
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Cloud Computing gewinnt durch sein flexibles Bereitstellungsmodell immer größere Bedeutung. Von Software (SaaS),Plattformen (PaaS) bis hin zur IT-Infrastruktur (IaaS) wird ein weites Spektrum an Diensten angeboten, die Unternehmen in der immer schneller werdenden Digitaler Transformation unterstützen sollen. Eine neue Sparte bildet Machine learning as a service (MLaaS), welches Unternehmen eine einfache Möglichkeit bietet Daten zu verarbeiten, Modelle zu trainieren und Prognosen zu erstellen. In diesem Artikel werden die Angebote von vier der größten Cloud Anbieter vorgestellt: Google Cloud Platform (GCP), Amazon Web Services (AWS), Microsoft Azure und IBM Cloud/Watson.
Angebotsübersicht
Cloud-basierte ML-Dienste lassen sich aktuell anhand ihrer technischen Anforderungen, der Stack-Tiefe und ihrer Usability in drei verschiedene Kategorien einordnen:
Plattformbasierte Dienste
| Amazon SageMaker | Google Cloud ML Engine | Azure ML Services | IBM Watson Studio | |
|---|---|---|---|---|
| Schnittstellen | CLI, REST, Jupyter Notebook | CLI, REST | CLI, Jupyter Notebook | CLI, Jupyter Notebook |
| SDKs | .NET, C++, Go,Java, JavaScript, PHP, Python, Ruby | C#, Go, Java, Node.js, PHP, Python,Ruby | Python | Python |
| Feat. Frameworks | Apache MXNet, XGBoost, TensorFlow, PyTorch, Chainer | scikit-learn, XGBoost, TensorFlow | Apache MXNet, scikit-learn, TensorFlow, PyTorch, CNTK | Spark MLlib, scikit-learn, XGBoost, TensorFlow, Keras, Caffe, PyTorch, IBM SPSS |
| Eigene Algorithmen | + | – | + | + |
Plattformbasierte Dienste bieten eine verwaltete Plattform für ML, mit der Entwickler möglichst schnell und einfach ihre eigenen Modelle trainieren und einsetzten können. Dabei stehen ihnen eine Auswahl an unterschiedlichen Frameworks und Algorithmen zur Verfügung. Durch die Abstraktion der Plattformschicht entfällt der Mehraufwand durch die Verwaltung eigener Hardware. Zusätzlich bietet eine Cloud-basierte Infrastruktur auch Vorteile in der Skalierbarkeit und Elastizität. Diese Dienste bieten die größte Flexibilität hinsichtlich Modellaufbau und Tests anhand unterschiedlicher Algorithmen.
Alle vier Dienste bieten ein Command-line Interface für ihre Plattformen an. Google und Amazon stellen zudem REST APIs zur Verfügung. AWS, Azure und IBM bieten zusätzlich noch den Zugriff über ein Jupyter Notebook an. Während Azure und IBM lediglich ein SDK für Python bereitstellen, unterstützen Google und AWS zahlreiche weitere Programmiersprachen. Alle Anbieter stellen durch ihre Frameworks und Algorithmen Lösungen für die gängigsten ML Problematiken (Regression, Klassifizierung) zur Verfügung und decken in der Hinsicht denselben Funktionsumfang ab. Es könnten jedoch zusätzliche sekundäre Faktoren wie z.B. Laufzeit, Framework Usability, o.Ä. eine wichtige Rolle in der Entscheidungsfindung spielen. Diese hängen jedoch nicht von der Plattform ab, sondern vom eingesetzten Framework.
Vortrainierte ML APIs
Neben den Plattformdiensten werden zahlreiche vortrainierte ML APIs angeboten, bei denen die Modelle bereits vortrainiert sind. Es werden für die Nutzung keine vorherigen ML Kenntnisse benötigt; man übergibt lediglich die eigenen Daten und erhält die von den oder SDKs. Durch die bereits vortrainierten und getesteten Modelle entfällt ein großer Modellen erzeugen Ergebnisse. Die Anbindung erfolgt meist über eine REST-Schnittstelle oder SDKs. Durch die bereits vortrainierten und getesteten Modelle entfällt ein großer Arbeitsaufwand, vor allem da keine eigenen Trainings- und Testdatensätze benötigt werden. Diese vortrainierten Dienste lassen sich zurzeit in drei größere Kategorien einteilen:
- Sprach- & Textanalyse
- Bildanalyse
- Sonstige Dienste
Sprach- & Textanalyse
Der Kernbereich der Sprach- und Textanalyse bildet das Natural Language Processing (NLP), das Maschinen ermöglicht, mit menschlicher Sprache zu interagieren. NLP besteht unter anderem aus Spracherkennung, Syntaxanalyse und Textgenerierung. Viele dieser Bereiche haben in den Vergangen Jahren deutliche Fortschritte gemacht, nicht zuletzt dank den Erfolgen im Deep Learning (Young et al. [2018]). In den meisten Fällen wird Spracherkennung zusammen mit NLP genutzt, um die Wünsche von Nutzern nachzuvollziehen. Die bekanntesten Beispiele dieser Technologie sind digitale Sprachassistenten wie Apples Siri oder Amazons Alexa.
| Funktion / Anbieter | AWS | GCP | Azure | Watson |
|---|---|---|---|---|
| speech to text | 2 | 119 | 30 | 9 |
| text to speech | 27 | 56 | 51 | 8 |
| language translator | 12 | 98 | 62 | 22 |
| language detection | 100 | 104 | 66 | 62 |
| topic extraction | X | X | X | X |
| entities extraction | X | X | X | X |
| keywords extraction | X | X | X | X |
| metadata extraction | X | |||
| relations analysis | X | X | ||
| syntax analysis | X | X | X | X |
| sentiment analysis | X | X | X | X |
| emotion analysis | X | |||
| personality analysis | X | |||
| tone analysis | X | |||
| voice verification | X | |||
| spell check | X | |||
| Total | 9 | 9 | 13 | 14 |
Amazon
Amazon bietet für alle sprach- und textrelevanten Aufgaben vier unterschiedliche APIs an, jede mit einem bestimmten Aufgabenbereich. Amazon Transcribe dient zur Spracherkennung. Die dabei erzeugten Audiodateien können dann zur weiteren Analyse verwendet werden. Ein naheliegender Anwendungsfall wäre die Auswertung von Kundentelefonaten. Transcribe unterstützt Englisch und Spanisch. Amazon Polly bietet die Möglichkeit zur Sprachsynthese. Dabei wird ein bestehender Text mit einer möglichst menschenähnlichen computergenerierten Stimme wiedergegeben. Dies ist vor allem hilfreich bei Vorlesegeräten für Sehbehinderte. Polly unterstützt 27 verschiedene Sprachen und bietet für einige Sprachen mehrere Stimmvarianten an. Zur Textanalyse wird Amazon Comprehend angeboten. Comprehend ist ein NLP Dienst und bietet unterschiedliche Analysetools an, um in Texten neue Einsichten und Zusammenhänge zu finden. Aktuell bietet Comprehend folgende Funktionen:
- Schlüsselphrasenextraktion
- Stimmungsanalyse, um die allgemeine Stimmung eines Texts (positiv, negativ, neutral oder gemischt) wiederzugeben
- Syntaxanalyse, mit der man Text in Tokens unterteilen kann, um so Wortgrenzenund Bezeichnungen wie Substantive und Adjektive im Text zu erkennen
- Entitätenerkennung (Erkennung von Namen, Orten, Unternehmen, etc.)
- Erkennung von 100 Sprachen
Amazon Translate übersetzt Text aus dem Englischen oder ins Englische. Dabei werden 12 Sprachen unterstützt.
Google bietet mit Cloud Speech-to-Text ebenfalls einen Spracherkennungsdienst an. Dabei werden insgesamt 119 Sprachen und Dialekte unterstützt. Für die Sprachsynthese steht Cloud Text-to-Speech zur Verfügung. Dieser Dienst unterstützt 56 verschiedene Sprachen/Dialekte. Darunter sind besondere WaveNet-Stimmen, die laut Google (van den Oord et al. [2016]) gegenüber anderen Sprachsynthesetechnologien von Menschen als authentischer wahrgenommen werden. WaveNet erzeugt für die Synthese komplett neue Audiodateien mithilfe eines neuronalen Netzes, welches auf realistische Tonfolgen und Sprachwellen trainiert ist. Diese Technologie wird auch beim Google Assistant und Googles Übersetzungsdienst verwendet. Cloud Natural Language ist das NLP-Pendant zu Amazon Comprehend und bietet dieselben Funktionalitäten. Mit Cloud Translation bietet Google eine Möglichkeit, den bekannten Google-Translate-Übersetzungsdienst in eigene Anwendungen zu integrieren. Dabei liegt Google mit 104 unterstützten Sprachen klar vor der Konkurrenz, wobei hier keine Aussage zur Übersetzungsqualität mit einbezogen wird. Bei Cloud Translation können zudem alle Sprachen auch untereinander übersetzt werden.
Azure
Microsoft bietet ebenfalls sprachrelevante Schnittstellen an, die einen Teilbereich der sogenannten Cognitive Services bilden, in denen Microsoft seine KI-Dienste zusammenfasst. Unter der Speech API befinden sich Dienste für Text-to-Speech (51 Sprachen/Dialekte, tlw. mehrere Stimmen zu Auswahl) oder Speech-to-Text (30 Sprachen). Die Translator Speech API kombiniert diese beiden Dienste zusammen mit einer Übersetzungsfunktion und bietet damit Speech-to-Speech oder Speech-to-Text Übersetzungen an. Azure stellt zudem eine Speaker Recognition API zur Verfügung, über die Personen anhand ihrer Stimmen identifiziert und verifiziert werden können. Unter den Language APIs findet man die Analyse- und Übersetzungs-Tools von Azure. Text Analytics bietet NLP für Schlüsselphrasenextraktion, Stimmungsanalyse, Entitätenerkennung, Beziehungsanalyse zwischen Wörtern/Phrasen und unterstützt die Erkennung von 120 Sprachen. Über die Linguistic Analysis API ist zudem Tokenisierung möglich. Die Übersetzungs-API Translator Text unterstützt 65 Sprachen. Azure bietet außerdem als einziger Service Rechtschreib- und Grammatikprüfung über die Bing Spell Check API an.
IBM
IBMs Speech-to-Text Service unterstützt neun Sprachen und mit der Text-to-Speech API können acht verschiedene Sprachen wiedergegeben werden. Der Language Translator Service bietet die Möglichkeit, 21 Sprachen zu übersetzten. Natural Language Understanding analysiert Texte nach Schlüsselwörtern, Entitäten, Relationen und Stimmung und erkennt 62 Sprachen. Der Dienst unterstützt zudem weitere Funktionen, die bei der Konkurrenz nicht verfügbar sind. So können zusätzliche Metadaten extrahiert werden oder zu den gefundenen Schlüsselwörtern und Entitäten verbundene Emotionen abgefragt werden. Womit sich IBM außerdem von der Konkurrenz abhebt sind die Personality Insights und Tone Analyzer Services. Mit Personality Insights können komplexere Persönlichkeitsprofile für Autor:innen der übergebenen Texte erstellt werden. Diese Profile geben unter anderem Einsicht in Charaktereigenschaften, mögliche Bedürfnisse und Tendenzen zum Konsumverhalten (z.B. bevorzugte Filmgenres). Der Tone Analyzer untersucht den Sprachton (analytisch, zuversichtlich, zurückhaltend) und Emotionen eines Textes.
Bildanalyse
In den vergangen Jahren gab es immense Fortschritte in der maschinellen Bildbearbeitung. Heutzutage können mit Smartphones in Echtzeit Objekte vor der Kamera erkannt und Kategorisiert werden (Redmon [2017]). Ein Großteil dieses Erfolges ist den Convolutional Neural Networks (CNN) zuzuschreiben, welche vor allem in der Gesichtserkennung eine wichtige Rolle spielen (Matsugu et al. [2003]). Bei einem Vergleich aller bekannten Bilderkennungsalgorithmen erreichten CNNs die geringste Fehlerquoten (Ciresan et al. [2012]). Cloudbasierte Services bieten eine leicht zugängliche Schnittstelle, um die Leistung vortrainierter Netze in eigene Anwendungen zu integrieren. Primär geht es bei den Bildanalysediensten um die Objekt- und Gesichtserkennung. Beide Funktionen werden von allen vier Anbietern zur Verfügung gestellt. Bei erkannten Gesichtern kann zudem bei allen Anbietern die relative Position im Bild bestimmt werden (Bounding Box).
| Funktion / Anbieter | AWS | GCP | Azure | Watson |
|---|---|---|---|---|
| age | X | X | X | |
| facial hair | X | X | ||
| face bounding box | X | X | X | X |
| celebrity | X | X | ||
| emotion | X | X | X | |
| glasses | X | X | ||
| eyes open | X | |||
| gender | X | X | X | |
| landmarks | X | X | X | |
| mouth open | X | |||
| pose | X | X | ||
| picture quality | X | X | X | |
| smile | X | X | ||
| hair | X | |||
| accessories | X | X | ||
| makeup | X | |||
| text/OCR | X | X | X | |
| labels/objects | X | X | X | X |
| logo | X | |||
| Total | 15 | 8 | 16 | 4 |
Amazon
Amazon Rekognition bietet den zweitgrößten Funktionsumfang bei der Bildanalyse. Neben Objekten und Gesichtern unterstützt Rekognition Texterkennung (Optical character recognition). Erkannte Gesichter können unter anderem auf Alter, Geschlecht, Emotionen, und Haltung untersucht werden. Zudem kann abgefragt werden, ob es sich bei der erkannten Person um eine prominente Persönlichkeit handelt. Bei Rekognition können Gesichter mit IDs versehen werden, um so eine Datenbank von bereits analysierten Personen aufzubauen. Dadurch können bekannte Personen auf neuen Bildern wiedererkannt werden. Ähnliche Gesichter auf verschiedenen Bildern können auch direkt miteinander verglichen werden, um zu prüfen, ob es sich um dieselbe Person handelt. Darüber hinaus bietet Rekognition die Möglichkeit, Videos auf Gesichter/Personen/Persönlichkeiten, Objekte und explizite Inhalte zu untersuchen.
Googles Vision API bietet einen deutlich geringeren Funktionsumfang. Zwar können neben Objekten und Gesichtern zusätzlich Text und Logos erkannt werden, jedoch ist eine detaillierte Analyse eines erkannten Gesichtes nicht möglich. Mit der Video Intelligence API können Videos auf Objekte, Film-Einstellungen und explizite Inhalte untersucht werden.
Azure
Azure unterstützt mit der Computer Vision und der Face API die meisten Features. Neben OCR bietet Azure eine detaillierte Gesichtsanalyse, bei der sogar die Haare und das Makeup untersucht werden können. Zudem besteht wie bei Rekognition die Option, bereits analysierte Gesichter/Personen zu speichern und verwalten. Im Gegensatz zu Amazon und Google bietet Azure jedoch keine integrierte Videoanalyse.
IBM
Watson Visual Recognition bietet den geringsten Funktionsumfang. Neben der Objekt- und Gesichtserkennung besteht lediglich die Möglichkeit, erkannte Personen auf das Alter und Geschlecht zu analysieren. Eine Videoanalyse ist nicht verfügbar.
Sonstige Services
Neben Bild- und Textanalyse gibt es noch andere ML APIs, die für spezielle Aufgabenbereiche bestimmt sind. So vereinfachen Azure Bot Service, Amazon Lex und Watson Assistant die Erstellung von Bots, die für die Interaktion mit Menschen bestimmt sind. Mit den Azure Search APIs können Anwendungen die Suchfunktionen von Bing integrieren, inklusive Bild/Videosuche und Autovervollständigung. Google bietet mit Cloud Talent Solution eine verbesserte Suche für Jobbörsen und optimiert zudem das Einstellungsverfahren für Unternehmen.
(Semi-)Automatisierte Dienste
| Amazon ML | Google AutoML | Azure ML Studio | IBM Watson Studio | |
|---|---|---|---|---|
| Regression | + | + | + | |
| Binary Classification | + | + | + | |
| Multiclass Classification | + | + | + | |
| Clustering | + | |||
| Anomly Detection | + | |||
| Recommendation | + | |||
| Statistical Functions | + | |||
| NLP | + | + | ||
| Computer Vision | + | + |
Die letzte Kategorie der ML Services bilden die (semi-)automatisierten Dienste. Diese sollen den Aufbau von eigenen Modellen stark vereinfachen bzw. vollständig automatisieren. Man übergibt die eigenen Trainingsdaten und die Dienste wählen dann die passenden Algorithmen aus, um die Modelle zu trainieren. Amazon und IBM bietet dabei höchste Automatisierung an. Man wählt lediglich das gewünschte Verfahren (Regression, Binary/Multiclass Classification) und den Rest übernimmt der Dienst. IBM unterstützt zusätzlich einen manuellen Modus, bei dem 12 Algorithmen zur Auswahl stehen. Azure Machine Learning Studio stellt die meisten Funktionen zu Verfügung. Neben Regression und Klassifizierung können noch weitere Problemstellungen angegangen werden, wie z.B. Clustering oder Anomalieerkennung. Insgesamt stehen über 30 verschiedene Algorithmen zur Auswahl. Zusätzlich besteht noch die Möglichkeit zur Datenexploration und -vorverarbeitung. Google bot mit der Cloud Prediction API ebenfalls eine automatisierte Lösung für Regression und Klassifizierung an, stellte diese aber am 30. April 2018 ein. Mit Cloud AutoML ermöglicht Google seit Neuestem das automatische Trainieren von Modellen zur Bild- und Textanalyse. Für AutoML Vision stellt Google sogar ein internes Team zur Verfügung, das die kundenspezifischen ungekennzeichneten Bilder nach den Instruktionen des Kunden kategorisiert, um diese für das Training weiterzuverwenden.
Evaluierung der Bild- und Sprachanalysedienste
Um die Dienste der vier Anbieter in den Kategorien der Bild- und Sprachanalyse miteinander zu vergleichen, wurde jeweils ein Test für die Kategorie entwickelt.
Bildanalyse
Für die Bildanalyse wurde geprüft, wie gut die Dienste menschliche Gesichter in Bildern erkennen. Hierfür wurde ein Testdatensatz mit Bildern aus dem Labeled Faces in the Wild Datensatz und des Caltech 101 Datensatzes zusammengestellt. Die Bilder wurden anschließen von den jeweiligen Diensten der Anbieter analysiert.
Die Bewertung basiert auf der entstanden Wahrheitsmatrix, welche festhält, ob die Bilder korrekt klassifiziert wurden oder nicht. Die verwendeten Metriken sind Accuracy, Precision und Recall.
| AWS | Azure | GCP | IBM | |
|---|---|---|---|---|
| TP | 198 | 197 | 198 | 197 |
| FP | 1 | 0 | 0 | 4 |
| TN | 99 | 100 | 100 | 96 |
| FN | 0 | 1 | 0 | 1 |
Google liegt bei allen Bewertungskriterien vorne und hat als einziger Anbieter alle Bilder korrekt kategorisiert. Amazon und Azure liegen bei der Accuracy gleichauf, jedoch bietet Azures Modell eine höhere Precision, das von Amazon hingegen einen höheren Recall. Azure ist daher eher für Anwendungsfälle geeignet, bei denen es wichtig ist, dass positiv annotierte Bilder auch tatsächlich ein menschliches Gesicht enthalten; Amazon dagegen bei Anwendungen, die möglichst viele Bilder mit Gesicht erkennen soll. Das Modell von IBM annotierte die Bilder am häufigsten falsch und findet sich so an letzter Stelle.
| AWS | Azure | GCP | IBM | |
|---|---|---|---|---|
| Accuracy | 0.996 | 0.996 | 1 | 0.983 |
| Precision | 0.994 | 1 | 1 | 0.98 |
| Recall | 1 | 0.994 | 1 | 0.994 |
Sprachanalyse
Bei der Sprachanalyse wurde untersucht, wie gut die Dienste in der Sentimentbestimmung sind. Hierfür wurde ein anonymisierter Datensatz eines E-Commerce Shops für Frauenkleidung genutzt. Die 5000 verwendeten Produktbewertungen bestehen unter anderem aus einer eindeutigen Bewertungs-ID, einer Produktbewertung von eins (negativ) bis fünf (positiv) und einer optionalen, englischsprachigen Rezension. Für den Test wurden zunächst alle Bewertungen ohne Rezension entfernt. Anschließend wurden alle Bewertungen mit einer Rezensionslänge von unter 15 Zeichen entfernt, da diese aufgrund der Kürze nicht vom IBM-Dienst analysiert werden können.
Die Rezensionen wurden jeweils alle von den Cloud-Diensten nach ihrem Sentiment untersucht. Google und IBM bewerten anhand eines Wertes zwischen -1 (negatives Sentiment) und 1 (positives Sentiment). Bei Azure liegt der Wert zwischen 0 (negativ) und 1 (positiv). AWS bewertet das Sentiment lediglich anhand von Strings: POSITIVE, NEGATIVE, NEUTRAL und MIXED. Durch die Unterschiedlichen Skalen der Anbieter fällt ein direkter Vergleich des Sentiments pro Bewertung schwer. Damit alle vier Anbieter methodisch bewertet werden können, wurde daher das Problem auf eine binäre Klassifizierung reduziert. Die Bewertungen wurden in zwei Kategorien unterteilt: alle Bewertungen < 3 gelten als negativ, alle Bewertungen > 3 als positiv. Produktbewertungen von 3 werden für die Sentiment Bewertung nicht berücksichtigt. Die Sentiment Werte bei IBM und Google werden bei <0 als negativ und bei >0 als positiv eingestuft. Bei Azure sind alle Werte <0.5 negativ und >0.5 positiv. Für AWS gelten die Label NEGATIVE entsprechend als negative und POSITIVE als positive Bewertung.
Um einen ersten Einblick in die Resultate der Sentiment-Analyse zu gewinnen, wurden für Google, IBM und Azure Violin-Plots erstellt. Diese zeigen die Verteilung der Sentiment-Werte auf die jeweilige Produkt-Bewertung. Bei der Erstellung der Plots fiel auf, dass bei den Analysen von Google teilweise die Sentiment-Bewertungen fehlten. Die Rezensionen wurden jedoch fehlerfrei analysiert, lediglich die Bewertung wurde nicht zurückgegeben.

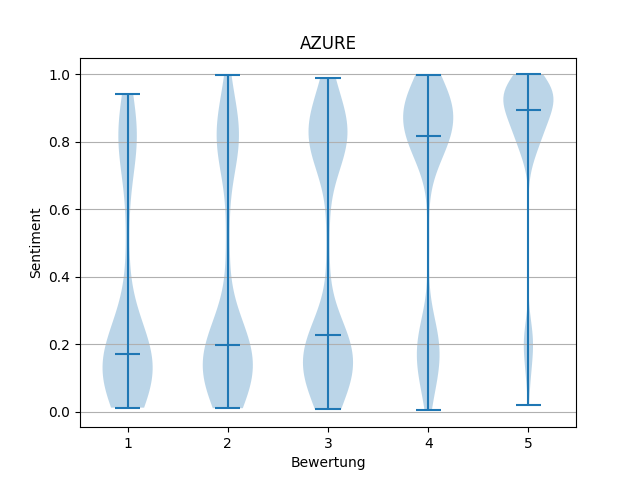

Bei der Betrachtung der Violin-Plots fällt auf, dass sowohl Azure als auch IBM bei fast allen Bewertungen Ausreißer über die jeweils gesamten Skalen aufzeigen, was auf eine sehr große Unsicherheit in der Beurteilung hindeutet. Bei Azure sind zudem kaum Bewertungen im Mittelbereich der Skala (um 0.5) zu finden, das Modell tendiert eher zu extremen Werten. Bei Googles Ergebnissen kann man anhand der Verteilung einen verhältnismäßigen Anstieg des Sentiment-Wertes zur Produktbewertung erkennen, so wie man ihn erwarten würde. Wenn man jedoch die Durchschnittswerte über alle Bewertungen hinweg betrachtet, fällt auf, dass lediglich ein Bruchteil der möglichen Skala genutzt wird (ca. -0.25 bis 0.5). Dadurch ist das Modell bei seinen Bewertungen nicht so Aussagekräftig wie bei anderen Anbietern.
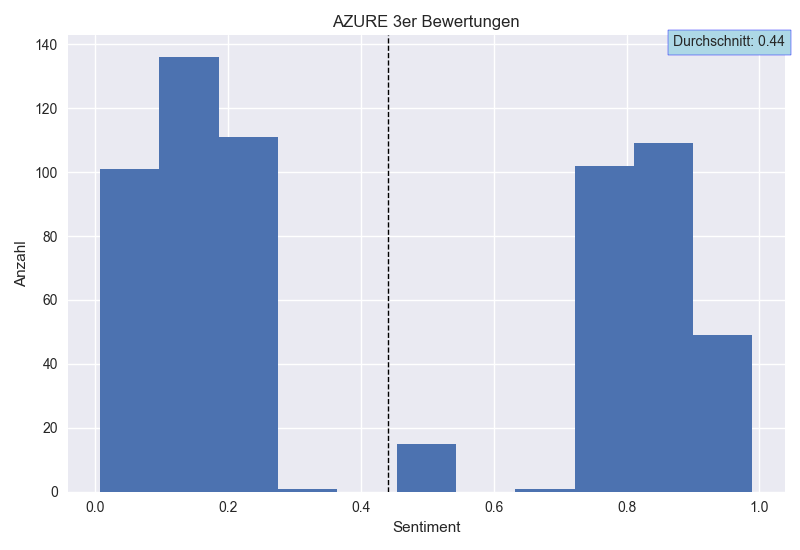
Neben den Violin-Plots wurden für die drei Anbieter Histogramme erstellt, welche die Sentiment Verteilungen für die Rezensionen mit einer Bewertung von 3 zeigen. Alle drei Anbieter liegen hier mit ihrer Durchschnittsbewertung dort, wo man es anhand ihrer Skalen für die 3er-Bewertungen erwarten würde: Azure Mitte 0.5, ø 0.44; IBM Mitte 0, ø 0.03; GCP Mitte 0, ø -0.06. Jedoch weist lediglich Google eine Normalverteilung für diese Bewertungen auf. Bei Azure und IBM liegt der Durchschnitt zwar im erwarteten Bereich, jedoch ergibt sich dieser durch das Mittel an zu negativ oder zu positiv Bewerteten Rezensionen. Vor allem bei Azure fällt auf, wie wenige der 3er-Rezensionen im Mittel der Skala liegen. IBM und Azure eignen sich daher nicht für Textanalysen mit neutralem/gemischtem Sentiment.


Zur Einsicht der AWS-Ergebnisse wurde ein Säulendiagramm erstellt, das die Verteilung der Labels auf die jeweiligen Produktbewertungen zeigt. Dabei ist gut zu sehen, dass das Modell bei den 1er- und 5er-Rezensionen das Sentiment richtig eingestuft hat. Jedoch zeigt auch das AWS-Modell Schwächen bei gemischten/neutralen Rezensionen. Von den gut 600 3er-Rezensionen wurde jeweils über ein Drittel als positiv und negativ kategorisiert.

Um die Analysen nun nach ihrer Accuracy bewerten zu können, wurde zunächst eine Liste aller relevanten Bewertungen zusammengestellt. Von den ursprünglich 5000 Bewertungen wurden zunächst alle 604 Bewertungen entfernt, die keinen Sentiment-Wert von Google erhalten haben. Danach wurden die übrig gebliebenen 449 3er-Bewertungen gestrichen. Damit bleiben für die Endauswertung 3947 Bewertungen. Mithilfe der vorher festgelegten Kategorien zur positiv/negativ-Klassifizierung wurden anschließend die richtigen und falschen Prognosen der Dienste gezählt und anhand dieser Werte die Accuracy der Modelle errechnet.
| AWS | Azure | GCP | IBM | |
|---|---|---|---|---|
| Richtig | 3620 | 3273 | 3752 | 3513 |
| Falsch | 327 | 674 | 195 | 434 |
| Accuracy | 0.917 | 0.829 | 0.95 | 0.89 |
Dabei erzielte Googles Dienst mit 95% Accuracy den höchsten Wert und kann demnach am besten beurteilen, ob ein Text ein positives oder negatives Sentiment aufweist. Darauf folgen AWS und IBM, welche mit 91,7% bzw. 89% dicht beieinander liegen. Das Modell von Azure hat mit 82,9% Accuracy am schlechtesten abgeschnitten. Wenn man dazu berücksichtigt, dass Azure zusätzlich bei neutralem/gemischtem Sentiment große Probleme bei der Beurteilung hat, schneidet Azure bei der Qualität der Sentiment-Analyse insgesamt am schlechtesten ab.
Ausblick
Man kann davon ausgehen, dass cloudbasierte MLaaS und generell ML-Dienste auch in Zukunft an Funktionalität und Qualität gewinnen werden. Laut einer Studie der Infoholic Research LLP [2017] soll der MLaaS Markt im Prognosezeitraum 2017-2023 um 49% wachsen. Ein potenzieller Einsatzbereich für MLaaS ist das Internet of Things (IoT). Dieses soll sich laut Gartner bis 2020 aus über 20 Mrd. Geräten (ausgenommen PCs, Tablets und Smartphones) zusammensetzen. Und da die meisten Cloud Provider bereits spezielle Dienste für das IoT anbieten, die sich leicht mit anderen Cloud-Diensten integrieren lassen, könnte MLaaS eine Schlüsselrolle in diesem Bereich einnehmen.
Weiterlesen
Mehr Informationen zu Machine Learning und Cloud Services gibt es auf unserer Website. Wir sind außerdem immer auf der Suche nach neuen KollegInnen, die sich mit diesen und anderen aktuellen Technologiethemen auseinandersetzen möchten!



One thought on “MLaaS: Maschinelles Lernen in der Cloud”