
Anwendungskomponenten, die mittels Kubernetes als Pods ausgeführt werden, können über mehrere Knoten eines Clusters verteilt sein. Die knotenübergreifende Netzwerkkommunikation stellt daher eine besondere Herausforderung dar. Aufgrund der Vielzahl unterschiedlicher Netzwerkumgebungen stellt Kubernetes zwar grundlegende Anforderungen an Netzwerkimplementierungen, setzt diese selbst aber nicht um. Stattdessen wird auf eine verbreitete Spezifikation, das Container Network Interface (CNI), für die Anbindung entsprechender Netzwerkimplementierungen zurückgegriffen. Aufgrund dieser Entkopplung sowie der breiten Akzeptanz von CNI steht eine Vielzahl kompatibler Plugins für die Verwendung mit Kubernetes zur Verfügung.
Diese Artikelserie fasst die Untersuchungen meiner Bachelorthesis aus September 2019 zusammen, in der ich die Grundlagen des Kubernetes Networkings beleuchtet und die funktionalen und technischen Unterschiede dreier bekannter Netzwerk-Plugins aufgezeigt habe. Darüber hinaus wurden mögliche Kriterien dargelegt, die für den Vergleich weiterer Plugins oder die Entscheidungshilfe bei der Auswahl eines Plugins herangezogen werden können.
Der erste Teil dieser Serie befasst sich mit den Grundlagen des Container Networkings am Beispiel Docker. Wir nutzen diese zum Verständnis der internen Netzwerkmechanismen von Kubernetes sowie der Funktionsweise eines „Podnetzwerks“. Außerdem geht der Artikel der Frage nach, wofür wir ein Kubernetes Netzwerk Plugin überhaupt benötigen. Der zweite Teil beleuchtet die Netzwerk-Plugins Project Calico, Cilium und Weave Net und stellt ihre grundlegenden Funktionsweisen und Unterschiede heraus. Am Ende dieser Artikelserie solltet ihr einen Überblick über die Grundkonzepte des Kubernetes Networkings erhalten und Kriterien aufgezeigt bekommen haben, nach denen ihr das für eure Begebenheiten am besten geeignetste Kubernetes-Netzwerk-Plugin auswählen könnt.
Grundlagen des Container Networkings
Standardmäßig operieren Docker Container im Bridge-Modus. Die folgende Abbildung veranschaulicht ein klassisches Szenario, bei dem zwei Docker Container in einem gemeinsamen Bridge-Netzwerk gestartet werden.
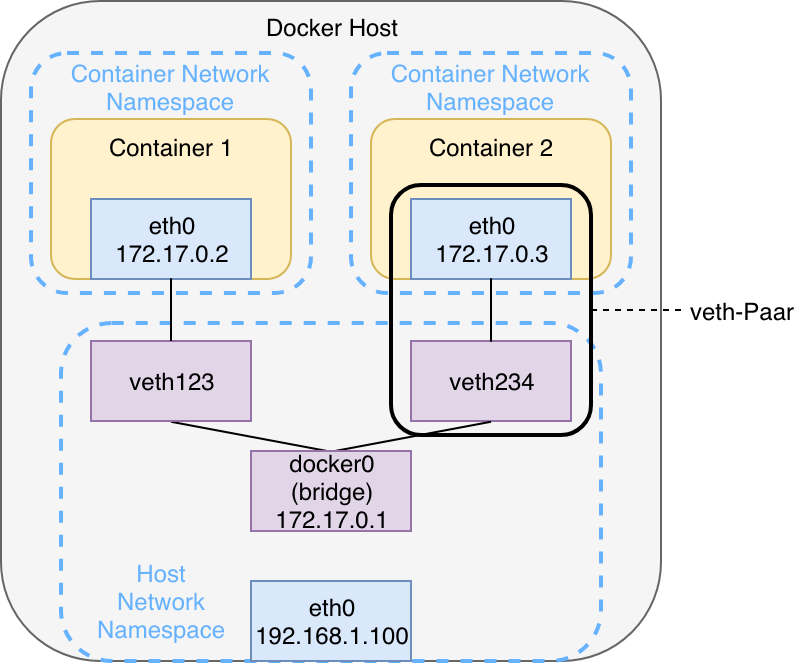
Docker erzeugt dabei pro Netzwerk eine virtuelle Linux Bridge, initial mit der Bezeichnung docker0, die nach außen mittels Linux Kernel Routing über die physische Schnittstelle des Hosts ( eth0) kommunizieren kann. Intern spannt sie einen eigenen Adressraum in Form eines Subnetzes auf. Die Container werden jeweils über ein veth-Paar an die Bridge angeschlossen. Das Paar fungiert wie eine virtuelle Punkt-zu-Punkt-Ethernetverbindung und verbindet die Network Namespaces der Container mit dem Network Namespace des Hosts. Die Kommunikation zwischen den Containern verläuft innerhalb eines Docker-Bridge-Netzwerks über die entsprechende Bridge – vorausgesetzt die IP-Adresse beziehungsweise der Hostname des Zielcontainers ist bekannt. Da beide Container in einem eigenen Network Namespace ausgeführt werden, besitzen sie individuelle Routing-Tabellen, Schnittstellen und iptables-Regeln.
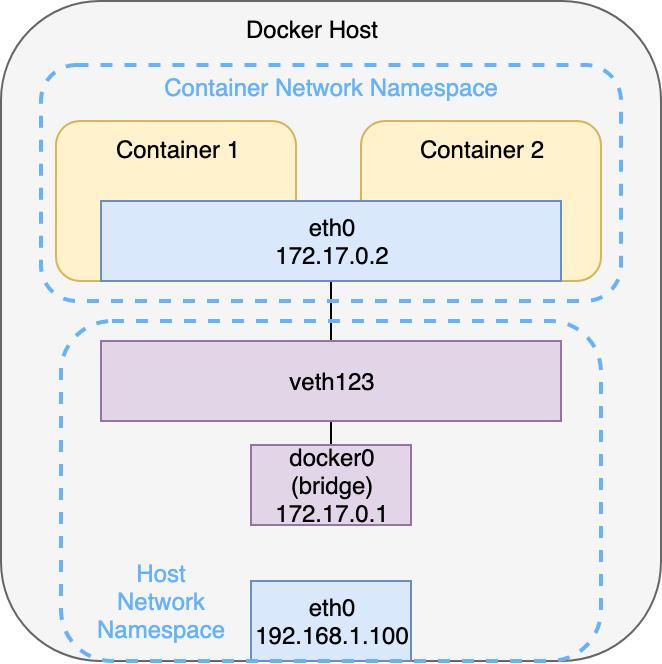
Startet man hingegen einen Docker Container mit der Option --net=container:<container-name>, wobei <container-name> dem Namen eines bereits ausgeführten Containers entspricht, wird der neue Container an die virtuelle Netzwerkschnittstelle des vorhandenen Containers angebunden. Beide Container befinden sich nun im selben Netzwerk Namespace und teilen sich denselben Netzwerkstack. Eine Kommunikation ist daher über localhost möglich. Genau dieses Konzept macht sich Kubernetes für die Kommunikation zwischen Containern innerhalb eines Pods zu Nutze. Zur Erinnerung: Ein Pod kann aus mehreren Containern (meistens ein Hauptcontainer mit einem oder mehreren Sidecar Containern) bestehen. Wird nun auf Container 1 ein Webserver auf Port 8080 betrieben, ist dieser von Container 2 über http://localhost:8080 erreichbar, obwohl er den Prozess selbst nicht ausführt. Man spricht im Kontext von Kubernetes von der Container-to-Container-Kommunikation. Abbildung 2 veranschaulicht diesen Aufbau.
Innerhalb eines Kubernetes Pods besteht nun gegenüber Abbildung 2 lediglich die Besonderheit, dass unabhängig von den „Nutzcontainern“ zusätzlich ein pause-Container existiert, der den Network Namespace einschließlich der Netzwerkschnittstelle initial erzeugt und aufrechterhält. Sollten alle Nutzcontainer ausfallen, bleibt der Pod und somit der Namespace trotzdem bestehen, sodass die Container ihm später wieder hinzugefügt werden können.
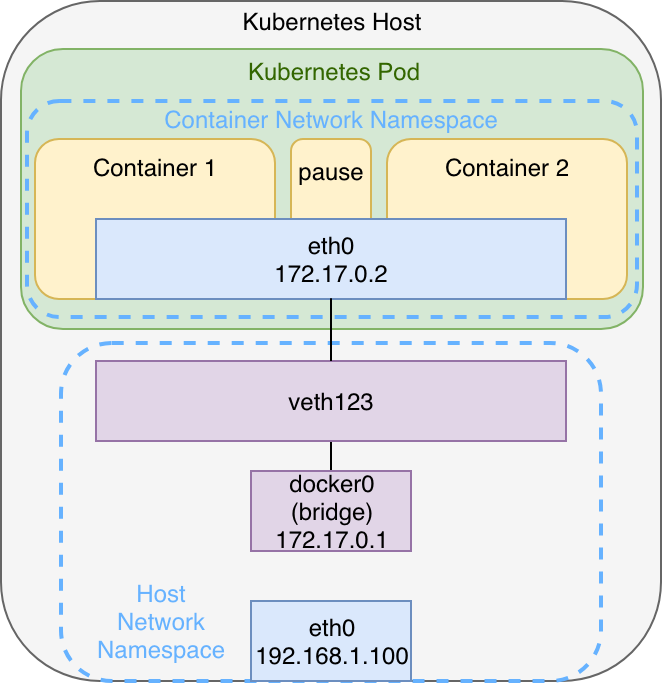
Der in Abbildung 3 dargestellte Aufbau kann z.B. bei der Verwendung von minikube mit Docker als Container Runtime nachvollzogen werden. Existieren weitere Pods werden diese nach demselben Schema über weitere veth-Paare an die Bridge angeschlossen. Je nach Container Runtime und verwendeten Netzwerk-Plugins bei Multi-Node-Clustern kann dieser Aufbau jedoch variieren, wie wir im zweiten Teil dieser Serie noch feststellen werden. Dennoch bietet er eine gute Grundlage zum Verständnis der knotenlokalen Netzwerkmechanismen – insbesondere dann, wenn man sich vor dem Einstieg in Kubernetes bereits mit Docker befasst hat.
Das Kubernetes-Netzwerkmodell
Nachdem wir uns bis hier hin darauf beschränkt haben, wie das Networking zwischen Containern innerhalb eines Pods erfolgt, begeben wir uns nun eine Abstraktionsebene höher und beschäftigen uns mit der Kommunikation zwischen Pods. Hierzu stellen wir uns eine simple Webapplikation vor, bestehend aus Frontend und Backend. Zur Erinnerung: Weil beide Komponenten völlig unterschiedliche Beschaffenheiten aufweisen (zustandslos vs. zustandsbehaftet), würde man sie als separate Pods ausführen, um sie auch getrennt voneinander skalieren zu können. Damit die Webapplikation ordnungsgemäß funktioniert, müssen diese Pods stets miteinander kommunizieren können – unabhängig davon, auf welchen Knoten sie ausgeführt werden. Mit der Pod-to-Pod-Kommunikation gilt es somit sicherzustellen, dass sowohl Pods eines einzigen Knotens als auch Pods unterschiedlicher, auch topologisch entfernter Knoten, stets eine Netzwerkverbindung zueinander aufbauen und Daten austauschen können. Schließlich soll Kubernetes die Workloads möglichst gleichmäßig über die verfügbaren Knoten verteilen, aber zugleich die zugrundeliegenden Hardwareressourcen abstrahieren. Für den Entwickler einer Applikation soll es bei der Nutzung von Kubernetes also nicht von Interesse sein, ob Frontend und Backend Pods auf demselben oder auf unterschiedlichen Knoten ausgeführt werden. Die Pod-to-Pod-Kommunikation wird wie folgt umgesetzt:
Jeder Pod in Kubernetes erhält eine eindeutige IP-Adresse, die eine clusterweite Gültigkeit besitzt. Darüber hinaus stellt Kubernetes die Anforderung, dass innerhalb eines Clusters alle Pods eines Knotens mit allen Pods anderer Knoten ohne Network Address Translation (NAT) kommunizieren können. Dies soll die Kommunikation zwischen Anwendungskomponenten vereinfachen und jeden Pod clusterweit über die IP-Adresse erreichbar machen, die auch seiner virtuellen Netzwerkschnittstelle zugeordnet ist.
Was bei der Kommunikation zwischen knotenlokalen Pods bei der Verwendung einer gemeinsamen virtuellen Linux Bridge (L2) bereits implizit erfüllt ist – wir erinnern uns an die Ausführungen rund um Abbildung 3 – stellt sich knotenübergreifend als komplexer dar: Zum einen muss ein IP-Address-Management (IPAM) stattfinden, damit IP-Adressen innerhalb eines Clusters nicht mehrfach vergeben werden und Konflikte auftreten. Zum anderen müssen die lokalen Bridge-Netzwerke aller Knoten miteinander verbunden werden, damit eine Kommunikation auch knotenübergreifend stattfinden kann.
Für die Implementierung eines Podnetzwerks nach den genannten Anforderungen existieren mehrere Möglichkeiten: Sie kann entweder manuell durch einen Administrator erfolgen oder von einer an das Kubelet angebundenen, externen Komponente – dem Netzwerk Plugin – übernommen werden. Zur Erinnerung: Das Kubelet bildet die primäre Schnittstelle zwischen der Kubernetes API und der lokalen Container Runtime und wird auf jedem Knoten als Agent ausgeführt. Aus netzwerktechnischer Sicht kann die knotenübergreifende Kommunikation auf Layer 2 (Switching), Layer 3 (Routing) oder durch ein Overlay-Netzwerk realisiert werden.
Eine mögliche Implementierung eines Podnetzwerks könnte wie folgt aussehen:
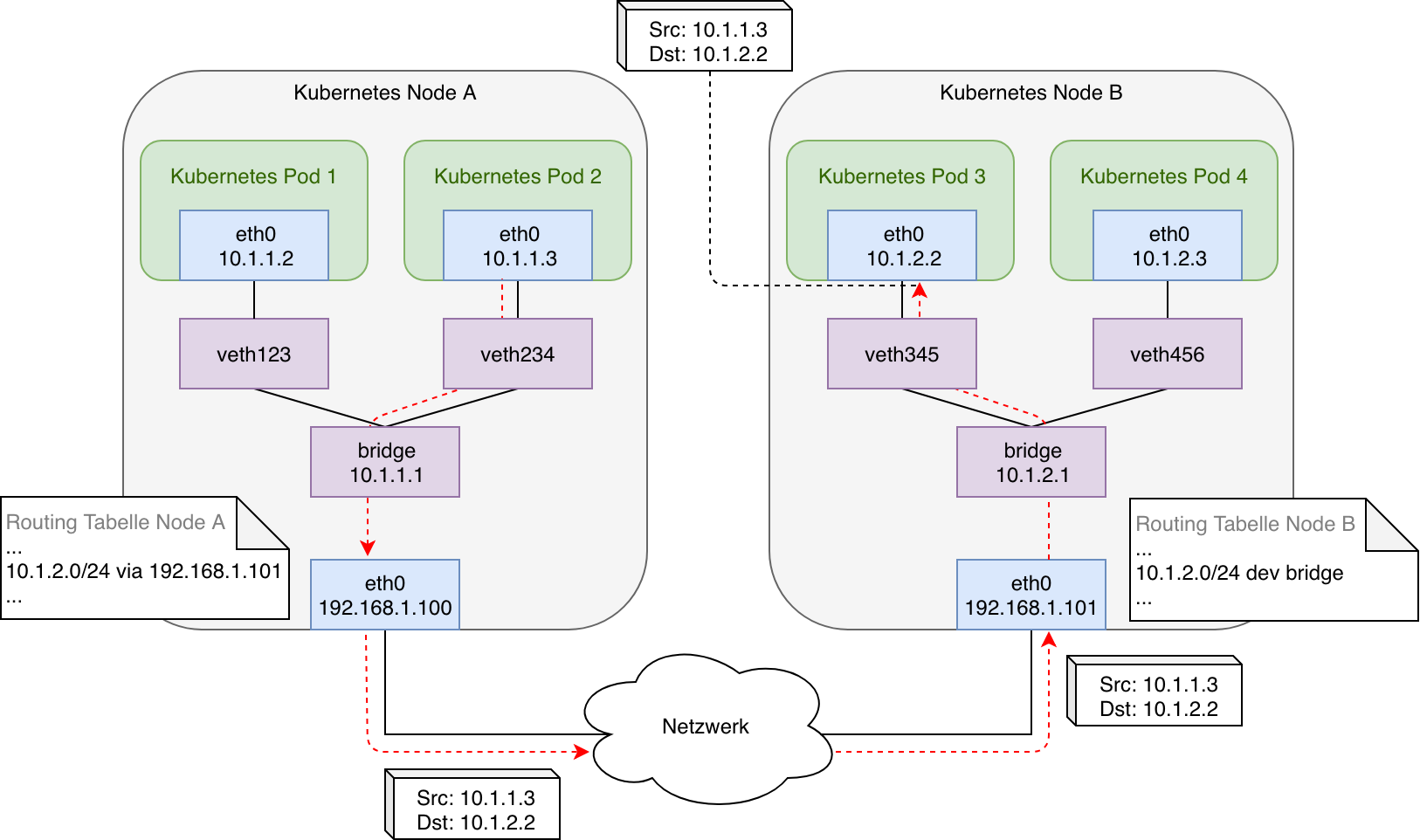
Hierbei werden die beiden knotenlokalen Bridges über die Implementierung von simplen Routingegeln miteinander verbunden: Dafür sind die Routing-Tabellen der Knoten jeweils so einzurichten, dass sie die internen Bridge-Netzwerke aller anderen Knoten beinhalten und als Next-Hop auf die physische Schnittstelle des jeweiligen Knotens verweisen. Ebenso muss eine Route für das eigene Bridge-Netzwerk vorhanden sein, damit von extern eingehender, ebenso wie lokal initiierter Datenverkehr (z.B. durch einen Pod, der im Hostmodus betrieben wird) an die eigenen Pods, intern an die entsprechende virtuelle Bridge weitergeleitet wird.
Die Abbildung veranschaulicht die Initiierung eines Datenpakets durch Kubernetes Pod 2 und die Übertragung über die physische Verbindung zwischen Node A und Node B an Pod 3. Die virtuellen Ethernet-Paare ( veth-Paare) bilden hierbei eine logische Verbindung zwischen Network Namespace des Pods und Network Namespace des Hostsystems. Im Falle eines Switched Netzwerks (L2) können beide Knoten über ARP und ihre MAC-Adressen direkt miteinander kommunizieren. Befände sich ein Router zwischen Node A und Node B (L3) müssten diesem die jeweiligen knotenlokalen Bridge-Netzwerke über entsprechende Routen bekannt gemacht werden.
Zusammengefasst erfüllt das in Abbildung 4 dargestellte Podnetzwerk alle durch Kubernetes formulierten Anforderungen: Pods können mit allen lokalen und nicht-lokalen Pods sowie allen Knoten ohne NAT kommunizieren. Alle Knoten (beziehungsweise darauf ausgeführte Prozesse) können mit lokalen und nicht-lokalen Pods sowie allen anderen Knoten ohne NAT kommunizieren. Sobald jedoch an einen anderen Pod gerichtete Datenpakete Router öffentlicher Netze passieren, werden diese aufgrund ihrer aus einem privaten Adressbereich stammenden Ziel-IP-Adresse verworfen. Folglich ist die dargestellte Implementierung nur dann praktikabel, wenn alle Knoten über einen Switch direkt miteinander verbunden sind beziehungsweise es sich um ein privates Netz handelt, in dem eventuell zwischengeschaltete Router konfiguriert werden können. Andernfalls wäre wiederum die Verwendung von NAT erforderlich, um die privaten Adressen zu maskieren und die Datenpakete auch öffentlich routen zu können. Hier kommen Tunnelprotokolle beziehungsweise Overlays ins Spiel, die sich über Netzwerk-Plugins in ein Kubernetes Cluster einbinden lassen. Selbst jedoch in lokalen Netzwerken, in denen Tunnelprotokolle nicht notwendig sind, ist die manuelle Netzwerkkonfiguration von mehreren Knoten und Pods, wie sie mit Abbildung 4 verdeutlicht wird, kaum handhabbar. Diese Arbeit übernehmen und automatisieren Netzwerk-Plugins.
Das Container Network Interface (CNI)
Das Container Network Interface wurde ursprünglich von CoreOS (heute Teil von RedHat) im Zusammenhang mit der Container Runtime rkt entwickelt. Ziel war die Definition einer gemeinsamen Schnittstelle zwischen Netzwerk-Plugins und Container Runtime beziehungsweise Orchestrator. Mittlerweile ist CNI bei Orchestratoren weit verbreitet – mit der Ausnahme von Docker Swarm (hier wird die Docker-eigene Lösung libnetwork eingesetzt) – was in einer Vielzahl kompatibler Plugins von Drittanbietern resultiert.
CNI besteht aus einer Spezifikation sowie Bibliotheken für die Entwicklung von Plugins, die Netzwerkschnittstellen in Linux Containern konfigurieren. Außerdem liefert das CNI Projekt bereits einige kompatible „Core“ Plugins mit, die Grundfunktionalitäten umsetzen – etwa das Erzeugen einer Linux Bridge und das Anbinden von Host und Container an diese. CNI befasst sich ausschließlich mit der Netzwerkkonnektivität von Containern sowie der Freigabe von allokierten Ressourcen (z.B. IP-Adressen) nach dem Löschen von Containern (Garbage Collection) und ist daher leichtgewichtig und einfach zu implementieren. Neben Kubernetes wird CNI unter anderem auch durch OpenShift, Cloud Foundry, Apache Mesos oder Amazon ECS eingesetzt
Für ein besseres Verständnis von CNI lohnt es sich, bestimmte Ausschnitte der Spezifikation genauer zu betrachten: Demnach muss ein CNI-Plugin als ausführbare Datei (executable) bereitgestellt werden, die durch das Containermanagementsystem (im Fall von Kubernetes mit Docker durch das Kubelet) nach der Erzeugung des Network Namespaces eines neuen Containers aufgerufen wird ( ADD-Operation). Anschließend muss das Plugin für das Hinzufügen einer Netzwerkschnittstelle innerhalb des Container Network Namespaces (angelehnt an unser Beispiel aus Abbildung 4 das containerseitige Ende des veth-Paares) sorgen und auf dem Host alle zur Herstellung der Konnektivität erforderlichen Maßnahmen vornehmen (in unserem Beispiel die Verbindung des anderen Endes des veth-Paares mit einer Linux Bridge). Im Anschluss ist dafür Sorge zu tragen, dass der erzeugten Schnittstelle eine IP-Adresse zugewiesen wird und relevante Routen konsistent mit dem IP-Adressmanagement (IPAM) konfiguriert werden, wofür ein entsprechendes IPAM Plugin aufgerufen wird. Laut Spezifikation müssen die folgenden Operationen implementiert werden:
- ADD (Container zu einem Netzwerk hinzufügen),
- DEL (Container von einem Netzwerk löschen),
- CHECK (Überprüfung der Konnektivität) und
- VERSION (Rückgabe der durch das Plugin unterstützten CNI-Versionen)
Die Konfiguration eines Plugins muss zudem über eine JSON-Datei erfolgen. Weitere Einzelheiten werden hier nicht weiter ausgeführt und können der Spezifikation direkt entnommen werden.
Praktisch dargestellt ließe sich ein CNI-konformes Plugin mit einem Bash Script realisieren, das die vier aufgezeigten Operationen in Form von parametrisierten Funktionen implementiert und sich den verfügbaren CLI-Kommandos wie $ ip link oder $ ip route add bedient, um Schnittstellen zu erstellen und zu konfigurieren beziehungsweise Routing-Regeln zu erzeugen.
Wir haben nun einen Blick in die Spezifikation geworfen und einen Eindruck erhalten, wie ein Netzwerk Plugin nach CNI-Vorgaben zu implementieren ist. Doch wie erfolgt die Implementierung von CNI innerhalb von Kubernetes? Aus der Sicht von Kubernetes in Verbindung mit Docker als Container Runtime (Dockershim) ist CNI selbst ein Netzwerk-Plugin. Es wird an das Kubelet pro Knoten angebunden, da das Kubelet für das Erzeugen und Löschen von Containern auf seinem jeweiligen Knoten zuständig ist. Ausgewählt wird ein Kubelet-Netzwerk-Plugin über die Option --network-plugin=<cni|kubenet>, wobei dies in der Regel implizit durch Installationstools wie kubeadm erfolgt. kubenet ist im Übrigen das Kubernetes „Basis“-Netzwerk-Plugin, das sich jedoch selbst der CNI Core Plugins bedient und in der Praxis kaum eine Relevanz hat. Werden über das Container Runtime Interface (CRI) alternative Container Runtimes wie containerd oder CRI-O genutzt, interagieren die Runtimes direkt mit dem CNI-Plugin, ohne dass zusätzliche Aufrufe über das Kubelet bzw. Dockershim notwendig sind.
Im Falle von Docker als Container Runtime muss ein an das Kubelet angebundenes Netzwerk-Plugin das Interface NetworkPlugin (siehe GitHub) implementieren, das unter anderem die Funktionen SetupPod() und TearDownPod() spezifiziert. Das Kubelet ruft die erste Funktion auf, nachdem ein pause-Container und somit ein neuer Pod gestartet wurde. Die letzte Funktion wird aufgerufen, nachdem ein pause-Container und somit ein bestehender Pod gelöscht wurde. Die CNI-Implementierung innerhalb von Dockershim nutzt die offizielle CNI-Bibliothek zur Integration in Applikationen (siehe GitHub). Grob skizziert sehen die Methodenaufrufe nach dem Erzeugen eines neuen Pods wie folgt aus:
- Das Kubelet führt die Funktion SetupPod() aus, durch die wiederum die Funktion addToNetwork() (siehe GitHub) aufgerufen wird.
- Durch addToNetwork() wird addNetworkList() aus der importierten CNI Library genutzt. Sie führt innerhalb der Library addNetwork() (siehe GitHub) aus.
- Final wird das bereitgestellte CNI-kompatible Plugin innerhalb von addNetwork() mit der Operation ADD aufgerufen (siehe GitHub).
Demnach ist CNI durch die Implementierung von NetworkPlugin einerseits ein Kubelet-Netzwerk-Plugin, andererseits ein „Lastenheft“ (im Sinne der erwähnten Spezifikation) für Netzwerk-Plugins von Drittanbietern wie etwa Weave Net, das beschreibt, welche Merkmale die durch das Kubelet ausgelösten Operationen aufzuweisen haben.
Installation von Kubernetes Netzwerk-Plugins
Bevor wir im Detail in die Netzwerk-Plugins einsteigen, bleibt zu klären, wie deren Installation in einem Kubernetes Cluster erfolgt. In der Regel wird durch das jeweilige Projekt ein YAML-Manifest mit allen benötigten Kubernetes Ressourcen bereitgestellt, die lediglich mit $ kubectl create -f im Cluster erzeugt werden müssen. Denn neben der CNI Binary, welche die Schnittstellenkonfiguration der Pods bei deren Erstellen oder Löschen vornimmt, sind je nach Funktionsumfang des Plugins weitere Komponenten notwendig – oftmals in Form eines oder mehrerer privilegierter Pods, die als DaemonSet auf jedem Knoten ausgeführt werden. Sie beeinflussen die Netzwerkkonfiguration des Knotens oder können Traffic gar abgreifen und eigenständig weiterleiten, um die knotenübergreifende Kommunikation zwischen Pods sicherzustellen. Denn nur weil die CNI Binary den Pods eine IP-Adresse zugewiesen und sie mit dem Network Namespaces ihrer Hosts verbunden hat, heißt das noch nicht, dass dem Host auch die Informationen vorliegen, wie andere Kubernetes Nodes und ihre Pods erreichbar sind – wir erinnern uns wieder an Abbildung 4, wo diese Informationen manuell durch Routing-Regeln bereitgestellt wurden. Es wird darüber hinaus möglich, Overlay-Netzwerke zu erzeugen, indem die auf jedem Knoten ausgeführten Komponenten über eine Control Plane miteinander kommunizieren und Mechanismen implementiert werden, um Datenpakete ein- und auszukapseln.
Auch für die Umsetzung von Netzwerkrichtlinien können weitere Komponenten notwendig sein – etwa ein weiterer privilegierter Pod, der NetworkPolicy-Ressourcen überwacht und iptables-Regeln auf dem Host implementiert beziehungsweise löscht. Es wird deutlich, dass ein Netzwerk-Plugin (oder besser eine Netzwerklösung) aus deutlich mehr als der CNI Binary besteht. Es wird auch deutlich, dass diese Lösungen interoperabel einsetzbar sind und die eigentliche Komplexität in ihren jeweiligen Komponenten liegt. Diese müssen lediglich auf der Zielplattform betrieben werden und bauen zunächst unabhängig von etwaigen Workloads ein clusterüberspannendes Netzwerk auf. Das CNI-Plugin sorgt dann durch entsprechende Schnittstellenkonfigurationen nur noch dafür, dass neue Workloads auf der Plattform diesem Netzwerk hinzugefügt beziehungsweise später wieder gelöscht werden. Anstelle der Nutzung von privilegierten Pods könnte ebenso direkt auf dem Host ein Routingdaemon wie BIRD für BGP installiert werden, um die Konnektivität zwischen den Knoten sicherzustellen. Man erkennt die lose Kopplung beziehungsweise den modularen Ansatz zwischen Netzwerklösung und Plattform.
Zusammenfassung
Was lässt sich abschließend festhalten? Die knotenlokalen Netzwerkmechanismen von Kubernetes lassen sich am Beispiel Docker leicht verständlich herleiten und sind mit Linux-Bordmitteln umsetzbar. Komplizierter wird es bei der knotenübergreifenden Pod-to-Pod-Kommunikation. Zum einen muss eine clusterweit konfliktfreie Vergabe von IP-Adressen gewährleistet werden, damit jeder Pod über seine eigene, eindeutige IP-Adresse verfügt. Zum anderen muss jeder Pod über diese IP-Adresse auch clusterweit ohne NAT erreichbar sein. Was bei wenigen Knoten innerhalb eines lokalen Netzwerks in Anlehnung an Abbildung 4 noch als manuell umsetzbar erscheinen mag, ist in größeren (Produktiv-)Umgebungen und/oder öffentlichen Netzen nicht mehr praktikabel. An dieser Stelle setzen Netzwerk-Plugins an. Sie übernehmen die Netzwerkkonfiguration der Pods – etwa die Vergabe von IP-Adressen – und deren Verbindung zum zuvor erzeugten Podnetzwerk, ohne dass ein manueller Eingriff erforderlich ist. Über den de-facto Standard CNI, der wie eine Art Adapter zwischen Kubelet bzw. Container Runtime und Netzwerk-Plugins von Drittanbietern fungiert, stehen eine Vielzahl kompatibler Lösungen zur Verfügung, die auf ihre eigene Art und Weise, aber stets unter Einhaltung der durch Kubernetes definiertes Anforderungen, ein knotenüberspannendes Netzwerk herstellen. Drei solcher Lösungen, nämlich Project Calico, Cilium und Weave Net, schauen wir uns im zweiten Teil dieser Serie genauer an.


