
Notice:
This post is older than 5 years – the content might be outdated.
Differential Privacy is a topic of growing interest in the world of Big Data. It is currently being deployed by tech giants like Google and Apple to gain knowledge about their users, without actually collecting data about individuals. In this blog, I’ll explain some of the basic concepts of differential privacy and talk about how I’ve used it in my Bachelor’s Thesis written in cooperation with inovex, supervised by the co-author of this text, Hans-Peter.
Anonymization
One of the most common tools to quell concerns about privacy in a Big Data context is anonymization of the data, that is, changing the data to make it impossible to identify individuals using it. So, all we should need to do is remove the obvious identifying information from our data like names, addresses, phone numbers, and the data should be anonymized – right?
It turns out it’s not that simple. It has been demonstrated multiple times that databases which seem intuitively anonymous can be surprisingly easy to link to real-life identities: privacy researchers have succeeded in re-identifying many public “anonymous“ databases, from public health records (by comparing the zip code, gender, and birth year to public voting records) to Netflix ratings (by cross-referencing IMDB ratings) to browser histories (by simple examination of URLs visited). The harm that is posed by de-anonymization is very real: Netflix was sued in 2009 for releasing its ratings database.
In response to this problem, researchers have been looking at ways to mathematically guarantee anonymization. One such method is a mathematical criterion known as differential privacy.
Differential Privacy
Differential privacy was introduced by Cynthia Dwork at Microsoft in 2010. It describes algorithms which act on databases with a randomized output that does not depend too much on any individual entry. More exactly: If we have an algorithm which takes a database as its input, we say that the algorithm is ϵ-differentially private if changing one entry in the database does not make any possible output more than ϵ times more likely. As a result, ϵ defines how much the probability distribution of our algorithm is allowed to change if we change one entry.
If we only allow untrusted analysts access to the output of a differentially-private algorithm, we achieve a level of protection for individuals since no individual answer can have a definitively identifiable effect on the information received by the analyst.
Randomized Response
One basic and illustrative method to achieve differential privacy is known as randomized response. Say a researcher wants to survey individuals on an embarrassing subject, with a question such as “Have you ever driven while under the influence of alcohol?“ To encourage participants to be honest, the researcher can ask them to flip a coin: if heads, the respondent answers honestly. If tails, they flip the coin again and answer randomly: “yes“ if heads, “no“ if tails. The coin flips are kept secret from the surveyor.
This creates a plausible deniability for any respondent: Even if an attacker gains access to the results and sees that a certain person answered “Yes,“ they still cannot reliably conclude that the person has driven under the influence of alcohol; however, looking at all of the results put together, it is easy to estimate the true proportion of positive responses. And, it can be shown that this method is ln(3)-differentially private.
What makes randomized response interesting is that it is not only applied to the entire database, but can already be applied to an individual answer: if a user device applies the randomized response procedure before submitting an answer to a query, then no one outside of the user ever needs to gain knowledge of the true data.
In my thesis, I examined an application of randomized response which expands its capabilities beyond answering “Yes“ or “No“ questions by allowing users to respond in histogram form: By indicating a series of buckets along with a query, the user can answer with a series of 0s and 1s that each indicate which bucket their answers belong to. By applying randomized response to each bit, we can achieve differential privacy and, after collecting all results, estimate the actual frequency of each bucket. Adding a random sampling step augments the differential privacy effect. This method was proposed by Do Le Quoc in 2017 (see Further Reading). The diagram below visualizes the procedure, showing how each device calculates and submits a “fuzzy“ answer:
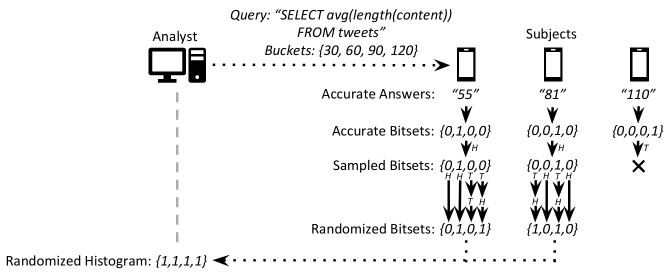
In my thesis, I worked to fine-tune this method by theoretically characterizing the variance of the result, optimizing randomization parameters to give the most accurate estimate possible, and implementing an algorithm capable of handling multi-column queries using randomized sampling and response, expanding the possible applications of randomized response for more complex examinations of relationships and sequences of events. If you’re interested, you can find a link to the full thesis below.
Further Reading
- Algorithmic Foundations of Differential Privacy, Cynthia Dwork, 2014
- “Privacy Preserving Stream Analytics: The Marriage of Randomized Response and Approximate Computing“, Do Le Quoc, 2017
- My Thesis in full text
Join us!
These are some of the results of my Bachelor’s Thesis I wrote at inovex. If you’re interested in anything Data Management & Analytics join us as a working student or write your Thesis in Karlsruhe, Munich, Cologne or Hamburg.


