraum) weiterhin zu berücksichtigen. Um dies zu ermöglichen, können z. B. sämtliche Löschanfragen in einem dedizierten Datensatz gesammelt werden, sodass die gesamte Historie von Löschanfragen bei jeder Löschoperation berücksichtigt werden kann. Auf BigQuery oder ähnlichen relationalen Datenbanken kann man das z. B. durch ein MERGE INTO ... WHEN MATCHED THEN DELETE umsetzen.
Langlaufende Jobs auf großen Tabellen, die in Timeouts laufen oder parallel ausgeführt werden
Datensätze mit personenbezogenen Daten können auch trotz Berücksichtigung aller DSGVO Grundsätze (→ Datensparsamkeit) unter Umständen sehr groß sein. Das Auffinden spezifischer personenbezogener Daten kann dann sehr zeit- und rechenaufwendig sein. Die Optimierung der entsprechenden Operationen hängt sehr stark von der eingesetzten Speichertechnologie ab. Bei verteilten Speichersystemen hat man häufig die Möglichkeit, über Partitionierung, Clustering oder Indizierung Datenbankanfragen signifikant zu beschleunigen. Auch die Optimierung von JOIN-Operationen (gilt auch für MERGE INTO) kann die Laufzeit einer Datenbankabfrage erheblich beschleunigen. Auch ist es wichtig, den Ausführungsplan der Datenbankanfrage (meist über EXPLAIN) genau zu analysieren, darin die problematischen Stellen zu identifizieren und zielgerichtet zu optimieren. Oft können scheinbar kleine Umformulierungen der Datenbankabfrage stark positive Auswirkungen auf die Effizienz haben. Das letzte Mittel kann dann in einigen Szenarien noch sein, schlicht die Ressourcen (CPU, Memory) für die Ausführung der Abfrage zu erhöhen.
Sonstige Abbrüche durch temporäre Fehler (Verbindungsabbruch, Ressourcenengpass, etc.)
Es können jederzeit temporäre Fehler auftreten, die zum Abbruch der Durchführung von Lösch- oder Auskunftsanfragen führen können. Im schlimmsten Fall gerät die Datenbank nach dem Abbruch in einen inkonsistenten Stand. Diesen durch manuelle Eingriffe wieder in einen konsistenten Stand zu überführen, ist sehr zeitraubend und fehleranfällig. Dieses Szenario gilt es, gerade wenn es um personenbezogene Daten geht, unter allen Umständen zu verhindern. Transaktionssicherheit ist deswegen unverzichtbar. Doch selbst bei gegebener Transaktionssicherheit können unerwartete Szenarien auftreten, die zu Fehlern führen können, bspw. das bereits oben beschriebene Szenario mit verspäteten Daten. Durch Sicherstellung von Idempotenz und Wiederholbarkeit lassen sich viele derartige potenzielle Fehlerquellen ausschließen.


