
Notice:
This post is older than 5 years – the content might be outdated.
One of my favourite essays by Joel Spolsky (he of Stack Overflow fame) is “The law of leaky abstractions“. In it he describes how the prevalence of layers of abstraction – be it coding languages or libraries or frameworks – have helped us accelerate our productivity. We don’t have to talk directly to a database engine because we can let our SQL do that for us; we don’t have to implement map reduce jobs in java anymore because we can use Hive; we don’t have to… well, you get the idea.
But he also points out that even the best frameworks and languages are less than perfect, and when things go awry, these frameworks “leak“ the details of their abstraction out to the observing world. We are then confronted with all the nuts-and-bolts of the implementation that had been hitherto kindly hidden from us, and we often have no alternative but to busy ourselves with a depth of detail that we had not expected.
Hadoop is a good case in point: consider my first Hadoop project in 2011, shown below on the left (“on premise“) where we implemented most of the map-reduce jobs in java with a sprinkling of pig scripts.

Compare that to the project we have just completed, running on Microsoft Azure, shown on the right (“cloud“).
Note that we have added two extra layers of abstraction ourselves (HBase and Phoenix), but that the cloud stack has added another 2 (virtualization and azure storage).
This is all fine… until things are not quite so fine – and then it is a non-trivial task finding the cause. In fact, on rare occasions you may even end up needing to know almost as much about the underlying implementation as if there had been no abstraction layer in the first place! With this as our background, I’d like to offer the following:
- Some reflections on using Phoenix as an SQL layer over HBase
- Some comments on HBase compaction settings in the context of Azure
Phoenix and HBase – a friendship with benefits?
One of the aspects of using HBase is that there is normally (unless you are using the secondary index feature) only one rowkey and hence only one access path through the data: you can issue GETs or range SCANs using this key, but if any other access path is needed – i.e. you are searching for terms by anything other than rowkey (= get) or rowkey prefix (= scan) – then this will result in a full table scan. Since HBase and other components of the Hadoop stack are often used with unstructured data, this poses a challenge. What if we have stored our data using LASTNAME as the rowkey prefix but later realize that we want to search by FIRSTNAME as well?
Apache Phoenix offers capabilities that can be used to escape this cul-de-sac: it is an SQL layer over HBase which offers the following features/advantages relevant to our challenge:
- SQL syntax for retrieving HBase data, a nice alternative to using the native HBase API
- Secondary indices
Phoenix secondary indices are implemented as co-processors (which, put simplistically, act as triggers, keeping the “index“ tables in sync with the “parent“ tables) on the underlying HBase tables. A secondary index uses as its rowkey a combination of the column (or columns) that comprise the index plus the original rowkey, thus preserving uniqueness. You don’t have to populate the index yourself, the co-processor will do that for you when you make changes to the parent table. The optimizer can then use this index as an alternative to the table named in the original query, allowing us to add indices to an existing table and letting the optimizer transparently choose the most appropriate access path. However, a number of things should be carefully noted:
- Phoenix can only track changes to the index if changes made to the parent data are made through Phoenix: you can read from the HBase table using standard HBase tools, but you should only make changes via Phoenix.
- Bulk loading a Phoenix table is theoretically possible using a number of tools (JDBC, Spark, Phoenix Map-Reduce jobs, Pig) that bridge the Phoenix- and HBase-worlds, but in practice this is anything but straightforward.
JDBC only writes line-by-line (JDBC batched writes are only available when using the Phoenix thin JDBC driver which uses the Avatica sub-project of the Calcite library: it is unclear which version contains this but most probably Avatica 1.8 –> Phoenix 4.6 or 4.7?)(As Josh Elser told me, Phoenix is indeed batching things implicitly with autocommit switched off. I stand corrected.), and the Spark and map-reduce jobs run into difficulties if there are too many indices on a table. - The temptation with a tool offering SQL syntax is to assume that declarative set-based operations can be used freely (not an unreasonable assumption, since that is the purpose of SQL!). However, HBase is just not set up for anything other than single gets or discrete range scans, and Phoenix queries, particularly those that cannot use an index, may often result in timeouts.
- Phoenix indices can either be Global (each index is a separate HBase table in its own right), or Local. For the purposes of this article, the important thing to note is that Local indices are preferable since the index data is stored in the same region as the parent data, thus keeping internal RPC-calls to a minimum. They are also still officially in technical preview, and are undergoing significant improvements.
- Phoenix indices are separate from but affected by design decisions within HBase, not all of which have met with unanimous approval.
Compaction distraction
As an aside, let’s briefly discuss one of the concepts central to HBase: that of the Log-structured Merge Tree (also used in Lucene).
HBase writes first to a write-ahead-log on disk, then to an in-memory store (memstore), and acknowledges the write only when both are successful. When the memstore reaches a certain (configured) size, it is flushed to disk and the WAL for that memstore is removed: this is great for writes, but not so great for reads, as there will be an increasing number of small files to access. HBase gets around this by periodically carrying out compactions, such that the individual store files are combined (again, this can be configured). Compactions come in two flavours:
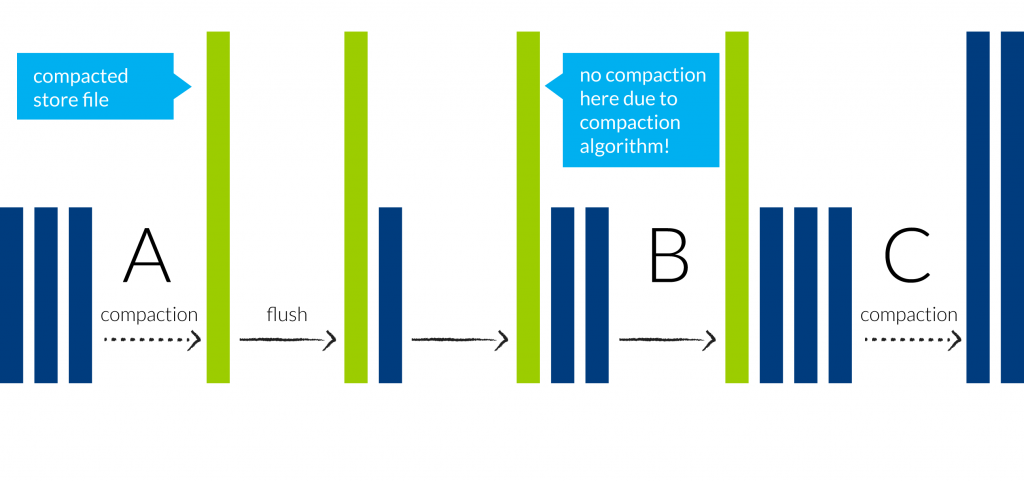
- Minor compactions, whereby the individual store files belonging to a particular store (mapping to a single column family within an HBase table) are consolidated according to certain algorithms, as illustrated above. The blue bars represent new store files that are created when a memstore is flushed to disk, and the green bars represent compacted store files:
- Major compactions, whereby HBase attempts to combine all files for a store into a single file. I say “attempts to“, because if the resulting file exceeds the specified limit (defined by the property hbase.hregion.max.filesize), then HBase will split the region into two smaller regions. However, this split-region-when-compacted-file-reaches-max-limit rule is also subject to other factors (see next section).
The settings pertinent to compaction behavior are:
hbase.hstore.compaction.min (previously called hbase.hstore.compactionThreshold): the minimum number of files needed for a minor compaction, set to a default of 3 in HBase and Azure/HDInsight.
hbase.hstore.compaction.max: the maximum number of files considered for a compaction, set to a default of 10 in HBase and Azure/HDInsight.
hbase.hstore.compaction.max.size: any file greater than this will be excluded from minor compactions. Set to Long.MAX_VALUE in HBase but limited to 10GB in Azure/HDInsight.
hbase.hregion.majorcompaction: the time between major compactions in milliseconds. This defaults to 7 days in HBase, but is turned off in Azure/HDInsight.
hbase.hregion.max.filesize: when all files in a region reach this limit, the region is split in two. Set to a default of 10GB in HBase but to 3GB in Azure/HDInsight.
hbase.hstore.blockingStoreFiles: a Store can only have this many files; if the number is exceeded a compaction is forced and further writes are blocked. Set to a default of 10 in HBase but increased to 100 in Azure/HDInsight.
So why, in the diagram shown above, did we not have a minor compaction at point B, where we again had three files available to us in the store? The reason is that the compaction algorithm (ExploringCompactionPolicy in HBase 0.96 and later; RatioBasedCompactionPolicy previously) takes into account the differing sizes of file, and excludes from a compaction any file whose size exceeds the size of the other files in the compaction-set by a given ratio. This prevents the store from having files with largely divergent sizes. The full list of compaction-related parameters can be found on the official HBase website.
Phoenix Indices, Co-location and HBase splits
I mentioned earlier that it is beneficial to use Local indexes with Phoenix: this is particularly true for read-heavy environments. When local indices is defined on a table, all index data is stored in a single subsidiary table, named:
_LOCAL_IDX_[parent-table-name]
In the HBase master UI you will then see something like this in the table description:
‚SPLIT_POLICY‘ => ‚org.apache.phoenix.hbase.index.IndexRegionSplitPolicy‘
This class overrides RegionSplitPolicy in order to prevent automatic splitting:
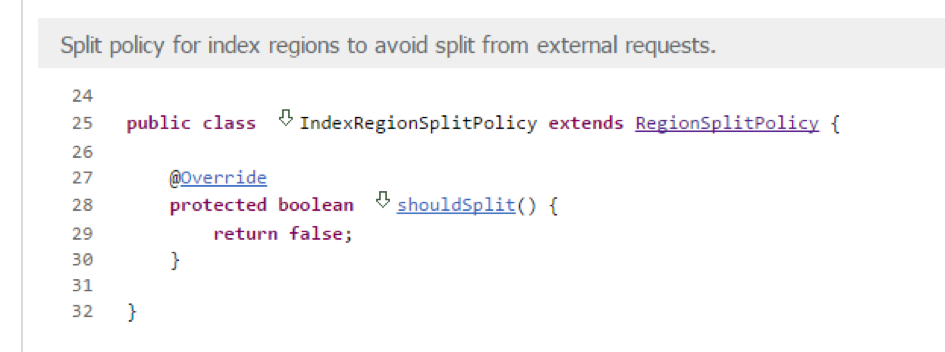
This may seem strange, but makes sense when one considers that local index data should be co-located with the parent data, meaning that the index table is only split when the parent table is split.
Azure Storage
Enter Azure Storage, another cog in the machine. This layer of abstraction introduces another factor: how to efficiently read from and write to the “blob“ objects that make up azure storage. Even though the Azure documentation states that a Blob may consist of up to 50,000 blocks, with each block having a default size of 4MB – meaning that with default settings we can write single files up to 200GB – this needs to be understood in the context of the default Azure HBase/HDFS settings (fs.azure.read.request.size and fs.azure.write.request.size), which sets the block size for read/write activity to 256 KB, for performance reasons. The side effect of this is that we can only read and write files to Azure Storage that do not exceed 50,000 x 256 KB = 12 GB.
Attentive readers may by now have a sense of impending doom: the HBase defaults are fine for the majority of cases, though these have been tweaked in HDInsight to avoid performance issues when reading and writing large files (abstraction #1). However, Phoenix – bundled with HBase in HDInsight – derives the most benefit from local indices when splitting is determined by the parent table, not the table holding the index data, and this is implemented (i.e. automatic splits are blocked) when a local index is created (abstraction #2). If we have several indices created on a table, then the index table may grow to be several times the size of the parent table, particularly if covering indices (when other columns other than those that form the index are stored along with the index) are used.
In our case, we were observing blocked splits on the index table (because splitting is determined by the parent table to ensure co-location), leading to store files that were too large to be compacted, resulting in exceptions like this:
regionserver.CompactSplitThread: Compaction failed Request = regionName=_LOCAL_IDX_[parent table name]…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
java.io.IOException at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:643) at com.microsoft.azure.storage.blob.BlobOutputStream.close(BlobOutputStream.java:280) at java.io.FilterOutputStream.close(FilterOutputStream.java:160) at org.apache.hadoop.fs.azure.NativeAzureFileSystem$NativeAzureFsOutputStream.close(NativeAzureFileSystem.java:869) at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72) at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106) at org.apache.hadoop.hbase.io.hfile.AbstractHFileWriter.finishClose(AbstractHFileWriter.java:248) at org.apache.hadoop.hbase.io.hfile.HFileWriterV3.finishClose(HFileWriterV3.java:133) at org.apache.hadoop.hbase.io.hfile.HFileWriterV2.close(HFileWriterV2.java:366) at org.apache.hadoop.hbase.regionserver.StoreFile$Writer.close(StoreFile.java:996) at org.apache.hadoop.hbase.regionserver.compactions.DefaultCompactor.compact(DefaultCompactor.java:133) at org.apache.hadoop.hbase.regionserver.DefaultStoreEngine$DefaultCompactionContext.compact(DefaultStoreEngine.java:112) at org.apache.hadoop.hbase.regionserver.HStore.compact(HStore.java:1212) at org.apache.hadoop.hbase.regionserver.HRegion.compact(HRegion.java:1806) at org.apache.hadoop.hbase.regionserver.CompactSplitThread$CompactionRunner.run(CompactSplitThread.java:519) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit. at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89) at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307) at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182) at com.microsoft.azure.storage.blob.CloudBlockBlob.commitBlockList(CloudBlockBlob.java:245) at com.microsoft.azure.storage.blob.BlobOutputStream.commit(BlobOutputStream.java:313) at com.microsoft.azure.storage.blob.BlobOutputStream.close(BlobOutputStream.java:277) ... 16 more |
Two independent sets of behavior – both abstracted enough away from view to be difficult to find – were working against each other.
Conclusion
In our situation we decided to keep major compactions turned off, and to only manually execute them in combination with temporarily increasing the azure storage settings (fs.azure.read.request.size and fs.azure.write.request.size). In this way we could rely on the minor compaction algorithm to keep the individual store files within the correct limit. However, we also discovered that there is often no substitute to rolling up your sleeves and seeking to understand the many and varied configuration settings, as well as wading through source code to gain a better understanding of such corner-case behavior.
Read on …
So you’re interested in processing heaps of data? Have a look at our website and read about the services we offer to our customers.
Join us!
Are you looking for a job in big data processing or analytics? We’re currently hiring!


