
In an operating system an efficient scheduler can jump between tasks in nanoseconds. But as the title says that is not always necessary. Today, instead, we will take a look at how to design very slow schedulers for infrequent tasks which are planned days, weeks, months or even years in advance. We will borrow concepts from operating system schedulers and adapt them to the serverless world to efficiently schedule AWS Lambda invocations ahead of time.
Motivation
But why would we ever want to do that? Well, imagine building a large-scale content-driven platform like Netflix, YouTube or Amazon Prime Video. A very important part of providing content on platforms like these is content management. And at least when it comes to media, managing the publishing and un-publishing of content specifically plays a big role. This is either due to license agreements with the rights holders of the content or (in the case of YouTube for example) because you want to allow your content-providing users to plan when to publish their videos.
This is one of the use cases where a solution similar to the one in this article comes into play. Another use case would be larger e-commerce applications, where a scheduler like this allows you to automatically apply discounts to specific products or to provide other limited-time offers.
Finally, let’s assume we want to do all of this on a somewhat classical AWS Serverless Stack. This may not be the case in most systems as large as the ones mentioned above. But it’s a viable option for many small or medium sized platforms with an MVP spirit that still need access to these features.
Tech Stack
Throughout the article and in the proposed solution, we reference or use the following services provided by AWS:
- Lambda
- EventBridge / Cloudwatch Events
- DynamoDB
- Cloudwatch (just for logging)
If you don’t know what they do, I recommend checking out their respective documentations. In order to keep this article short, I will not go into too much detail about them and assume a basic understanding of how they work.
The demo applications are written in Golang. Go is an excellent choice for serverless due to very good SDK and runtime support by AWS, easy deployments and extremely fast startup times. However, the concepts I describe here should be easily applicable to any system using the aforementioned AWS tools and could even be adapted to fit a slightly different tech stack or implementations of other cloud providers.
Even if your tech stack is exactly the same, you should view this article only as a starting point. There are still minor inconveniences, bugs, and at least one or two glaring oversights compromises that needed to be made, which is why the implementation is a proof of concept more than anything else.
Solution Overview
So let’s see how our scheduler works. We will go into detail about the individual components and why they are built the way they are in the next section, but let’s first create a rough overview. It helps to visualize the scheduler as four basic components:
- A Cloudwatch rule triggers our Lambda function. It is more or less the heart of the scheduler, so let’s call a Lambda invocation a scheduler tick.
- Our worker process runs as a Lambda function.
- We have a DynamoDB table that is (mis-)used as a task priority queue.
- The task editor provides CRUD functionality for the task queue.
The following diagram illustrates the relationship between these components:
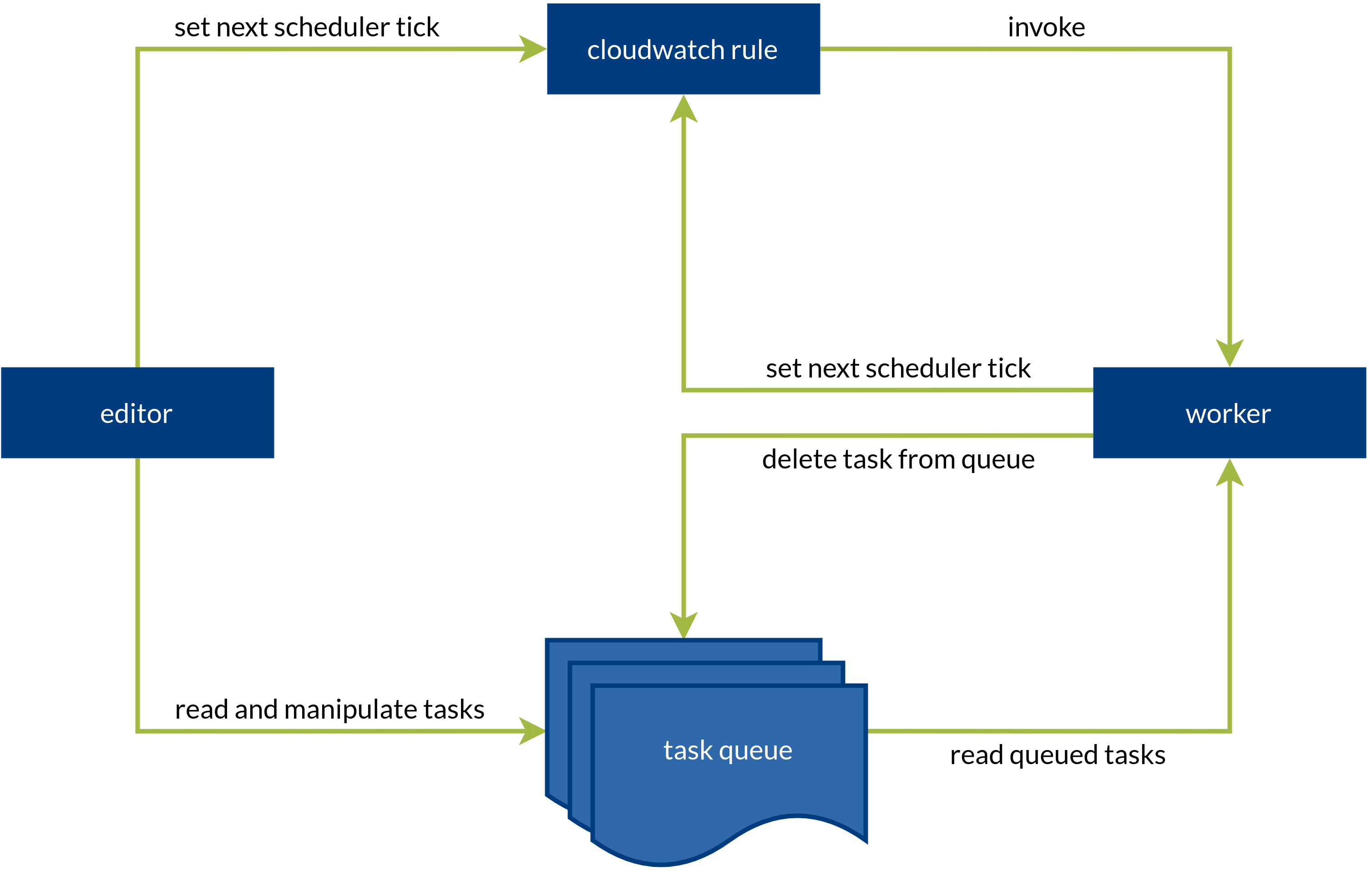
An entrypoint to the system is the submission of a new task using the editor. If the task queue was previously empty or the new task is due before all other tasks, the editor also sets the next scheduler tick to the due date of the new task by transforming it into a cron-like expression and saving that in the rule. The Cloudwatch rule, which has previously been set up to invoke the worker lambda, then triggers at the specified time.
The worker reads all tasks from the queue and processes only those that are due at the time of execution. Finally, it sets the next scheduler tick to the due date of the first item that is not due yet, if there are any items left. If there aren’t, it preferably sets the scheduler tick to the epoch, 1970-01-01T00:00Z. (If anyone working on the AWS team is reading this, thank you for making it possible to not only set individual years, but also past dates as schedule expressions.) This way we can be sure that the scheduler triggered and that there are no scheduled tasks at the moment just by looking at our Cloudwatch rule. We could possibly enable or disable the rule on demand instead, but in a more complex system, disabling a rule could have a different semantic meaning.
A Detailed Look
With our solution draft completed, let’s dive into the most important aspects of the implementation. All following code snippets are taken from the POC implementation on github. The whole source code for all components resides in a single repository to keep everything nice and compact. We will start with the editor, continue with the worker and finally go into detail on the remaining components and take a short look at the AWS infrastructure we need.
The Editor
The main task of the editor is to interact with both the queue and the Cloudwatch rule to manage existing tasks and the creation of new tasks. In the provided implementation, the editor is not actually executed within AWS. Instead, it uses a set of credentials to authenticate as a client and provides a minimalistic HTTP API locally. The reasoning behind this is that in practice, the relevant parts of its code should be integrated into whichever service needs access to the task scheduling feature. Hiding the functionality behind an HTTP API in your production systems not only imposes an additional communication overhead, but also introduces a boundary along technical concerns instead of functional ones, which is usually regarded as outdated (for many good reasons).
So let’s focus on the key concepts here: The task data model, manipulating the task queue and setting the next scheduler tick.
Data Model
Written as JSON, our data model looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "id": "task_123", "due": "2020-10-02T00:00:00Z", "action": "APPLY_SALE", "payload": { "itemID": "item_xyz", "newPrice": 29.99, "salePercent": 50 } } |
The ID is needed internally for DynamoDB, the relevant fields are due , action and payload . In the code and within DynamoDB, the capitalization of the fields is slightly different only for practical reasons. The date (and time) when the task is to be processed is written as an ISO-8601 date. Go’s json package (and the DynamoDB client we’re using) will automatically parse this into the correct usable data type. The action field identifies what to do in this task and the payload field contains additional parameters that are needed later for the worker to do its job.
Task Queue Manipulation (DynamoDB)
To keep this article as short as possible, let’s only look at the example of adding a task here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
func isFirstTask(task scheduling.Task, allTasks []scheduling.Task) bool { for _, existing := range allTasks { if existing.Due.Unix() < task.Due.Unix() { return false } } return true } func (s Service) AddTask(task scheduling.Task) error { // get all tasks or return error tasks, err := s.repo.GetTasks() if err != nil { return err } // schedule task if new task is the first one to be executed if isFirstTask(task, tasks) { err = s.scheduler.Schedule(task.Due) // return error if scheduling fails if err != nil { return err } } // add new task to queue return s.repo.AddTask(task) } |
When adding a new task, we first read all the remaining tasks from our DynamoDB Table using the repository and see if the new task’s due date is earlier than that of any other task. I disregarded task queue performance for the sake of simplicity in this demo, but ideally, we would use another product than DynamoDB or do some bookkeeping, so we wouldn’t have to scan the whole table every time we want to add a new task.
The repository implementation is quite simple, thanks to this DynamoDB client.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
func (r TaskRepository) GetTasks() ([]Task, error) { var out []Task err := r.table. Scan(). All(&out) return out, err } func (r TaskRepository) AddTask(task Task) error { return r.table. Put(task). Run() } |
The table object on the repository is obtained by calling .Table("table-name") on the dynamo client instance during repository initialization. We don’t really need to do anything here other than just wiring up the correct table and SDK functions. The attribute mappings are done via struct tags on the Go type:
|
1 2 3 4 5 6 7 8 9 10 11 |
type Task struct { ID string `dynamo:"ID" json:"id"` Due time.Time `dynamo:"Due" json:"due"` Action string `dynamo:"Action" json:"action"` Payload map[string]interface{} `dynamo:"Payload" json:"payload"` } |
Setting the scheduler ticks (EventBridge)
Let’s focus on the Cloudwatch rule manipulation next. Let’s assume we have created a rule that triggers our worker lambda on a schedule. I used terraform for this, but more on that later. We can use the cloudwatchevents package from the official Go SDK to manipulate rules. But since that is a bit uncomfortable, let’s create a small wrapper around it. This also enables us to test our AddTask() method above more easily (which is what we would do if this wasn’t a simple demo).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
type Scheduler struct { ruleName string cw *cloudwatchevents.CloudWatchEvents } func Client(ruleName string) Scheduler { return Scheduler{ ruleName: ruleName, cw: cloudwatchevents.New(session.Must(session.NewSession())), } } // Schedule creates a scheduler tick at the specified time t. // It takes the year, month, day, hour and minutes fields into account. // Cloudwatch will execute the worker lambda function at that time. func (client Scheduler) Schedule(t time.Time) error { schedule := fmt.Sprintf("cron(%s)", onlyAt(t)) input := cloudwatchevents.PutRuleInput{ Name: aws.String(client.ruleName), ScheduleExpression: aws.String(schedule), State: aws.String(cloudwatchevents.RuleStateEnabled), } _, err := client.cw.PutRule(&input) return err } |
We define a type that holds the client instance. Since we only ever manipulate one rule, it can hold the rule name as well. The type provides a Schedule() method that translates a given date into a cron-like expression (which is used within EventBridge) and modify the existing rule using the PutRule() method from the SDK.
The interesting part is the behaviour of PutRule(): It will overwrite the schedule expression and the rule state, but leave the invocation target (our worker lambda) intact. In the SDK, invocation targets are managed via the PutTargets() method.
The Worker
In our example, we use a monorepo approach and build the worker binary from the same source as the editor. It uses the same Cloudwatch and DynamoDB client implementations we have already seen, and it only requires some additional functionality. The additional methods can be looked up in the source, but let’s focus on the interesting parts for the sake of brevity.
Processing Tasks Workflow
The general workflow of our task processor is the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
type processor struct { upTo time.Time items ItemService tasks scheduling.TaskRepository scheduler cloudwatch.Scheduler } func (p processor) processTasks() error { // retrieve all tasks tasks, err := p.tasks.GetTasks() if err != nil { return err } // sort tasks by due date sort.Slice(tasks, func(i, j int) bool { return tasks[i].Due.Unix() < tasks[j].Due.Unix() }) // process tasks for _, task := range tasks { // see if task is due if task.Due.Unix() > p.upTo.Unix() { // if it isn't, schedule it and exit return p.scheduler.Schedule(task.Due) } // if it is, process it err = p.processTask(task) if err != nil { // log processing errors for single tasks fmt.Println("error processing task ", task.ID, ": ", err) continue } // delete task from task queue err = p.tasks.Done(task) } // if all queued tasks have been processed, disable scheduler return p.scheduler.Unschedule() } |
The processor type contains a date (and time) up to which it needs to process the tasks. Usually, this would just be time.Now() , but the abstraction is there for testing purposes. It also contains instances of the clients we talked about before. In this demo, there is also an ItemService which can put items on sale. Technically it can’t even do that, it’s just a façade that logs the task data. But it exemplifies how tasks are processed and how we can separate the different concerns within the worker.
The processTasks() method is executed by the main function after the processor is instantiated. It first obtains a list of tasks (sorted by their due date) which it then iterates over. We pass every due task to the processTask() method, which we will look at in a bit. After processing them, we check them off by simply deleting them from the table using the Done() repository method. Once we encounter the first task that is not due yet, we set the next scheduler tick to its due date and exit. If we run out of tasks, we set the scheduler to the epoch as explained in the beginning before exiting.
Executing task actions
In order to process a task, we switch on its Action field to find out what it actually is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
func (p processor) processTask(t scheduling.Task) error { switch t.Action { case "APPLY_SALE": var a SaleAction err := mapstructure.Decode(t.Payload, &a) if err != nil { return err } p.items.ApplySale(a) return nil default: return fmt.Errorf("I don't know the action type %s\n", t.Action) } } |
Once we identify what should be done, we decode the previously unknown content of Payload using this useful library. Finally, we can use the obtained payload to call the corresponding service, which executes the action. In this case, all the knowledge needed to process a specific type of task is contained within the worker. Alternatively, we could generate an event or call another service at this point.
Infrastructure
There are three main AWS resources we need: our worker Lambda function, the DynamoDB table containing the tasks and the Cloudwatch rule. For the demo, terraform was the tool of choice to create and manage them. The whole infrastructure code can be found here. We will not look at everything in detail in an effort to keep this article as short and concise as possible. Feel free to check out the repository and see how everything comes together.
DynamoDB
For the task queue, we use a quite basic DynamoDB Table without a range key or indexes as a simple way to persist our task data. However, the implementation in the repository can easily be adjusted to fit any form of persistence available inside and outside of AWS. DynamoDB is meant for fast reads and writes of semi-structured data. Our tasks are indeed semi-structured but the access pattern of our application is very different from what DynamoDB is optimized for. Looking at other options is definitely recommended if you plan to store large amounts of tasks.
Cloudwatch Rule
The Cloudwatch rule is set up to invoke the Lambda, which can easily be achieved via the UI or terraform. It should be noted that using terraform in the way we do it here is not ideal: every time a new deployment is made using terraform apply, it changes the rule’s schedule to cron(* * 1 1 ? 1970) again. You can circumvent this by creating a separate terraform deployment, using the PutTargets SDK Function or by just creating the rule manually in the AWS console and linking it to your lambda once that is deployed.
EventBridge Limits
That aside, there is one more thing to say about the rule. You might wonder why we’re only using one rule. Couldn’t we just create a new Cloudwatch rule for every task that should be executed in the future? The definite answer to this is: “It depends“. There are hard limits to the amount of rules per AWS account. Every rule belongs to an event bus. It doesn’t matter whether it actually triggers on events or at specific times defined by a cron expression. At the time of writing, one event bus is limited to 300 Rules and there is a maximum of 100 Event Buses per Account. While that puts the absolute limit at 30,000 planned tasks, it introduces the complexity of managing multiple event buses after the first 300 rules. And this is assuming we don’t need Cloudwatch rules for anything else. If the absolute number of planned tasks is guaranteed to stay below 300, using a Cloudwatch rule for every task seems like a good alternative. But the actual task itself needs to be stored somewhere anyway, so the additional investment to implement this solution is comparatively small. Considering this, the use case of this scheduler is somewhere in the middle of where it’s worthwile running one or more workers 24/7 and where the implementation may not fully be worth the additional effort because there are very few scheduled tasks at a given time.
Parting Words
As stated before, this proof of concept merely provides a starting point for your own implementation. But the article shows the feasibility of the presented “single-rule“ invocation scheduling approach and includes valuable reflections on key concepts in a solution like this.
There is an interesting article on the AWS Database Blog on how to implement a priority queue within the DynamoDB tables related to the domain. It should be possible to combine those concepts with this scheduler implementation. This way, we can keep domain boundaries intact and perhaps improve task queue performance.
Another way to tackle the problem of technical service boundaries could be to publish the tasks as events once they are due instead of processing them within the worker lambda. We would need more than one Cloudwatch rule for that, but that approach would still scale very well.
With a Key/Value database like DynamoDB, totally different approaches to implement the same features are also valid. If we take the “putting items on sale“ use case as an example, we could simply attach the task payload to the item itself, combined with the time where the item should be on sale. So instead of actively changing data in our database, we calculate everything in somewhat of an event sourcing approach. This strategy doesn’t play well together with indexes though and adds the possibility to increase overall complexity.


