
In this blog post, we share our insights about Airbyte, an open-source data integration tool (ELT), which we gained in one of our projects.
Utilizing data to make informed decisions, optimize processes, and drive innovation is invaluable to almost any business. However, utilizing data is only half the battle. In some circumstances, the other half is integrating data from mostly heterogeneous sources into a central location. In these scenarios, one of the primary decision points is picking the proper tooling for data ingestion. While custom code data pipelines offer great flexibility and complete control, they typically come with an initial high development and maintenance cost. Data pipeline tools like Airbyte aim to make data integration easy, seamless, and reliable.
Airbyte was our tool of choice for the ingestion layer within our project that required us to build an entire data infrastructure on AWS. This blog post serves as an experience report. It highlights what we loved about Airbyte and what gave us headaches. First, it outlines the overall project setting and why we preferred Airbyte over other available data integration tools. Next, it examines how we deployed and used it, how it helped us ingest data from different sources, and which limitations we encountered throughout our extensive use of the tool.
Application scenario
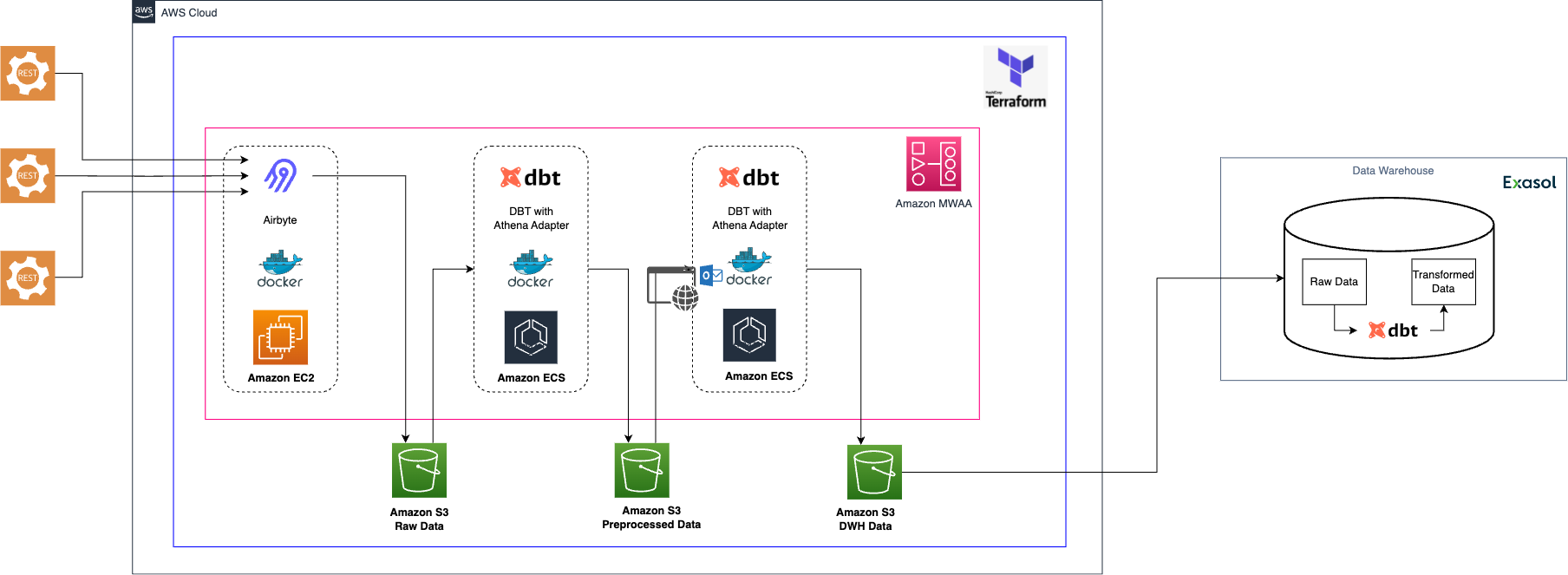
The client commissioned our team to set up a data infrastructure on AWS from scratch, primarily used for Business Analytics use cases. The goal was to design and implement a solution so that stakeholders, such as data scientists or different departments up to the management level, can access the data. Depending on the stakeholders, the data should be made available at different entry points: on AWS to access the raw data, as transformed data in the data warehouse, or as regularly updated reports and dashboards. From a high-level perspective, we needed to make decisions concerning data ingestion, storage, transformation, and serving/analytics. While this blog post focuses on the ingestion layer, the following paragraph provides a basic overview of the core architecture.
Regardless of the choice for the data ingestion layer, the data lake part was implemented with AWS services. We used S3 buckets as the storage layer. The data was stored in a columnar file format on S3. Columnar file formats such as Parquet offer significant advantages, especially in the amount of data that needs to be fetched by accessing only columns that are relevant to a workload. For the data warehouse, we used a SaaS solution called Exasol, an in-memory cloud database. Both on AWS and in the data warehouse, we used dbt (data build tool) for preprocessing and transformations of the data. On the AWS side, some minor corrections and checks are applied to the incoming data using dbt. On the data warehouse, dbt was used for the actual transformations and for implementing the analytics use cases. For the orchestration of our data pipelines, we used Amazon Managed Workflows for Apache Airflow (MWAA). To manage and deploy the entire cloud infrastructure, we used Terraform, an Infrastructure as Code (IaC) tool. Although additional services were used, especially for tasks such as governance and monitoring, they do not play a significant role in this context and are therefore not covered in more detail.
Criteria for a data ingestion tool
We defined a list of must-have and should-have characteristics for our ingestion tool to fit it into the overall scope of the project.
Mandatory requirements
The data we dealt with originated from several custom APIs with similar properties as well as some well-known sources like BigQuery and SalesForce. Hence, the tool of our choice should be able to connect all these sources and store them in S3 in a columnar file format such as ORC or Parquet. Since Python was used as the primary programming language throughout the project, the tool should also support Python unless it is a low-code or no-code application. We were a small group of developers and in the long run, other developers or maintainers would take over our code base. Therefore, we sought a time-efficient way to develop the ingestion layer while minimizing technical debt. To this end, we strongly emphasized keeping the development and maintenance costs as low as possible. Finally, for obvious reasons, the monetary costs associated with the ingestion tooling were another hard factor contributing to our decision-making.
Nice to haves
In addition to the aforementioned hard requirements, we identified some features that the tool should have. First, our ingestion layer should ideally be a standalone solution. It should function independently of other parts of our architecture. This was a request, but not a requirement, expressed by the client, which is why we did not define it as a hard requirement above. This modular approach should allow other teams to integrate parts of the data infrastructure as needed without adopting our entire architecture.
Our ingestion solution should also have an active community or, if it is a commercial solution, proper support so that we and potential future users can get help. Moreover, to be future-proof, we were also looking for an actively developed solution that receives updates and patches regularly.
Tooling options to consider
After an initial researching phase, we devised the following set of options. On the commercial side of tools, we considered FiveTran, Stitch, and AWS Appflow. These tools promise to ease moving data from source to target, offering a plug-and-play solution while being robust and fast. Furthermore, they provide templates or SDKs to develop custom connectors. In addition, they offer various pre-built source connectors and allow loading data to Amazon S3. In terms of open-source tooling, besides Airbyte, we also looked into Meltano. We had some time to experiment and evaluate these tools and hoped to find a solution with the lowest possible development and maintenance costs. Falling back on completely self-developed Python solutions was always an option we kept in mind in case the tools would not get the job done sufficiently or did not offer any significant advantage.
Why did we end up using Airbyte?
Our discussions about the proper tooling for data ingestion led us to discard commercial solutions early. They mostly charge the users based on the number of processed records, which makes them a costly choice. Moreover, these tools focus on connecting well-known sources in a plug-and-play fashion. Since our primary data sources were custom APIs, they did not match our use case well. Using the templates and SDKs offered by the tools seemed inconvenient and, in the case of FiveTran, even required us to use additional external cloud services such as AWS Lambdas to harvest data from custom sources. Finally, the fact that we would barely touch upon the features these tools mainly advertise with (i.e., the pre-built connectors) made the high financial burden seem unjustified.
Since we had already considered a custom-built solution as a fallback solution, the race was on between Airbyte and Meltano. Like the commercial tools, both solutions offer a wide variety of pre-built connectors or taps, as Meltano calls them. We gave both tools a shot and tested them on one of the custom APIs we had to connect. Both Meltano and Airbyte did the job. However, as one might guess, Airbyte convinced us slightly more. Developing custom Airbyte connectors was somewhat more intuitive and faster than building Meltano taps. Also, we had a better experience working with Airbyte’s documentation and tutorials than Meltano’s. For instance, Airbyte’s “Python CDK Speedrun: Creating a Source“ documentation is very straightforward and intuitive, and guides you through the process to build a simple HTTP API source connector step-by-step. While Meltano’s CLI is superior to the one Airbyte offers, Airbyte collects a few bonus points by providing a nice GUI. The latter lets you quickly spin up connections between sources and targets in a no-code fashion and provides monitoring and logging of active and past data syncs. Airbyte’s Amazon S3 target connector finally fixed our decision for the tool, as we found it more extensive and easier to handle than Meltano’s equivalent. It offers full refresh and incremental append sync modes and several output formats are available, including JSON Lines, Apache Avro, and, most importantly, Parquet. Regarding the latter, it supports several compression algorithms and lets you configure all sorts of Parquet-specific things like the size of a row group being buffered in memory or dictionary page size and encoding.
How we used Airbyte
After deciding on Airbyte, it was time to consider how to deploy the tool as part of our architecture. Airbyte offers Airbyte Cloud, a fully managed and scalable version of the tool. However, we had to refrain from utilizing it because Airbyte Cloud was not available but only announced for Europe during the scope of our project. However, the main argument against using Airbyte Cloud was the lack of support for custom connections. Accordingly, we opted for a self-hosted solution. Specifically, we deployed Airbyte on an EC2 instance, a virtual machine on AWS, which we booted up and configured using Terraform. Deploying Airbyte to the EC2 instance was pretty straightforward, using the docker-compose file provided through Airbyte’s GitHub repository and setting some environment variables. Once the container was up and running, the Airbyte service as well as UI was ready to go.
Once Airbyte was up and running, we wanted to develop and deploy custom connectors for our data sources. Airbyte offers a Connector Development Kit (CDK) for Python-based connectors, which generates most of the required code for you. The CDK abstracts low-level boilerplate code and provides a basic implementation structure for connectors using uniform code structures. Indeed, creating source connectors for our custom APIs was pretty straightforward using the CDK. It provides predefined classes and methods for various authentication types, pagination, reading and parsing responses, and handling states for incremental streams. The pre-built Amazon S3 destination connector we used to write the source data to Parquet had some peculiarities we had to consider. First, the Parquet-writer had no handler to process null values in arrays; this is fixed in the latest connector version, though. Hence, we had to replace these null values when parsing the data using our custom source connector. Second, HTTP API connectors built using the CDK require you to provide JSON schemas describing the parsed data’s structure. If an API does not provide them at all or they are not of sufficient quality, generating or fixing them can be tedious and hacky. However, if a connector writes to a blob storage (such as AWS S3) in Avro or Parquet file format, Airbyte automatically writes fields not represented by a schema to an additional column. Some will like it, others will hate it. We found this very handy as it allowed us to do simple schema checks after a connector sync, notifying us when non-breaking fields were added to an API. The Airbyte docs have described this behavior.
To use the Airbyte connectors, they must be provided as Docker images and imported to the Airbyte instance. Since the CDK auto-generates the corresponding Dockerfiles, providing the image is straightforward. We leveraged a combination of GitLab CI/CD, AWS Elastic Container Registry (ECR), and Airbyte’s API to automate the deployment. Specifically, we used a CI/CD pipeline to achieve the following: First, the pipeline builds and pushes a new Docker image from our connector’s repository to a Terraform-provisioned Amazon ECR repository. Next, using SSH, the CI runner connects to the EC2 instance and pulls the image from the ECR repository. Finally, it sends a bunch of POST requests to the Airbyte API to add the connector to the available sources and set up a connection between the source and destination. We also configured all Airbyte connections to only run when manually triggered, so we could orchestrate them using Airflow and its Airbyte operator. Airbyte allows you to schedule syncs based on time intervals, though, so that it can function as a standalone application. In our case, we used the aforementioned Airflow service as our single and central orchestrator, especially since we had subsequent tasks that relied on successful Airbyte syncs. As we run each Airbyte connection sync once a day, the EC2 instance on which Airbyte is deployed is also managed via Airflow and is booted up for the synchronizations and then shut down again.
Key findings, strengths, and weaknesses
Over the course of several months, we have used Airbyte for our ingestion tasks, built a bunch of custom connectors, and synced millions of records from several heterogeneous sources. All in all, Airbyte is a good working solution. In a very short time, we were able to work with Airbyte in a productive environment. The setup and deployment of Airbyte and our custom connectors were mostly straightforward. The Airbyte documentation and tutorials were of great help here too. It was relatively easy for us to understand how Airbyte works internally and how we can build and deploy our own connectors. One thing we particularly want to highlight is the active Airbyte community. People are contributing to the project and the connector landscape via issues and pull requests on GitHub. Airbyte’s Slack channel is also a good place to get help quickly.
However, in some scenarios, we encountered some minor and major problems. It became clear that we were working with a product that is still in an active development phase. One thing that caused us some real headaches is the fact that the Airbyte Python SDK does not provide a way to set the batch size for a custom source connector. Airbyte always reads up to 10,000 records from the source before writing them to the target. This is a known problem, as this GitHub issue also highlights. Some of our sources had a high data density and used paginated results to serve the data. This inevitably led to memory issues on our Airbyte instance. Although one could scale the infrastructure and increase the memory, this is just a workaround and not a solution. We eventually worked this out by implementing some logic around Airbyte. However, one has to take this limitation into account when using Airbyte with highly dense data sources.
We have encountered additional minor problems with Airbyte. For example, the Airbyte API’s documentation differed from its actual behavior for certain endpoints. Moreover, several version updates intended to provide patches resulted in unexpected errors. Therefore, at some point, we stuck with a specific version that worked best for us and refrained from updating it unless we encountered a problem with our current version.
Conclusion
In this blog post, we shared our experience working with Airbyte, an ELT tool, in a project where we had to develop a data ingestion solution for several heterogeneous data sources. We highlighted why we chose Airbyte over other solutions, what we expected from the tool, and what strengths and weaknesses emerged during its use. Overall, it can be said that Airbyte is a good working solution that met our expectations in many areas. Although we encountered some challenges, we had a great experience working with it overall. For batch jobs with small to moderately large amounts of data, Airbyte works excellently. It has its built-in orchestrator which is also capable of notifying users about failed and successful synchronizations using webhook URLs, making it a feature-rich, standalone solution for data ingestion scenarios. The Connector Development Kit is a nice framework that allows you to create custom connectors from scratch without having to worry much about Airbyte specifics. One should consider getting a brief understanding of Airbytes resource requirements and limitations. There is a great documentation page about it, which helps to decide whether or not to use Airbyte for a given use case.
Our experience with Airbyte has proven the ELT tool worthy of consideration for data integration tasks under certain conditions as described above. Developing custom connectors and using them in production was fast and straightforward, given our use case. However, Airbyte still has quite some room for improvement, and we encountered several limitations. Since the tool was still in the alpha phase at the time we used it, we do not want to be too hard on it, though, and are curious to see what future versions will bring.


