
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Was nicht passt wird passend gemacht! Das dachten sich vermutlich die Entwickler:innen von Prefect, als die Idee für ihr Projekt entstand. Es will sich als eine Art Weiterentwicklung des Workflow-Management und Orchestrierungs-Tools Apache Airflow verstanden wissen. Ein Upgrade, das die Unzulänglichkeiten von Airflow ausmerzt und dadurch besser auf die sich ständig erweiternden Anforderungen der Data Engineering Branche zugeschnitten ist. Auf der offiziellen Webseite betitelt man sich bereits als „The Global Leader of Dataflow Automation“. Dass das ganz der Wahrheit entspricht darf bezweifelt werden, zumal Prefect sich noch in der Entwicklungsphase befindet. Trotzdem lohnt es sich sich mal reinzuschauen, denn hier steckt ohne Zweifel mehr dahinter als ein bloßer Airflow-Klon im neuen Gewand.
Prefect ist in zwei Teile untergegliedert: Prefect Core, die open-source Einheit und Kern des Tools, sprich die Automatisierungs- und Scheduling-Engine sowie das kostenpflichtige Upgrade Prefect Cloud. Dieses bietet zusätzlich die Orchestrierung von Workflows und Logs in der Cloud sowie eine Web-basierte UI für das Monitoring der Workflows, ähnlich wie man es von Airflow kennt.
Prefect Core
Wie eingangs erwähnt ist Prefect mit der Intention entstanden, die Schwachstellen von Airflow aufzugreifen und in eigene Stärken umzuwandeln. Aus dieser Idee heraus bringt Prefect einige interessante Aspekte mit sich, von denen wir uns die Wichtigsten anschauen werden. Bevor es aber losgeht, muss Prefect installiert werden. Für die Code-Beispiele sind außerdem folgende Imports notwendig:
|
1 2 3 4 5 6 7 8 9 10 11 |
from prefect import task, Flow, Client from prefect.schedules import Schedule from prefect.schedules.clocks import IntervalClock from prefect.environments.storage import Docker from prefect.environments import DaskKubernetesEnvironment from datetime import timedelta, datetime |
Tasks
In Prefect wird jeder Teilschritt eines Workflows als Task bezeichnet, vergleichbar mit einem Operator in Airflow. Um eine Python-Funktion als Task zu deklarieren, muss man nichts weiter tun als sie mit einem @task Annotator zu versehen. Sehr simpel, wie man anhand eines „Hello World“-Beispiels sehen kann:
|
1 2 3 4 5 |
@task def say_hello(): print("Hello, world!") |
Datenfluss
Unnötig kompliziert werden Workflows mit Airflow oft durch die mangelnde Unterstützung für den Austausch von Daten zwischen Tasks. In der Dokumentation verweist man darauf, dass Tasks nach Möglichkeit unabhängig voneinander laufen sollen, denn Airflow will auch eine verteilte Ausführung auf mehreren Maschinen unterstützen. Zwei Tasks, die Daten miteinander austauschen müssen, könne man ja zu einem großen Task zusammenfassen.
Immerhin, für den Fall, dass es eben doch nicht anderes geht, gibt es sogenannte „XCom“s, mit denen der Datenaustausch letztendlich doch möglich ist. Das Problem ist allerdings, dass XComs dafür konzipiert worden sind, nur Metadaten zu übertragen. Sie werden in die Airflow Metadaten-Datenbank geschrieben, mit der Folge, dass diese maximal so groß wie die von der Datenbank unterstützte Größe eines BINARY LARGE OBJECT (BLOB) sein dürfen. In der Praxis ist es damit nicht einmal möglich, eine handelsübliche HTML-Seite abzuspeichern, ganz zu schweigen von größeren Listen oder Dataframes. Natürlich lassen sich zahlreiche Wege finden, diese Einschränkung zu umgehen. Dennoch festigt sich damit Eindruck, dass Airflow nicht so recht dafür geeignet ist um Data-Pipelines aufzubauen.
Mit Prefect lässt sich der Datenfluss genauso intuitiv wie einfach implementieren: Upstream-Daten werden einem Task (=> Python-Funktion) als Parameter übergeben, Downstream-Daten entsprechen dem Rückgabewert der Funktion. Zur Veranschaulichung dient im Folgenden ein stark vereinfachtes ETL (Extract – Transform – Load) Bespiel:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
@task def extract(): return range(10) @task def transform(x): return [i * 10 for i in x] @task def load(y): for i in y: print("Received i: {}".format(i)) |
Flows
Abhängigkeiten von Tasks und deren Daten werden in Prefect durch Flows beschrieben. Die API erinnert dabei stark an Tensorflow-Sessions. Das ist einleuchtend, denn einen von Tensorflow erstellten Computational Graph kann man genau so gut durch das Wort Workflow ersetzen. Umgekehrt gilt natürlich dasselbe. Prefect erstellt nichts anderes als einen computational graph, der einen Workflow repräsentiert. In Airflow wird dieses Konzept bekanntermaßen als DAG (Directed Acyclic Graph) bezeichnet.
Der Flow setzt sozusagen die einzelnen Bausteine eines Workflows zusammen. Dabei können Abhängigkeiten zwischen Tasks definiert werden, indem instanziierte Downstream-Tasks als Upstream-Parameter des jeweils nächsten Tasks übergeben werden. Schlussendlich wird mit der run() Methode der Workflow lokal ausgeführt. Und das war es auch schon. Mehr Code ist nicht notwendig um einen Workflow in Prefect zu definieren.
|
1 2 3 4 5 6 7 8 9 |
with Flow("ETL") as flow: e = extract() t = transform(e) l = load(t) flow.run() |
Visualisierung und Debugging
Es fällt auf, dass in diesem lokalen Szenario weder eine Backend Datenbank aufgesetzt noch ein Scheduler-Prozess gestartet werden musste. Letzteres gilt auch, wenn anders als im vorangegangenen Beispiel ein Scheduler für die automatisierte Ausführung eines Workflows verwendet wird. Bevor man einen Workflow deployed, ist es also ohne großen Aufwand möglich, ihn lokal zu testen und zu debuggen. Die visualize() Methode ist eine weitere Möglichkeit, um lokal einen besseren Überblick über einen Flow zu bekommen und mögliche Fehler in den Abhängigkeiten von Tasks sichtbar zu machen. Für einen Flow Run kann man sich auch die Zustände der einzelnen Tasks (z.B. SUCCESS, FAILED oder SKIPPED) direkt zurückgeben lassen und anschließend der visualize() Methode als Parameter übergeben. Die verschiedenen Zustände werden dabei entsprechend farblich hervorgehoben (hier: grün für SUCCESS). Unter der Ausgabe ist zudem ein Schaubild dargestellt, das alle Zustände beinhaltet, die Prefect Tasks annehmen können.
|
1 2 3 |
task_states = flow.run() flow.visualize(flow_state=task_states) |

Dynamische Workflows
Häufig ist es der Fall, dass es innerhalb eines Workflows einen Task gibt, den man mit einer vorerst unbekannten Anzahl von Wiederholungen ausführen möchte. Beispielsweise in folgendem Szenario: Task A durchsucht eine Datenbank nach neuen Kundeneinträgen. Jeder Eintrag muss anschließend einem Task B übergeben werden, der diesen weiter verarbeitet. Mit Airflow ist man nun gezwungen, Task B so zu implementieren, dass es als Eingabe die komplette Liste der Einträge nimmt und darüber iteriert. Was passiert allerdings in einem Szenario, in dem die Verarbeitung eines Eintrags auf irgendeine Weise fehlschlägt? Richtig, der gesamte Task B schlägt fehl. Er muss unter Berücksichtigung von Idempotenz komplett neu ausgeführt werden.
Viel einfacher wäre es natürlich, wenn es eine Möglichkeit gäbe, nur die eine fehlgeschlagene Operation erneut auszuführen. Prefects Task-Mapping löst dieses Problem auf einfache Art und Weise. Es erlaubt nämlich die dynamische Generierung von Task-Instanzen zur Laufzeit. Die Mappings können dann ohne Probleme auch parallel ausgeführt werden wodurch dynamischen parallelen Daten-Pipelines nichts mehr im Wege steht.
Wir definieren nun unser ETL-Beispiel ein wenig um, sodass transform() und load() nur noch einzelne Elemente bearbeiten. Die Magie findet nun im Bereich der Flow-Deklaration statt. Die map()–Funktion ist dafür verantwortlich, dass für jedes Element aus der Liste der Upstream-Daten ein eigenständiger Task erzeugt wird. Wenn wir uns nun erneut ein Szenario vorstellen, in dem einer dieser Tasks fehlschlägt, erkennt Prefect automatisch, dass diese einzelne Task-Instanz wiederholt werden muss. Der Vollständige Code sieht nun wie flogt aus:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@task def extract(): return range(10) @task def transform(x): return x * 10 @task def load(y): print("Received y: {}".format(y)) with Flow("ETL Example") as flow: e = extract() t = transform.map(e) l = load.map(t) flow.run() |
Noch einmal kurz und knapp: Task-Mapping ermöglicht es, parallelisierbare For-Schleifen zur Laufzeit in parallele Pipelines zu verwandeln. Für Situationen, die ein While-Schleifenmuster während der Laufzeit erfordern, gibt es analog dazu das Task-Looping.
Scheduling
Nun kommen wir zum eigentlichen Herzstück eines jeden Workflow-Tools, das Scheduling. Prefect betreibt Schedules anhand zweier wichtiger Parameter. Das clock-Objekt beschreibt, wie oft ein neuer Flow Run initiiert werden soll, gegebenenfalls ergänzt durch ein Start- und/oder Endzeitpunkt der Aktivität. Zudem können ein oder mehrere Filter einschränken, welche Flow Runs tatsächlich ausgeführt werden. Denkbar wäre ein Szenario, in dem ein Filter Flow Runs nur an Wochentagen oder während der Geschäftszeiten zulässt.
In unserem Beispiel verwenden wir ein IntervalClock-Objekt, welches beginnend ab jetzt ein Jahr lang jede Stunde einen Flow Run auslöst und wir verzichten auf Filter. Anschließend ruft die Methode next(5) die nächsten fünf festgelegten Zeitpunkte ab. Nun ist nur noch zu beachten, dem Flow bei seiner Erstellung das Schedule-Objekt zu übergeben.
|
1 2 3 4 5 6 7 |
schedule = Schedule(clocks=[IntervalClock(timedelta(hours=1), start_date=datetime.now(), end_date= datetime.now() + timedelta(years=1))]) schedule.next(5) with Flow("ETL Example", schedule=schedule) as flow: ... |
Parametrisierte Workflows
Ein weiteres Konzept von Prefect sind Parameter. Sie werden innerhalb von Flows definiert und werden intern genau wie Tasks behandelt. Der Unterschied ist, dass sie anders als Tasks keine Funktion ausführen sondern lediglich einen Wert enthalten, der einem Task als Input übergeben werden kann. Parameter sind besonders nützlich, weil man sie auch zur Laufzeit und in Echtzeit verändern kann. Es ist beispielsweise möglich über die Prefect Cloud UI Parameter von Workflows zu setzen, ohne sie aus dem Scheduler nehmen oder stoppen zu müssen. Ein Einsatzszenario dafür könnte eine Datenbank oder Tabelle sein, die von einem Task abgerufen wird. Wird beispielsweise deren Namen extern geändert, kann man den Parameter für den Namen in der UI einfach auch neu setzen.
Versionierte Workflows
Das Versionieren von Workflows ist eine häufig gestellte Anforderung für das Deployment. Airflow bietet dieses Feature von Haus aus nicht, sodass man ein eigenes Versionierungssystem implementiert muss, wenn man nicht darauf verzichten will. Bei Prefect Cloud werden Workflows mittels Docker-Container deployed. Sobald das Programm feststellt, dass eine neue Version eines bereits bekannten Workflows eingetroffen ist, wird diese automatisch als Folgeversion der alten abgespeichert. Mit der Prefect Cloud UI lassen sich dann nicht nur die aktuelle Version sondern auch alle alten Versionen eines Workflows betrachten und aktivieren.
Und vieles mehr …
Natürlich besitzt Prefect noch weitere interessante Ansätze und Ideen, die aus Gründen der Ausführlichkeit hier nicht explizit aufgeführt sind. Dem interessierten Leser sei dafür die sehr übersichtliche und angenehm lesbar geschriebene Prefect Dokumentation mit an die Hand gegeben.
Prefect Cloud
Nun wissen wir, wie Workflows in Prefect aussehen und was ihre Vorteile sind. Dem Begriff Workflow-Management-Tool folgend fehlt also noch der zweite Teil: das Management bzw. die Orchestrierung. Sie umfasst neben dem Steuern und Überwachen von Workflows auch ein User Interface (UI), mit dem diese Tätigkeiten auf benutzerfreundliche Weise ausgeführt werden können. Prefect Cloud haben die Entwickler es getauft.
Gerade die UI ist dank ihrer zahlreichen Möglichkeiten eine der Stärken von Prefects Konkurrent Airflow. Doch auch Prefect verspricht hier einen größtmöglichen Funktionsumfang. Zu sehen ist davon allerdings noch nicht ganz so viel, da Prefect Cloud noch in den Kinderschuhen steckt. Man muss aber fair bleiben und erwähnen, dass die Entwickler gerade in den letzten Monaten große Fortschritte in Richtung eines vermarktbaren Produktes gemacht haben. Zu den bereits implementierten Features zählen:
- Projekt-, Flow-, Flow Run-, Task- und Task Run-Dashboard
- Logs anschauen und filtern
- Gruppenfunktion
- Interaktive GraphQL API
- Interaktion mit Workflows: Starten, Flow-Parameter ändern, States von Task Runs und Flow Runs ändern, Schedules starten/stoppen
Zusätzlich zu den genannten Funktionen wären zwei Dinge in naher Zukunft wünschenswert. Zum einen die Visualisierung von Flow Runs, ähnlich zu der Ausgabe der visualize()-Methode. Momentan sieht man nur die Zustände der Tasks einzeln aber nicht den großen Zusammenhang. Zum anderen die Möglichkeit, die bereits modular angelegte Benutzungsoberfläche nach eigenen Wünschen anpassen zu können.
Die folgenden Screenshots sind hilfreich, um einen ersten Eindruck von der UI zu bekommen:


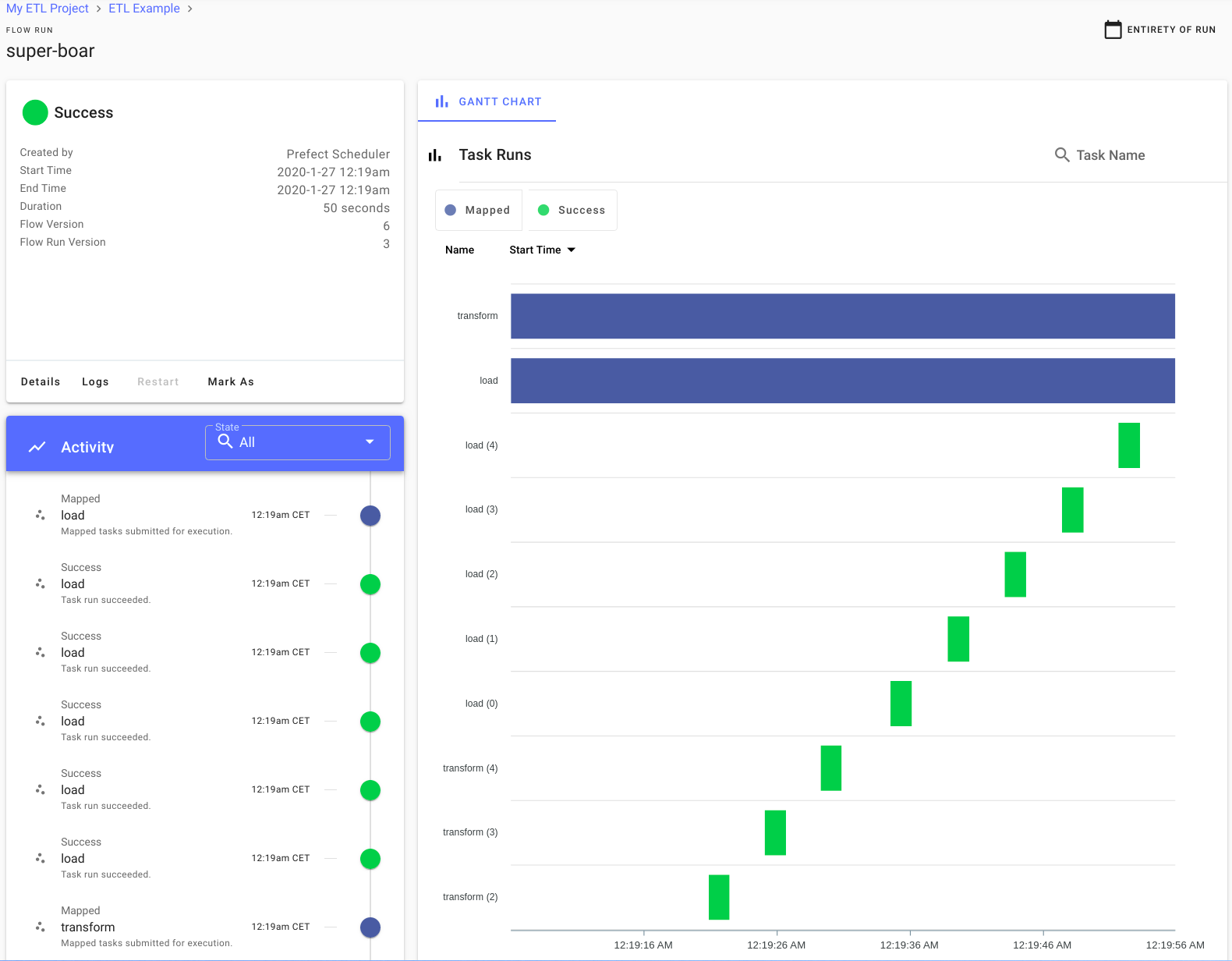



Interaktion mit Prefect Cloud
Wie so oft im Leben gibt es auch mit Prefect Cloud verschiedene Wege, um ans Ziel zu kommen. Für die meisten Belange sind es vier Stück an der Zahl:
- Command Line Interface (CLI)
- Python
- Schaltflächen der UI
- Interaktive GraphQL API in die UI integriert (GraphQL ist eine open-source Abfragesprache, mit der sich alle erdenklichen Daten und Parameter der internen Prefect Cloud Datenbank abfragen (query) und manipulieren (mutation) lassen)

Der Benutzer interagiert in drei Schritten mit Prefect Cloud:
- Lokalen Rechner authentifizieren: Am einfachsten ist es, sich dafür über die Web UI anzumelden. Ebenfalls ist es üblich, sich mit einem zuvor erstellten Token über das CLI zu authentifizieren:
1prefect auth login -t <USER-TOKEN> - Flows in Prefect Cloud registrieren: Wir greifen nun zurück auf das Beispiel des Task-Mapping-Abschnitts. Anstatt den Flow durch flow.run() lokal auszuführen, machen wir ihn zunächst mit der register() Methode Prefect Cloud bekannt:
123456789with Flow("ETL Example") as flow:e = extract()t = transform.map(e)l = load.map(t)flow.register(<OPTIONS>) - Hochgeladene Workflows ausführen (Flow Runs erstellen): Dieser Schritt ist in unserem Beispiel nicht zwingend notwendig, da das Scheduling des Workflows mit dessen Registrierung sofort aktiv ist. Der Vollständigkeit halber erstellen wir aber einen weiteren Flow Run abseits des Schedules. Das geschieht durch des Client-Objekt, welches die Methode create_flow_run() aufruft.
123456789with Flow("ETL Example", schedule=schedule) as flow:...flow_id = flow.register("My ETL Project")c = Client()c.create_flow_run(flow_id=flow_id
Weitere Voraussetzungen
Damit Prefect Cloud die Flow Runs schließlich ausführt, ist es notwendig auf der ausführenden Maschine einen Agent zu starten. Das ist ein Prozess, der Prefect Cloud kontinuierlich nach anstehenden Flow Runs abfragt. Er sorgt dann für die richtige Ausführung und weist dem Flow Run Ressourcen dafür zu. Wenn also der Agent-Prozess nicht im Hintergrund läuft, wird auch Prefect Cloud keine Flow Runs abarbeiten. Gestartet wird ein Agent beispielsweise über das CLI:
|
1 |
prefect agent start -t <RUNNER-TOKEN> |
Wie bei der Authentifizierung des User-Token muss man dem Agent ein zuvor generiertes Runner-Token übergeben, damit er weiß mit welcher Prefect Cloud Instanz er sich in Verbindung setzen muss.
Es ist problemlos möglich, Workflows lokal abzuspeichern und somit auch lokal von Prefect Cloud ausführen zu lassen. Das ist vor allem für das Testen und Kennenlernen von Prefect Cloud sinnvoll. In einer Produktionsumgebung hingegen ist es unerlässlich, die Verfügbarkeit von Flows über den eigenen Rechner hinaus zu gewährleisten. Ab diesem Zeitpunkt muss zusätzlich Docker installiert sein und laufen.
Bei der Registrierung eines neues Workflows in Prefect Cloud wird dann das Flow-Objekt serialisiert und in einem Docker Container abgelegt. Ohne weiteres Zutun verwendet Prefect Cloud ein Default Docker Image. Es ist aber genauso möglich und manchmal auch notwendig, ein eigenes Image zu verwenden, vor allem wenn es darum geht, Dependencies zu installieren. PyPI-Dependencies lassen sich ganz einfach über einen entsprechenden Befehl in Zusammenhang mit der Registrierung eines Flows mit einbinden. Alle anderen muss man nach jetzigem Stand der Dinge in einem benutzerdefinierten Container „per Hand“ einfügen. Als letzten Schritt gibt man bei der Registrierung noch eine Docker Registry an, auf die das Image gepusht werden soll.
Bei der Ausführung eines neues Workflows wird das Image, das den Flow beherbergt, von der Registry geladen. Der Agent sorgt dafür, dass alle Infrastrukturanforderungen erfüllt sind und führt den Flow Run mit dem spezifizierten Wo und Wie aus.
Deployment Anpassen
Die zwei zentralen Fragen, die man im Zusammenhang mit dem Deployment klären muss, sind:
- Wo will ich meine Flows speichern?
- Wie und wo sollen meine Flow Runs ausgeführt werden?
Für die erste Angelegenheit ist das Storage-Objekt der richtige Ansprechpartner. Angeschnitten haben wir bereits den „Local Storage“ für die Speicherung auf dem eigenen Rechner sowie den „Docker Storage“ für eine universelle Verfügbarkeit in einer Docker Registry. Das ist sicherlich für die meisten Use Cases absolut zweckmäßig. Falls man aber dennoch Cloud-Speicher der gängigen Anbieter bevorzugt, bietet Prefect Cloud auch dafür die Schnittstellen. Nachfolgend die komplette Liste der aktuell verfügbaren Optionen:
- Lokal (Default)
- Docker Registry
- Azure Blob
- AWS S3
- Google Cloud
Das Environment wiederum spezifiziert, wo und wie der Flow Run ausgeführt werden soll und ob es irgendwelche zusätzlichen Infrastrukturanforderungen gibt. Dafür stehen aktuell folgende Spezifikationen zur Verfügung:
- Remote Environment (Default)
- Dask Kubernetes Environment
- Kubernetes Job Environment
- Fargate Task Environment
- Custom Environment
Es gilt noch zu beachten, dass die Wahl des Environments auch den Agent beeinflusst. Will man beispielsweise seine Workflows auf einem Kubernetes Cluster ausführen, gibt es dafür eigens einen Kubernetes Agent, der die Workflows direkt als Kubernetes Jobs ausführt.
Zum Abschluss gibt es nochmal ein Beispiel in kompletter Ausführung. Als Neuheit wird das Flow-Objekt dabei mit einem Storage– und einem Environment-Parameter ergänzt. Dadurch wird der Workflow in einem Docker Image gespeichert, welches das PyPI-Package numpy installiert hat und auf das angegebene Registry gcr.io/dev gepusht wird. Außerdem wird der Workflow jetzt auf Kubernetes mit einem automatisch skalierenden Dask-Cluster ausgeführt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
@task def extract(): return range(10) @task def transform(x): return x * 10 @task def load(y): print("Received y: {}".format(y)) schedule = Schedule(clocks=[IntervalClock(timedelta(hours=1), start_date=datetime.now(), end_date= datetime.now() + timedelta(years=1))]) schedule.next(5) storage = Docker(registry_url="gcr.io/dev/", python_dependencies=["numpy"]) dask_kubernetes_env = DaskKubernetesEnvironment(min_workers=1, max_workers=3) with Flow("ETL Example", schedule=schedule, storage=docker_storage, environment=dask_kubernetens_env) as flow: e = extract() t = transform.map(e) l = load.map(t) flow_id = flow.register("My ETL Project") |
Kostenmodell
Kommen wir abschließend zur Monetarisierung. Prefect Core ist wie bereits erwähnt open-source und kostet somit nichts. Prefect Cloud kann man aktuell in der Early-Access-Phase für 30 Tage kostenlos testen. Anschließend werden monatliche Kosten fällig. Anfangs sind die Entwickler der Idee nachgegangen, dass es verschiedene Kostenstufen geben soll, mit denen z.B. 10.000, 100.000, oder 1.000.000 erfolgreiche Task Runs pro Monat möglich sind. Das Kostenmodell mutete aber ein wenig seltsam an, denn durch die Abrechnung nach erfolgreichen Tasks pro Monat könnte man sich dazu veranlasst sehen, größere anstelle von kleineren Tasks zu bevorzugen. Genau das widerspricht aber den genannten Konzepten des Datenflusses und des Tasks-Mappings. Möglicherweise war das einer der Gründe, warum das Team von Prefect nun doch einen anderen Weg eingeschlagen hat. Nun ist nämlich eine freie Version von Prefect Cloud geplant – tatsächlich mit unbegrenzt vielen Task und Flow Runs. Diese Version soll dafür aber einen begrenzten Umfang an hochladbaren Flows und eine eingeschränkte Flow Run History haben sowie lediglich als Single-User-System verfügbar sein. Wem diese Einschränkungen zu viel sind, der muss auf die kostenpflichtige Version zurückgreifen.
Fazit
Vorteile:
- Im Gegensatz zu Airflow unterstützt Prefect den Datenfluss zwischen Tasks vollständig
- Dynamische/parametrisierte Workflows ohne Mehraufwand möglich
- Task-Mapping und Task-Looping erlauben dynamische Generierung von Tasks zur Laufzeit
- Lokales Testen von Workflows sehr leicht möglich
- Code für das Definieren von Tasks und Flow übersichtlicher als in Airflow
- Voraussichtlich weitere spannende Features in naher Zukunft
Nachteile:
- Bisher eingeschränkter Funktionsumfang von Prefect Cloud
- Tauglichkeit für große Projekte noch nicht unter Beweis gestellt
- Prefect Cloud in seinem vollen Funktionsumfang kostenpflichtig, Airflow hingegen komplett kostenlos
Alles in allem macht Prefect einen sehr ordentlichen Eindruck und bringt die Voraussetzungen mit, Airflow von der Spitze der Workflow-Management-Tools zu verdrängen. Ob das tatsächlich passiert ist natürlich eine andere Frage. Eines kann aber mit hoher Wahrscheinlichkeit gesagt werden: Dadurch dass sich Prefect in einigen Punkten doch stark von Airflow abhebt, werden sich immer genügend Ansätze finden, in denen Prefect den Data Engineers das Leben einfacher machen kann.


