Notice:
This post is older than 5 years – the content might be outdated.
tl;dr: This blog post summarizes my masters‘ thesis. I use state-of-the-art NLP techniques to improve an existing pricing model in an online car market. Online car markets usually use structured/technical car attributes to forecast a market price. For example, car price prediction may be based on „model, make and its horse power“. Besides these technical attributes, the sellers of cars add additional vehicle description texts to provide more details about their automobile. In my thesis, I use these texts to improve the existing pricing model, presuming that additional information is contained in them.
Motivation
Texts written in natural language are an unstructured data source that is hard for machines to understand. The amount of text in the world wide web is growing every minute. User-generated texts are created within seconds, as the following figure shows. For example, users publish approximately 470.000 tweets on Twitter every minute and Reddit receives 1.944 user-generated comments in a minute.

To deal with these huge numbers of unstructured data, automated text analysis is crucial. Natural Language Processing (NLP) is the part of the field of artificial intelligence that makes natural language texts comprehensible for machines. Social networks are by far not the only platforms to which users contribute textual data. For example, B2C and C2C marketplaces offer their users the opportunity to write product reviews and communicate their experiences. Marketplaces such as ebay.com, amazon.com or alibaba.com, want to gain more insights into customers’ willingness to pay and thus product pricing strategies. In these online marketplaces, products are usually presented by images, attributes in a tabular form and unstructured description texts. For example, marketplaces use these product data and combine it with user-interaction data to create recommendation systems.
At times, attributes of products are used to predict market prices. To know exact market prices is useful when dealing with more expensive products that require a high investment, such as cars or houses. Online car markets provide a platform where sellers can present their cars also by images, structured attributes and texts. Due to the individuality of cars it is even difficult for car experts to predict an accurate market price. To overcome this challenge and to help prospective buyers, online car markets, such as mobile, pkw, cars and autotrader, apply pricing models to provide neutral market price estimates. These pricing models predict car market prices based on cars‘ structured attributes that were set by the seller. Because car prices often depend on cars‘ individual conditions and configuration, sellers add user-generated vehicle description texts to provide additional information about them. For better price differentiation, these texts are an important information source to provide more price transparency and price distinctiveness.
Prognosis of Price Residuals by using Vehicle Description Texts
To incorporate these texts into price modelling, NLP provides techniques for their automated analysis. In my master’s thesis, I evaluate whether user-generated product description texts can improve price forecasting on car market prices by using state-of-the-art NLP-methods. To test this, I predict price residuals that indicate the difference between a market price calculated by an existing pricing model based on structured attributes and the actual sales price of a car. The following figure depicts my approach in more detail. Let us assume that the blue car is about to be sold on an online car market platform. The seller sets different technical attributes, uploads images and sets a selling price. Furthermore, a text is added to provide more details about the car.
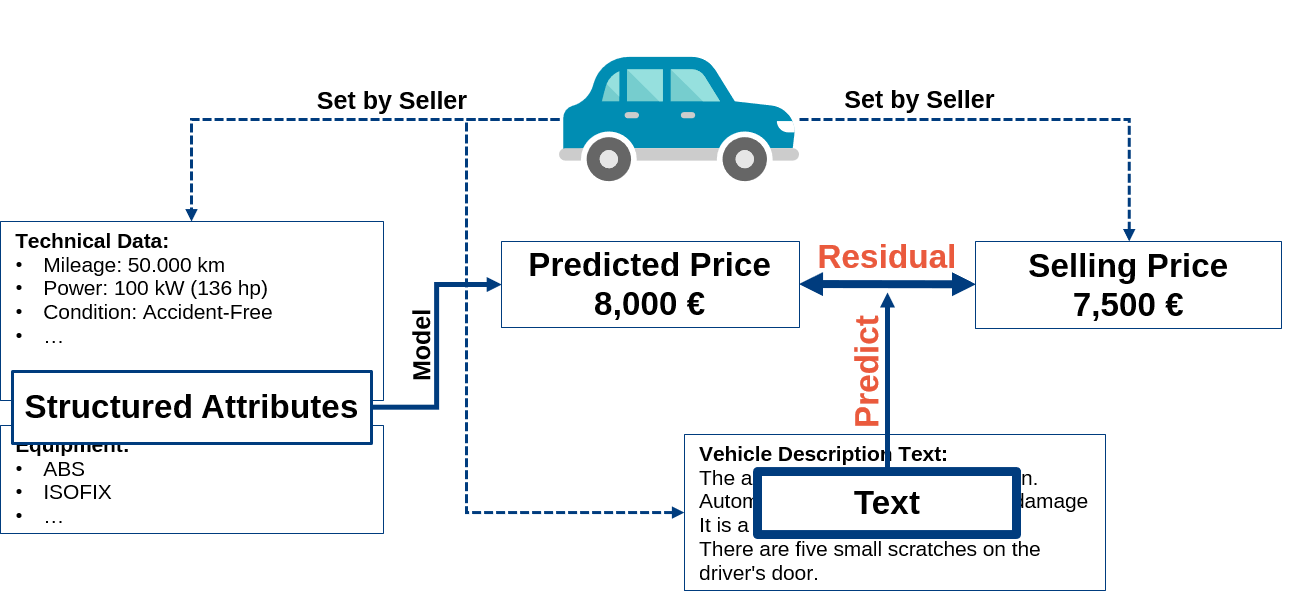
The figure illustrates that the predicted market price based on structured attributes is 500€ above the selling price. If the text contains additional information, it may explain this price difference. For example, the car could have some scratches, which would explain a decreased selling price. The cost of actually repainting the damaged car parts could be 500€. To compare price residuals across absolute car prices, I relativize the price residuals. Thus, I use the following target variable for prediction, which is called relative Price Residual (\(PR_{rel}\)):
\(\displaystyle PR_{rel} = \frac{price_{predicted}-price_{sold}}{price_{predicted}}\)
The prediction of \(PR_{rel}\) using vehicle description texts makes it is possible to incorporate them into price forecasting. To test if an improvement could be achieved on real data, I extract a data set from an online car market whose description texts are written in German. Three features are gathered for every car: sales price, predicted price and vehicle description text.
Using CRISP-DM to apply different Machine Learning Models
To structure the whole project, I use the Cross-industry standard process for data mining (cf. Shearer, C. (2000) The CRISP-DM Model: The New Blueprint for Data Mining. Journal of Data Warehousing, 5, 13-22). I split my approach into four parts: data understanding, data preparation, modeling and evaluation, such as depicted in the figure below.

First analysis of the data provides the insight that the vehicle description texts are rather short and do have an average text length of approximately 20 words. Furthermore, the texts also differ in their structure. Some texts contain only lists and others are written in continuous texts. Because the analysis of product descriptions to predict a business variable—such as forecasting a price—is sparsely treated in literature, my research focuses on text classification. In text classification, a target class for a text is predicted, which is similar to the forecast of price residuals. In the data preparation phase, I use different word preprocessing techniques, such as stop word removal and lemmatization. Furthermore, I test word embeddings and vector space models to create meaningful word representations that are comprehensible for machines. In the modeling phase, different Artificial Neural Networks (ANNs) and Random Forest are used to forecast \(PR_{rel}\) for each text. Furthermore, I read a subset of the texts myself and predict the price residual (Human-Based-Prediction).
Classyifing Vehicle Description Texts into Three Equiprobable Classes
Because it is rather hard to predict an exact price residual for every text, I transform the actual regression task into a classification task. This makes it easier to analyze the sentiment and the general statement of the texts. The texts can justify a higher or lower selling price than the market price based on the structured attributes indicated. Also, they might have no influence on the selling price at all. Thus, the data set is divided into three equally distributed classes: underpredicted, neutral and overpredicted. The split is done according the relative price residual, meaning that one third of the texts is in each class, as the following figure shows. Furthermore, predicting the \(PR_{rel}\) classes makes it possible to use accuracy as evaluation measure, which makes it easy to compare the different algorithms.

Preprocessing the Data
Data preprocessing is one of the most important steps when analyzing natural language texts. At first it is necessary to transform all texts into lists of tokens. I use a customized tokenizer from spaCy for this task, because the vehicle description texts contain special characters that the normal tokenizer can not handle properly. For adding customized rules to a spaCy tokinzer object, I recommend reading this post from Daniel Longest.
After tokenizing the texts, stop word removal is the next step in word preprocessing, which reduces the overall vocabulary. spaCy or NLTK provide stop word lists for different languages. Stop word removal has to be used with care, because stop words can change the whole meaning of a statement. For example, the sentence „the car has no scratches“ means the opposite if the word „no“ is removed. Therefore I test whether stop word removal increases the prediction of price residuals or not.
After stop word removal, I apply lemmatization to the words to further reduce the overall vocabulary in the texts. For lemmatiztion, I use the spaCy lemmatizer that also provides lemmatization for different languages.
After these steps, I lowercase all words and transform them into machine readable formats. I test different word and document inputs, such as word embeddings and vector space model (term frequency and tf-idf). The use of the actual input depends on the method used in the modeling phase. I train different kind of word embeddings, such as word2vec, GloVe and fastText. I train these embeddings on 3.7 Million vehicle description texts that were extracted separately from an online car market. Furthermore, I evaluate which embedding model is best suited for my approach. Embeddings represent words in continuous vectors and include semantic information. Usually, the vectors do have a dimension of 300. To illustrate the idea behind word embeddings, the following figure shows a t-distributed stochastic neighbor embedding (t-SNE) visualization of word vectors that were trained with the word2vec approach. The t-SNE visualization maps the high dimensional word vectors into a 2 dimensional space.

It illustrates the ten most similar words for the German word „neu“ (new/green). Words such as „neuwertig“ (as good as new) and nagelneu (brand-new) do have similar semantic information and are used in the same contexts as the word „neu“. The red cluster depicts the ten most similar words to the German word „beule“ (bump). „Schramme“ (scratch) or „delle“ (dent) are similar here. Thus, words that have a similar meaning and similar semantic information do also have a similar word vector. This illustrates the strength of word embeddings and is useful when price information is extracted from texts.
Applying Machine Learning Models
To predict the \(PR_{rel}\) classes for each text, I test 4 different machine learning models: Random Forest, Feed Forward Neural Network (FNN), Long short-term memory (LSTM) and an LSTM with an attention mechanism. This blog post from Sebastian Blank covers the basic theory about Deep Learning and simple and advanced ANNs. To train the machine learning models, I use 80% (train set) of data and evaluate the models on 20% (test set). In addition, I optimize hyperparameters for each algorithm by implementing a grid search. Besides machine learning, I also do a human-based prediction based on 360 texts to provide a baseline.
Attention-LSTM
Before I present the results of the different approaches, I will shortly explain the architecture of my Attention-LSTM, because this is the most complex model and it represents current state-of-the-art in NLP (cf. Pryzant et al., Predicting Sales from the Language of Product Descriptions (2017)). The attention mechanism helps to set the focus on the important words of a sequence. Each vehicle description text is represented by a list of words. I use the word embeddings hat were created in the data preparation phase for every word in a text. These word embeddings are sequentially fed into a LSTM-Cell, which calculates a hidden state for each word in a vehicle description text. Afterwards an attention network, which is an FNN with no hidden layer that has a softmax activation on top, calculates so called attention weights for every hidden LSTM-state. Each weight is multiplied with its corresponding hidden state. All products are then summed up to create one context state. This context state represents the whole document and is passed on to an FNN, which predicts the class for the text. The following figure shows the architecture in more detail.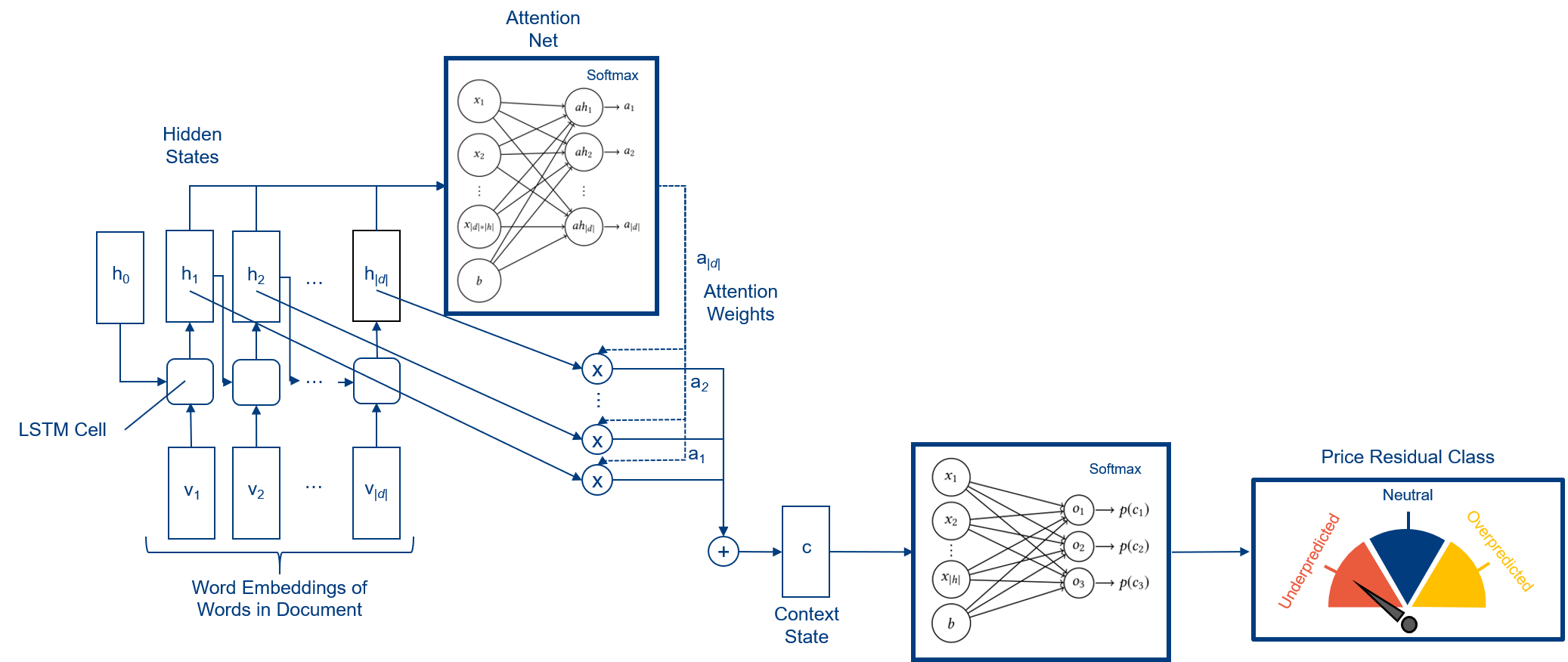
Results
The results of each model are shown in the following table. Furthermore, the best input methods and word preprocessing techniques for each algorithm are depicted in the table. Randomly classifying the texts into \(PR_{rel}\) classes would lead to an accuracy of 33.3%. The most accurate machine learning model is an FNN that uses a vector space model with term frequency as input. Furthermore, I use lemmatization and no stop word removal to achieve an accuracy of 45.78%. The Attention-LSTM performs slightly worse. The embeddings created by word2vec are best suited for my approach. The LSTM and Attention-LSTM achieve the highest accuracy with this embedding model. Compared to randomly classifying the texts, the machine learning models perform quite good. The FNN is 12.48 percentage points better than randomly classifying the texts and 4.22 percentage points below the accuracy of a human.
| Model | Accuracy on Test Set | Best Input Representation, Word Preprocessing |
|---|---|---|
| Human: | 50.00 % (approx.) | unprocessed |
| Feed-Forward Neural Network: | 45.78% | term Frequency, lemmatized |
| Attention-LSTM: | 45.47% | word2vec |
| Long Short-Term Memory Network: | 44.98% | word2vec |
| Random Forest: | 43.22% | tf-idf, lemmatized |
| Random: | 33.33% | - |
Accuracy of 45%: Does Prediction work at all?
Because a prediction accuracy of 45% seems to be low, one might deem it impossible to improve price prediction by using vehicle description texts. To test this, I use a reduced feature model to predict the market prices (pricepredicted). The reduced feature model is trained on less structured attributes, e.g. horse power and millage are left out to forecast a market price for a car. Therefore, the market prices are less accurate. Because the vehicle description texts also include information similar to the structured attributes, it should be possible to predict the \(PR_{rel}\) classes more precisely when they are computed by the reduced feature model rather than calculated by the full feature model. The full feature model forecasts the car prices (pricepredicted) on all structured attributes. Due to the fact that the FNN performs best, I train it on \(PR_{rel}\) classes computed by the full (red) and reduced (blue) feature model. The following figure shows the result for this task. It depicts the accuracy on the test set for every training epoch of the FNN.
The accuracy of the FNN is higher when the reduced feature model is used. Therefore, it is possible to improve price prediction by incorporating the vehicle description texts. The prediction of the \(PR_{rel}\) classes is approximately 1% more accurate for the reduced model. It is only a marginal improvement and the structured attributes already contain a lot of the price relevant information.
Conclusion
The last paragraph showed that it is possible to improve price prediction in online car markets by analyzing vehicle description texts. But only a small improvement can be achieved. As the human-based prediction shows it is difficult for a human to forecast the correct \(PR_{rel}\) classes from vehicle description texts. The vehicle description texts in online car marketplaces are very short (20 words on average) and do often not contain any additional price information. Most price information is already contained in the structured attributes. Probably the analysis of the associated car images could offer the opportunity to improve forecasting.
Nevertheless, a trend can be obtained by analyzing the description texts with NLP. The best ML-model is only 4.22 percentage points below the accuracy of a human.
Read on
Find our experience and offerings in deep learning on our website. If you’re looking for new challenges, you might want to consider joining us!


