
Im Rahmen des Forschungsprojekts KOSMoS entwickelt inovex zusammen mit acht Projektpartnern eine Plattform für die unternehmensübergreifende Vernetzung von Produktions- und Prozessdaten zur Integration neuer Datenprodukte und Geschäftsmodelle. Eine technologische Fragestellung stellt die Wahl einer geeigneten Zeitreihen-Datenbank dar, die es erlaubt, hochfrequente Maschinendaten effizient zu speichern und für analytische Zwecke einfach verfügbar zu machen, dar. In diesem Artikel diskutieren wir unsere Erfahrungen mit den zwei populären Open-Source-Zeitreihen-Datenbanken TimescaleDB und InfluxDB.
Warum die Evaluation?
In Zeiten von Industrie 4.0, Industrial Internet of Things (IIoT) und Künstlicher Intelligenz werden Zeitreihendaten in zunehmend größeren Mengen erhoben. Die Verarbeitung dieser Daten kann Maschinenbauer:innenn und -betreiber:innen unter anderem dabei helfen, ihre Maschinen durch eine bedarfsgerechte Wartung und intelligente Betriebsmittelüberwachung länger im optimalen Bereich zu nutzen.
Neben positiven Aspekten, die die Erhebung der Daten mit sich bringt, werden auch neue Herausforderungen geschaffen. Wohin mit den Daten? Wie können die Daten verfügbar gemacht werden? Wer darf auf welche Daten zugreifen? Klassische Datenverwaltungssysteme, wie relationale Datenbanken, stoßen mit Blick auf Leistung, Verlässlichkeit und Anpassungsfähigkeit im Zusammenhang mit Zeitreihen schnell an ihre Grenzen. Wiederkehrende Aufgaben, wie das Schreiben von größeren Batches oder das Abfragen von Werten über einen längeren Zeitraum, mit zusätzlichen Restriktionen an die zeitliche Komponente, können im Verlust von Daten oder langen Antwortzeiten des Systems resultieren. Zeitreihen-Datenbanken sind hingegen speziell auf die effiziente Speicherung, Verarbeitung und Analyse von Zeitreihen ausgelegt.
Im Rahmen des Forschungsprojekts KOSMoS entwickeln wir als Teil eines Konsortiums eine Plattform für eine unternehmensübergreifende Vernetzung von Produktions- und Prozessdaten. Eine Herausforderung besteht in der Wahl einer geeigneten Zeitreihen-Datenbank, die es erlaubt, hochfrequente Maschinendaten effizient zu speichern und für analytische Zwecke einfach verfügbar zu machen. Um eine sinnvolle Auswahl treffen zu können, bieten Kriterien wie Beliebtheit oder Verbreitung zwar einen ersten Anhaltspunkt – für eine Entscheidung ist aber ein Vergleich der funktionalen und nicht-funktionalen Merkmale der Systeme notwendig. Daher haben wir uns exemplarisch die beiden quelloffenen Datenbankmanagementsysteme TimescaleDB und InfluxDB im Detail angesehen, die sehr unterschiedliche Lösungskonzepte implementieren.
Evaluation der funktionalen Merkmale
TimescaleDB ist eine Erweiterung (Plugin) der relationalen Datenbank PostgreSQL. Sie nutzt sogenannte Hypertables – eine abstrakte Sicht auf mehrere Tabellen – und speichert mit Hilfe dieser die Zeitreihen sowohl zeitlich als auch nach Merkmalen segmentiert ab. InfluxDB ist hingegen eine komplette Neuentwicklung mit dem ausschließlichen Ziel des Speicherns von Zeitreihen. Durch ihren Aufbau ist sie nur bedingt für das Speichern von anderen, nicht zeitbezogenen Werten geeignet. Vergleicht man die funktionalen Merkmale der beiden Datenbanken miteinander (siehe Tabelle 1) fallen für unseren Anwendungsfall drei wesentliche Unterschiede auf – das zugrundeliegende Datenmodell, der Umfang an unterstützten Datentypen und die zur Verfügung stehenden Datenmanipulationssprachen.
Relationale Datenmodellierung vs. Tag-Sets
Der relationale Ansatz der PostgresQL wurde für die Datenstrukturen der TimescaleDB beibehalten. Wie in Abbildung 1 skizziert werden die Zeitreihendaten in Tabellen abgespeichert. Die zugehörigen Meta-Informationen der Zeitreihen werden über einen Schlüssel zugeordnet – angedeutet durch den Pfeil in Abbildung 1 – jedoch nicht direkt in der Tabelle mit den Messwerten abgelegt.


Datentypen
Beide Datenbanksysteme unterstützen die Datentypen String, Float, Integer und Boolean. Das ist für die meisten Fälle ausreichend, wie beispielsweise bei der Erfassung von Temperaturwerten (Float), Zählern (Integer), Zuständen (Boolean) und Status-Updates (Strings). TimescaleDB unterstützt darüber hinaus viele weitere komplexe Datentypen und ermöglicht dadurch beispielsweise eine flexible Ablage von Datenstrukturen, selbst wenn diese nicht vollständig bekannt sind, etwa JSON Dateien ohne ein bekanntes Schema. Eine gezielte Verarbeitung oder Analyse dieser Daten kann zu einem späteren Zeitpunkt erfolgen.
| TimescaleDB | influxDB | |
|---|---|---|
| Abfragesprachen | SQL | influxQL und Flux |
| Besonderheiten bei den Abfragesprachen | klassisches SQL (wichtig: "SORT BY time") | erweiterte Funktionen, wie DERIVATIVE, DIFFERENCE, MOVING_AVERAGE, ... |
| Datentypen | Integer Float String Boolean Timestamp, date, time … AND arrays, JSON blobs, geospatial dimensions, currencies, binary data and customized data types | Integer Float String Boolean |
| Auflösung Zeitstempel | Mikrosekunden | Nanosekunden |
| Implementierungssprache | C | Go |
| Zugriffskonzepte [3] | ADO.NET JDBC native C library ODBC streaming API for large objects | HTTP API JSON over UDP |
Tabelle 1: Auswahl von funktionalen Merkmalen der influxDB und TimescaleDB
Abfragesprachen
Auf die Erhebung von Zeitreihendaten folgt in der Regel auch deren Auswertung. Für diese Aufgabe sind zwei wichtige Faktoren zu berücksichtigen – die Mächtigkeit der Abfragesprache und die Abfragezeit. Für den geplanten Einsatz muss bewertet werden, wie wichtig die Mächtigkeit der mitgelieferten Abfragesprache des Systems ist. Reicht der Funktionsumfang der Sprache SQL aus, da die meisten Analysen in weitere Programme (Machine Learning Modelle, Analyse-Skripte, etc.) ausgelagert werden? Oder sollen Analysen möglichst ohne weitere Programme durchgeführt werden? Für diesen Fall liefert die InfluxDB mit ihrer eigenen Abfragesprache Flux den Anwender:innen einen mächtigen Werkzeugkasten mit zahlreichen bereits vorimplementierten Funktionen. Deutlich wird dieser größere Funktionsumfang unter anderem bei dem Vergleich der Komplexität von umfangreichen Abfragen – siehe identische Beispielabfragen für Flux und SQL unten. Anzumerken ist aber auch, dass die Verwendung von Flux möglicherweise gerade zum Einstieg einen gewissen Lernaufwand mit sich bringt, da die Syntax der Sprache meistens erst erlernt werden muss. Auch oder gerade für Nutzer:innen, die versiert in der Nutzung von SQL sind.
|
1 2 3 4 5 6 7 |
from(db:"telegraf") |> range(start:-1h) |> filter(fn: (r) => r._measurement == "foo") |> exponentialMovingAverage(size:-10s) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
select id, temp, avg(temp) over (partition by group_nr order by time_read) as rolling_avg from ( select id, temp, time_read, interval_group, id - row_number() over (partition by interval_group order by time_read) as group_nr from ( select id, time_read, 'epoch'::timestamp + '900 seconds'::interval * (extract(epoch from time_read)::int4 / 900) as interval_group, temp from readings ) t1 ) t2 order by time_read; |
Evaluation der nicht-funktionalen Merkmale
Bei der Wahl einer geeigneten Datenbank spielen nicht nur die funktionalen Merkmale eine Rolle. Auch Kriterien, wie die Performance beim Schreiben und Lesen von Daten, der Bedarf an Ressourcen und die generelle Verlässlichkeit müssten in eine Entscheidung einfließen. Dazu haben wir einige Tests durchgeführt.
Schreiben von Daten
Um verschiedene, beliebig komplexe Testszenarien für die Datenspeicherung abzubilden, generiert ein Skript in unserer Testumgebung eine Sequenz von Zufallszahlen. Variierbar sind die Anzahl erzeugter Werte, die Komplexität der Meta-Informationen und der Abstand zwischen zwei Zeitpunkten. Ein Testszenario ist wie folgt aufgebaut:
Es gibt eine Produktionshalle, ausgestattet mit zwei Werkzeugmaschinen.
Jede dieser Werkzeugmaschinen enthält fünf Sensorboxen.
Von jeder Sensorbox werden in einem zeitlichen Abstand von einer Sekunde drei Messwerte erfasst (Temperatur, Zähler und Luftfeuchtigkeit).
Die Tabelle 2 enthält exemplarische Zeitreihen-Daten einer Werkzeugmaschine:
| Zeitpunkt | MaschinenID | SensorboxID | Temperatur | Zähler | Luftfeuchtigkeit |
|---|---|---|---|---|---|
| 01/04/20 10:00:00 | 1 | 1 | 20.0 | 1 | 0.22 |
| 01/04/20 10:00:00 | 1 | 2 | 21.3 | 1 | 0.23 |
| ... | |||||
| 01/04/20 10:00:01 | 1 | 1 | 20.5 | 2 | 0.22 |
| 01/04/20 10:00:01 | 1 | 2 | 20.9 | 2 | 0.23 |
| ... |
Tabelle 2: Beispiel für erzeugte Zeitreihen-Daten einer Werkzeugmaschine inklusive der Meta-Informationen.
Dieses Szenario haben wir insgesamt in 5 Durchläufen simuliert und dabei den Speicherbedarf für 100.000, 200.000, 500.000, 750.000 und 1.000.000 Einträge (Zeilen) bestimmt. Die Ergebnisse des Speicherbedarfs sind in Abbildung 3 gegenübergestellt.
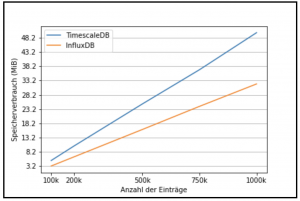
Es wird deutlich, dass die TimescaleDB im Schnitt mehr Speicher als die influxDB verbraucht – im beschriebenen Testszenario immerhin durchschnittlich 57% mehr.
Neben dem Speicherbedarf ist auch die zur Verfügung stehende Rechenleistung der eingesetzten Hardware ein weiteres Kriterium für die Wahl eines geeigneten Datenbank-Managementsystems. Im Bereich Industrie 4.0 können die Ressourcen von einem leistungsstarken Cluster in der Cloud bis hin zu einem einfachen Industrial Edge Device variieren. Während der Durchführung des obigen Testszenarios hat sich gezeigt, dass die TimescaleDB teilweise bis zu 50% weniger Arbeitsspeicher verwendet und hierdurch – zumindest während unserer Tests – bezüglich Out-of-Memory-Fehlern beobachtbar weniger anfällig ist. Natürlich können die entsprechenden Ressourcen einfach erhöht und dieses Kriterium somit unnötig gemacht werden. Besteht aber eine wie zuvor erwähnte Limitierung der Rechenleistung, muss dieses Kriterium unbedingt in die Auswahl einer Datenbank mit einfließen.
Lesen von Daten
Wie bereits im Abschnitt funktionale Merkmale beschrieben, sollten die Abfragesprachen die Anforderungen an die Mächtigkeit des Sprachumfangs erfüllen – abgeleitet vom jeweiligen Anwendungszweck. Als weiteres Kriterium spielt die Abfragezeit eine große Rolle. Wie lange braucht beispielsweise die Datenbank um eine Tabelle vom Umfang \(N\) mit bestimmter Komplexität \(K\) zu aggregieren? Um die beiden Datenbank-Managementsysteme in diesem Punkt zu testen, haben wir aufbauend auf den erzeugten Daten aus dem vorherigen Testszenario zwei exemplarische Abfragen geschrieben. Die erste Abfrage liefert die durchschnittlichen Messwerte für alle Maschinen ID und Sensor ID Tupel über den gesamten Erfassungszeitraum. Die zweite Abfrage baut auf der ersten Abfrage auf und ist um ein Clustering in fünf Minuten Intervalle erweitert. Der Vergleich der gemessenen Abfragezeiten von TimescaleDB und InfluxDB hat gezeigt, dass sich diese im Durchschnitt nicht bemerkbar voneinander unterscheiden.

Zusammenfassung
Betrachten wir noch einmal die gesamte Evaluierung, können wir zusammenfassend sagen:
Flexibilität
- Für das einfache Ablegen von (zeitabhängigen) Messreihen ist die InfluxDB eine einfache Möglichkeit, ohne hohen Aufwand für ein relationales Design.
- Fallen aber neben den einfachen Messreihen komplexere Daten und Meta-Informationen an, sollte für eine bessere Strukturierung zu einer Lösung wie der TimescaleDB gegriffen werden.
Abfragesprachen
- InfluxDB bietet hier durch die Abfragesprache Flux ein mächtiges Werkzeug für Abfragen. Jedoch ist der mögliche Mehraufwand für das Lernen der Sprache zu berücksichtigen.
- Anders bei der TimescaleDB. Diese kommt mit der klassischen Sprache SQL, welche vielen Entwickler:innen und Data Scientists bekannt ist und dadurch einen schnellen Einstieg ermöglicht. Der Sprachumfang wird durch spezifische Funktionen für die Analyse von Zeitreihen ergänzt.
Arbeitsspeicher, Datenspeicher und Performance
- TimescaleDB verbraucht im Vergleich zu InfluxDB weniger Arbeitsspeicher. Hierdurch ist auch ein Einsatz auf schwächeren Geräten (Edge-Devices, Embedded Systems, …) möglich.
- TimescaleDB verbraucht gegenüber InfluxDB in den Test im Durchschnitt 57% mehr Datenspeicher.
- InfluxDB und TimescaleDB unterscheiden sich zeitlich bei der Durchführung von Abfragen nicht merklich.
Die Inhalte dieser Arbeit stammen aus dem Projekt KOSMoS – Kollaborative Smart Contracting Plattform für digitale Wertschöpfungsnetze. Dieses Forschungs- und Entwicklungsprojekt wird mit Mitteln des Bundesministeriums für Bildung und Forschung (BMBF) im Programm „Innovationen für die Produktion, Dienstleistung und Arbeit von morgen“ (Förderkennzeichen 02P17D026) gefördert und vom Projektträger Karlsruhe (PTKA) betreut. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt bei den Autor:innen.
Quellen
[1] https://blog.timescale.com/blog/timescaledb-vs-influxdb-for-time-series-data-timescale-influx-sql-nosql-36489299877/, aufgerufen am 29.7.2020
[2] https://blog.timescale.com/blog/sql-vs-flux-influxdb-query-language-time-series-database-290977a01a8a/, aufgerufen am 29.7.2020
[3] https://db-engines.com/de/system/InfluxDB%3BTimescaleDB, aufgerufen am 29.7.2020


