
Distributed systems are hard – not because individual machines are hard to understand, but because machines can be correct and still disagree about some part of reality.
If multiple machines are responsible for a shared state, they need to make one coherent decision instead of several conflicting ones. They need to agree on who the leader is, which write happened first, whether a lock was acquired, or which configuration is current.
That problem is called consensus – it is not a protocol or an implementation detail, it is the foundation that allows distributed systems to behave as if there were one reliable source of truth. Even though the system is built from unreliable parts.
Consensus-based decision making is not originally a computer science idea; people use consensus to let groups reach decisions without relying on a single authority. Both people and machines rely on consensus to move beyond individual viewpoints and coordinate toward outcomes that serve the greater good of the system or community.
The Fundamental Problem of Distributed Systems
The hard question is: How can a group of machines make one correct decision when every machine may have only a partial, outdated, or contradictory view of reality?
Machines do not work perfectly all the time. A message may look lost, but actually arrives later. A leader may look unavailable to a partition of machines due to a network partition, but might still be recognized as a leader to another partition of machines. A node may look failed, but actually be slow. What if multiple machines think they are the leader? What if a machine lies about its own state? All these problems and many more concern the field of consensus.
Thus, to be more precise, the fundamental problem of distributed systems is to design and build reliable systems in the presence of a number of faulty processes and system components.
But “faulty“ is a broad term. Before we can talk about how distributed systems tolerate faulty processes and components, we need to clarify what can actually go wrong: the difference between faults, errors, and failures.
Fault
A fault is the underlying cause of a problem. It could be a bug, a hardware defect, a software or hardware misconfiguration, a corrupted disk, or a network issue.
Error
An error is the incorrect internal state caused by a fault. At this point, the system has not necessarily failed externally, but some part of its state or assumptions is already incorrect. For example, a node might believe that a healthy peer has failed, or it believes that it is connected to the wrong cluster member, or that its local state diverges from the leader’s state.
Failure
A failure is the externally visible consequence: the system no longer provides the expected service. It might reject valid requests, become unavailable, or violate a consistency guarantee.
To sum up, a fault is the cause of a problem, an error is the invalid internal state caused by that fault, and a failure is the externally visible deviation from the system’s expected behavior.
From a Single etcd Node to a Consensus Cluster
Simple but Fragile
Up to this point, we have discussed consensus mostly in abstract terms. To make the problem more concrete, let’s look at a system that many engineers are familiar with: Kubernetes and its backing store, etcd.
In Kubernetes, etcd acts as the control plane’s source of truth. It contains information about the workload running on the cluster, which nodes are part of the cluster, how services are configured, what secrets and configuration objects exist, and much more information. Basically, etcd is the long-term memory of Kubernetes’ brain.
The Kubernetes API server reads from and writes to etcd whenever the desired or observed state of the cluster changes. It is the place where the control plane records the decisions that define the cluster. But in principle, etcd is just a durable key-value database.
Suppose we run our Kubernetes cluster with a single etcd instance: one process on one machine. This is simple to understand and operate, but it is also fragile because the control plane now depends on the availability of a single machine, disk, process, and network path.
To improve this setup, our first goal is to increase process resilience: the system’s ability to continue operating when individual processes fail and to recover when failures occur. One way to achieve this is to replicate the service across multiple processes instead of relying on a single instance. Replicated processes can be organized in different ways. Two common models are hierarchical groups and flat groups.
Before we continue our journey from a single etcd process to a resilient etcd cluster, let us clarify a few terms. We have already mentioned hierarchical groups, flat groups, members, and leaders; these concepts will become important once the replicas have to coordinate with each other.
Process Resilience
In a hierarchical group, one process acts as the coordinator or leader, while the others follow its decisions. In a flat group, all processes are peers and participate more equally in decision-making.
etcd’s design goal is to provide a reliable, strongly consistent store for critical system state. Thus, the hierarchical model is especially relevant for etcd because systems relying on etcd require strong consistency. By using a leader, the cluster has a single coordination point of writes, allowing all members to agree on one uniform order of decisions.
Member and Leader
A member is one of the etcd processes that belongs to the cluster. A leader is a specific member that is currently responsible for coordinating decisions. For now, these loose definitions are enough. We will refine them later when we look more closely at specific consensus protocols.
Consensus
But to come back to our improvement, replicating the etcd process only improves resilience if the replicas do not share the same failure domain. If all etcd members run on the same machine, a machine failure still takes down the entire cluster. To tolerate machine-level failures, the replicated members must be distributed across different machines.
And this is where problems start to become bothersome – once the etcd members run on different machines, they can no longer coordinate through local memory or local process communication. They must communicate over the network, which is an inherently unreliable infrastructure component: messages can be delayed, duplicated, lost, or reordered.
At the same time, each etcd member now stores its data on a separate disk. That means the cluster no longer has one physical copy of state, but multiple copies that must be kept consistent. Without coordination, those copies could diverge and represent different versions of the cluster state.
Humans have faced a similar problem for a long time: once decisions are made by a group rather than a single authority, the group needs a reliable way to record what was agreed. Leslie Lamport captured this idea in his Paxos allegory, where part-time parliamentarians had to maintain consistent copies of parliamentary records despite absent legislators and unreliable messengers. Without consistency, different members could act on different versions of what the parliament had decided.
This is how Leslie Lamport introduced Paxos, one of the foundational consensus algorithms in distributed systems. It first appeared as a research report and was later published in 1998 as “The Part-Time Parliament“.
Although Paxos became one of the most important consensus algorithms, it is also famously difficult to understand and implement correctly. Its full specification leaves room for interpretation, and real-world implementations often differ in the details. Nevertheless, Paxos became the foundation for a family of related protocols, including Multi-Paxos, Cheap Paxos, and Fast Paxos, each optimizing for different assumptions and tradeoffs.
This complexity eventually motivated a different approach: Raft. In 2014, Diego Ongaro and John Ousterhout developed Raft which was designed with understandability as an explicit goal. Instead of presenting consensus as a set of subtle rules, Raft decomposes the problem into clearer parts: leader election, log replication, and safety guarantees. If you would like to read more about Raft in detail, read this extended version of the original paper.
Raft is a leader-based consensus algorithm. At any point in time, one member acts as the leader, while the other members act as followers. The leader coordinates writes and is responsible for making sure that all committed changes are replicated in the same order.
When a client wants to change state, the request is handled through the leader. The leader turns the change into an entry in its log and sends that entry to the followers. Once a majority of members has acknowledged the entry, the leader marks it as committed. From that point on, the change is considered durable and can be applied to the system state.
Raft does not just replicate data; it replicates an ordered log of decisions. If every member applies the same committed log entries in the same order, they end up with the same state.
For etcd, this means that Kubernetes control plane changes are not merely copied between nodes. They are ordered, replicated, and committed through Raft, so the etcd cluster can expose one strongly consistent view of cluster state.
If the leader fails, the followers can elect a new leader, as long as a majority of members is still available.
Quorum
The phrase “a majority of members“ is important enough to give it a name: a quorum. In etcd’s Raft-based consensus, a quorum is the minimum number of members that must agree before the cluster can safely make progress.
For a three-member etcd cluster, the quorum size is two (see figure 1). This means the cluster can tolerate one failed member: if one member goes down, the remaining two can still agree on changes and continue operating. But if only one member remains available, the cluster has lost quorum and must stop accepting writes because it can no longer distinguish a safe decision from a conflicting one.
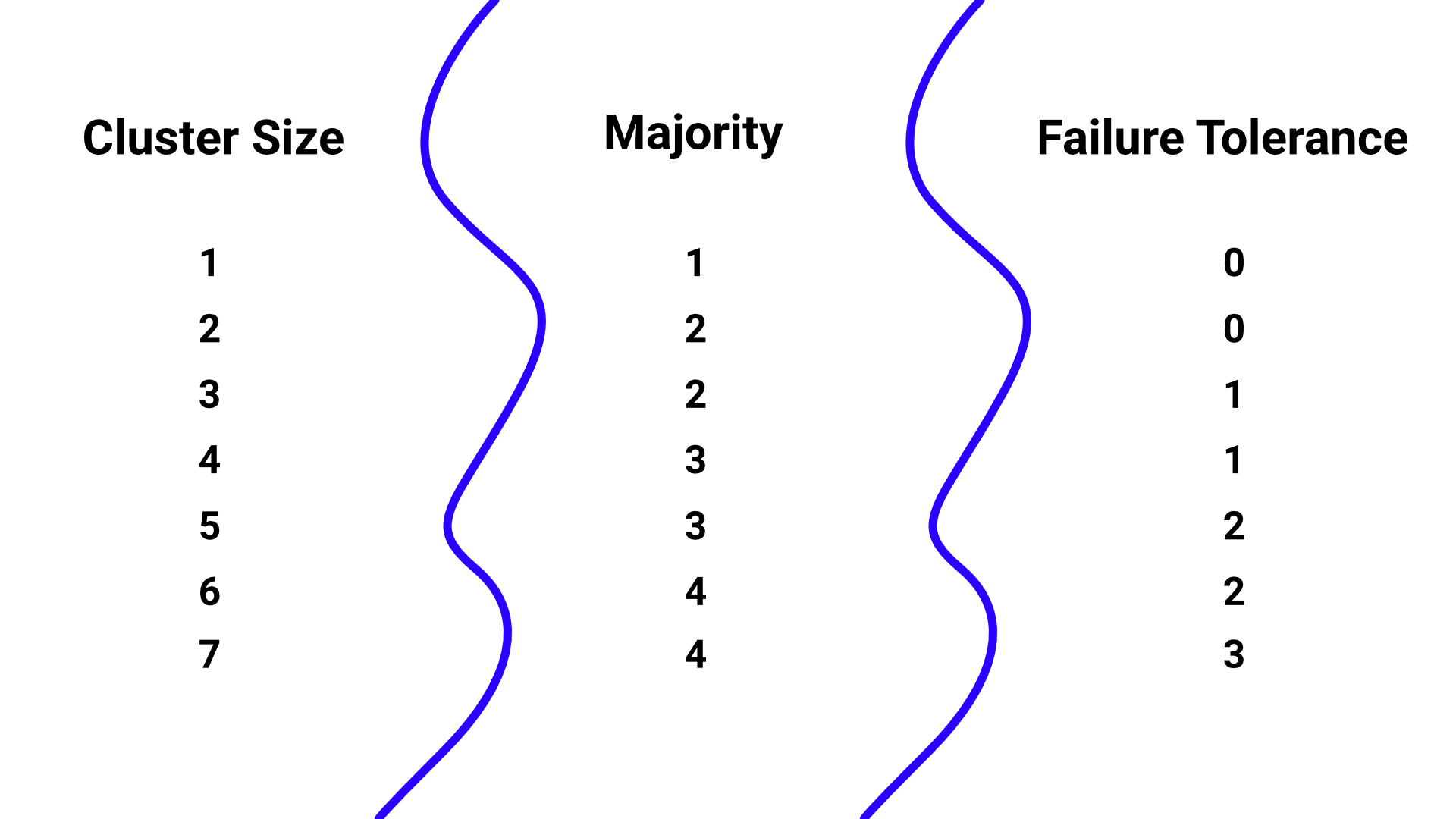
This is how the cluster can continue operating even when the individual members fail. Important to note is the fact that etcd clusters are commonly deployed with 3, 5, or 7 members. A three-member cluster can tolerate one failed member, a five-number cluster can tolerate two, and a seven-member cluster can tolerate three. Increasing the number of members improves failure tolerance, because the cluster can lose more machines while still preserving quorum.
However, more members do not come for free. There is no free lunch. Every write still has to be replicated to enough members to reach quorum. A larger cluster means more network communication, more disk writes, more coordination overhead, and often higher latency. Beyond seven members, the additional failure tolerance is usually not worth the performance and operational cost.
A common source of confusion that we want to mention is that quorum is based on the configured cluster size, not on the number of currently healthy members. A five-member cluster requires 3 members for quorum, so it can tolerate 2 failures. If 2 members fail, the remaining 3 members are not treated as a new three-member cluster with a quorum of 2.
The reason it works in this way is quorum intersection: any two majorities in the same cluster must overlap in at least one member. Two majorities means two different groups of nodes that are each large enough to form quorum. This overlap prevents two independent groups of members from safely committing conflicting decisions. This idea is older than etcd and Raft. David K. Gifford’s 1979 paper “Weighted Voting for Replicated Data“ is a useful reference for readers who want to understand the deeper reasoning behind quorum systems.
etcd shows why consensus is necessary in practice: once critical control-plane state is replicated across multiple machines, the replicas must not merely store copies, but agree on one ordered history of changes. Raft, leaders, and quorums are the mechanisms that let etcd survive individual failures while still protecting Kubernetes from conflicting sources of truth.
It is important to note that Raft, and therefore etcd, assumes crash faults, not Byzantine faults. In other words, members may crash, restart, become unreachable, but they are not expected to lie, or send conflicting messages intentionally. Handling Byzantine behavior requires different consensus protocols and usually comes with significantly higher complexity and cost.
FLP Theorem of Distributed Systems
So consensus works – but only under certain assumptions. In 1985, Michael Fischer, Nany Lynch, and Michael Paterson described a model of distributed computation that showed a surprising limit: in a completely asynchronous system, no deterministic consensus protocol can guarantee progress if even a single process may crash.
This result became known as the FLP impossibility theorem. It does not mean that consensus is useless or impossible in practice. It means that consensus protocols depend on assumptions about the system they run in. For example, assumptions about failure detection, timing, retries, or leader election.
In practice, Raft uses timeouts, heartbeats, leader election, and majority quorums. If followers stop receiving heartbeats from the leader, they eventually assume that the leader may have failed and start a new election.
This means Raft can make progress when the network eventually behaves well enough for messages to be delivered within a reasonable time. Let us be pessimistic and assume the network becomes permanently partitioned; Raft preserves safety by refusing to commit new writes rather than risking conflicting decisions.
Kafka: Another Place Where Consensus Shows Up
Kafka is usually known as a distributed log for application data, but the Kafka cluster itself has also critical metadata: brokers, topics, and partition leaders.
Older Kafka deployments used ZooKeeper to coordinate this metadata. ZooKeeper is a dedicated cluster of members which uses its own consensus protocol, Zab, to keep its replicated state consistent.
Newer Kafka versions move this responsibility into Kafka itself with KRaft, Kafka’s Raft-based metadata quorum. For more details, have a look at KIP 500.
Final Remarks
Consensus is not an abstract problem reserved for distributed-systems papers. It appears whenever multiple machines must act as one reliable system while failures, delays, and partitions are still possible.
This is why systems like Kubernetes, Kafka, and many databases rely on consensus somewhere in their chain.
But consensus is not free. It adds coordination overhead, depends on the majority quorum, and may sacrifice availability when the system cannot make a safe decision. That is the price of preserving correctness.
It does not hurt to know at least a little about consensus because much of our modern world relies on distributed systems. Every time we use cloud platforms, databases, messaging systems, or large-scale online platforms, we depend on machines agreeing with each other behind the scenes.
I hope you found this article useful! See you in the next one!

