
In this blog post I would like to give a rough overview over the Apache Drill query engine. It describes the architecture of Drill, its capabilities as well as some problems using it. This post is meant for people that are currently at the stage of deciding whether to make use of the query engine in their daily work or not.
Apache Drill
Apache Drill is an open-source framework for data analysis and exploration that provides a flexible query engine. It was inspired by Google’s Dremel system which nowadays is part of the Google Cloud Platform infrastructure and better known as Big Query. However, Drill is the open-source version of Dremel and can be used with a variety of databases, cloud storage systems and all common Hadoop distributions like Apache Hadoop, MapR, Cloudera and Amazon EMR.
Just another query engine?
The need and requirements for flexible query engines are nothing special these days: data scientists, engineers and BI analysts often need to analyze, process or query a variety of different data sources. This requires the development of lots of ETL jobs, transforming the data to guarantee a consistent structure for making it accessible in any further step of the data pipeline e.g. machine learning tasks or reporting tools.
Apache Drill addresses this issue by providing the functionality to query data from different sources and systems, schema-free out of the box. Furthermore, it provides a fast and powerful distributed execution engine for processing queries.
It supports a variety of different NoSQL databases and file systems as well as data types that can be read and processed. The following table shows what is currently supported without any additional configurations.
| External systems and databases | Formats |
|---|---|
| Google cloud storage | CSV, TSV, PSV (or any other delimited data) |
| Amazon S3 | Parquet |
| Azure blob storage | Avro |
| Hbase | JSON |
| Hive | Hadoop Sequence Files |
| Kafka | Apache and Nginx server logs |
| HDFS | Log files |
| MapR-DB / MapR-FS | |
| Mongo-DB | |
| Open Time series database | |
| Nearly all relational databases with JDBC driver support | |
| Swift (OpenStack) | |
| NAS | |
| Local files |
For any additional data source, Drill provides the option to create so-called storage plugins. These can be defined as a JSON-formatted file which describes the new data source. For example: Drill expects .csv files to be comma separated. If you now have a file that is separated by semicolons, it could easily be defined as a .csv2 file in a storage plugin. The picture below shows how this can be done.
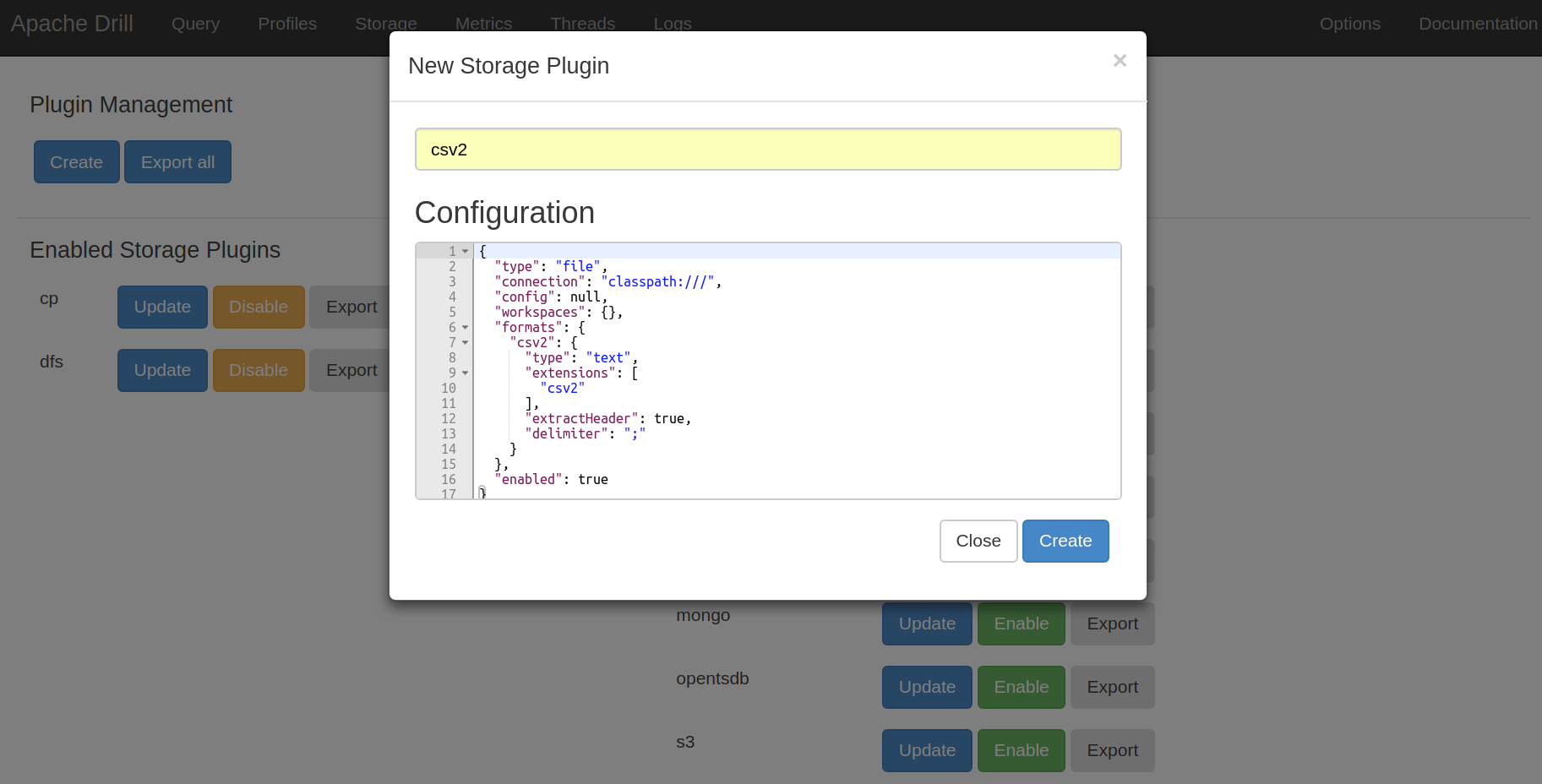
This means that you are really not limited by types of data and could potentially write a query, that reads a .parquet file from HDFS, join it with a hive table and union it together with data coming from MapR-DB (if these technologies are all in use in your company):
|
1 2 3 4 5 6 7 |
SELECT customer_id AS c_id FROM dfs.`/var/inla/tables/customers` c --MapR-DB LEFT JOIN `hive.dbo`.account ac --Hive table ON ac.customer_id = c.c_id UNION ALL SELECT d_customer_id FROM dfs.`/data/datahub/transactions` --Parquet file |
Cool!
Drill supports JDBC/ODBC so it can be used with any common IDE (e.g. DBeaver) or BI / analytics tool (e.g. PowerBI or Tableau) that leverages those drivers for developing queries and visualizing data.
That being said, the answer of the question in the header of this section is yes, Drill is just another query engine but provides a very high level of flexibility and variety in terms of the underlying database system, data types and formats.
Let’s see what can be done with this flexibility.
Basic overview of Apache Drill
In the previous section we saw the great advantage of Drill to handle various types of data in an easy way without causing much overhead. Besides the flexibility, Drill also claims to be easy to use in terms of installation and data preparation. There is no need to load the data and transform it before it can be processed by Drill, or to create and maintain schemas. Users can just query the raw data on nearly every system, regardless of the type. The rest is all handled by Drill itself.
Therefore, it provides a set of standard SQL functionalities to query the data. Tables can be created and deleted with create and drop statements. The same goes for views, using the replace statement. Drill supports common table expressions that will help you write complex queries. You can also partition tables by columns to make the load of a subset of data more efficient and reduce costs of your queries.
Drill also provides some advanced SQL functionalities such as flattening nested data. Because it is capable of reading hierarchical formats like JSON, it offers a flatten function that reduces complexity in nested data structures. By using flatten, you can break down arrays into distinct rows which makes queries more feasible and transforms the data in a way that fits better into a data warehouse structure.
Unfortunately, there is one shortage which I often missed when using Drill. Drill currently does not support the function to insert, update or delete rows. That means there is no direct way of modifying data that has been processed by Drill already. Every time we want to make changes to a persisted Drill table, we would need to delete the table entirely and create it again with our changed data. Especially when using Drill to run a data warehouse, it could get quite cost intensive when you need to recreate every table whenever new data is delivered.
That is the first point where we see that the flexibility of Drill comes at a cost. There is more to come at the end of this article but before that let’s have a short look at the architecture and how it can be set up.
Running Apache Drill in a productive environment
There are two possible ways of running drill: embedded and distributed mode. The embedded mode is preferably used for testing purposes as not much configuration is required. By launching the Drill shell in embedded mode, a Drillbit service is automatically started which is the main service of Drill to handle queries.
Drill offers some predefined scripts. After downloading the latest version, you just have to execute
|
1 |
$ bin/drill-embedded |
to enter the embedded mode. It opens an SQLLine shell on your local machine that enables you to run queries.
When running Drill in production, it is highly recommended to use Drill in the distributed mode to enable its full potential benefits. In this mode, drill runs on multiple nodes in a clustered environment. If the cluster is managed with YARN, Drill can also run as a YARN application. ZooKeeper is required when running Drill on multiple nodes, so that all Drillbits are able to find each other and also to handle the communication between Client and Drillbits. To lunch Drill in distributed mode you need to execute
|
1 |
$ bin/drillbit.sh start |
while ZooKeeper is running. By default Drill will use the configuration in the drill-override.conf file when starting it for the first time:
|
1 2 3 4 |
drill.exec: { cluster-id: "drillbits1", zk.connect: "zkhostname1:2181" } |
cluster-id describes that one instance is running at the moment and zk.connect needs the connection string to the running ZooKeeper server. These are default configuration entries. When configuring Drill for productional usage, this needs to be adapted.
Query execution

When a query gets executed by a client, it is sent to the Zookeeper quorum of Drillbits. One of the Drillbits accepts the query and therefore becomes the so called foreman for this specific query. For the whole following process, this Drillbit will remain as foreman and has the responsibility to manage the execution of the query. It starts with the creation of a logical plan by analyzing the query with the built in SQL Parser that is based on Apache Calcite. Then the query gets optimized which results in a most efficient execution plan. This execution plan also takes data locality on the cluster into account. Which is why it is recommended to have a Drillbit available on every single node in the cluster. The foreman knows through ZooKeeper about the availability and locality of every Drillbit and therefore is able to assign a various amount of fragments of the execution plan to each of them to maximize the performance. Every major fragment is divided into a few minor fragments that actually run the optimized SQL code on data slices. After this is done, the result is sent back to the foreman which collects all the outcomes of the other fragments and provides the final result back to the client.
Working with Apache Drill
Now that we know what Drill is capable of and how it is built and performs queries, it is time to speak about how these features perform in a real world scenario.
Let’s start with the biggest feature of Drill:
Maximum flexibility: both a blessing and a curse
As I already stated above, the great flexibility of Drill comes at a cost. That is not only true for some SQL functionalities but also for data sources: The great flexibility of Drill only applies as long as the queried data has the same structural characteristic. For instance, if you query a directory containing multiple JSON files that do not all contain the same hierarchical structure, Drill is not able to infer the schema for these files and fails by reading them. As a workaround, you would need to create data types out of the JSON files with fixed schema , e.g. parquet, to make Drill able to query the data which makes the whole advantage of Drill obsolete.
Another problem with the error-prone schema-on-read-approach of Drill is the missing data type definition for every column. Drill is defining those by itself when reading the data. Due to the splitting of data in several fragments during the query execution, it could happen that one of those fragments processes a data slice where one column is not filled with any data (NULL values). Drill interprets NULL values as Integer(!) by default. If another fragment has a data slice where the same column contains a String, the column will be handled as a string type within that fragment. When it comes to joining the query results together among all fragments, this would result in a schema change exception and failure of the whole query.
Performance tuning
For using Drill in a productive environment it is of special interest to know how performance issues can be handled when querying big data. Drill claims to be fast through distributed query execution on a cluster. But that is only true as long as enough resources are provided for Drill. The major problem here is that querying large amounts of data does not result in longer taking queries but simple failure in the execution of those. To prevent this, it needs to be ensured that each Drillbit has enough resources available. When using Drill on Yarn, this can be quite easily adjusted by changing the parameters in the drill-on-yarn.conf file:
- direct memory
- heap memory
- cache
If the basic adjustment of resources does not help or a sufficient amount of memory is already applied for a specific task but Drill still refuses executing the query properly, there is only one option left – which is the configuration of Drill.
Configure Drill by yourself – A bottomless pit
Before talking about configuration, let me introduce another feature of Drill here that I did non mention so far: The Drill Web UI.

The Web UI gets automatically started when Drill is launched in distributed mode. It offers the possibility to submit queries and view query details such as the execution plan, a query history and logs. Nothing too special so far, but there is also the options tab which offers the possibility to configure some advanced drill options. To be precise, in the current version (1.17.0) there are 214 configurable parameters which are in some cases briefly documented in one or two sentences and in others not at all. There is no other place where additional information is provided. At a first glance, the whole page appears to be a big black box and one could spend very much time on testing the effect of those parameters. I only looked at some of them as I especially had the most trouble with memory issues. So if you have the similar problems the following list might help you:
| Parameter | Description |
| drill.exec.hashjoin.fallback.enabled | Set this to true when you do large joins to disable a memory limit that Drill sets internally. |
| planner.memory.max_query_memory_per_node | This is the parameter that actually defines the maximum memory usage a query can take per node, make sure to increase this value if you run in any memory issues. |
| planner.memory.min_memory_per_buffered_op | Set this to a higher value than default to prevent memory exceptions (learned by experimenting). |
| planner.width.max_per_node | This parameter dramatically increases the performance of your queries as it enables parallel processing of your queries on a node. It is completely unclear to me why this is default set to 0. Of course it also increases memory consumption so make sure you have enough of that. |
| store.hive.parquet.optimize_scan_with_native_reader | Set this to true to enable an optimized reader for parquet files. Small increase of performance but also a bit buggy. |
| planner.enable_nljoin_for_scalar_only | This has not directly something to do with memory but needs to be enabled when joining on string data types. Of course this is not as fast as joining on numbers but sometimes necessary due to schema changes. |
| store.json.all_text_mode | Again not memory related but this parameter avoids schema change exceptions when reading JSON files by converting everything to string data types (which is not necessarily wanted but prevents the query from failing). |
Conclusion
Apache Drill is a tool with high ambitions but unfortunately cannot fulfill all of them. It tries to be the Swiss army knife of querying engines but falls flat on small but important things, which makes it hard to use in real world projects.
Besides the points mentioned above, there are still a couple of minor bugs, which is why I would not recommend using Drill in an IT project. For example, until recently, there existed a bug that produced wrong numbers in columns with decimal data types when tables were unified. Through the UNION the comma was shifted in those numbers producing completely false results. However, this has been fixed in the latest version. But still, when building up a data warehouse, this type of bug is not acceptable.
So, when does it make sense to actually use Drill? I would not say never, because it is true that Drill offers a high degree of flexibility. So whenever you have big data in a multi-node setup on-prem or in the cloud that is split into many different types AND you want to do ad hoc analysis / exploration of your data I would recommend to use Drill. When it comes to actual production usage, better switch to another tool.


