
Diese dreiteilige Artikelserie bildet ein Tutorial für KubeEdge, in dem die Technologie erklärt und anhand eines Anwendungsbeispiels näher beschrieben wird. In diesem ersten Teil gehe ich näher auf den Aufbau und die Funktionsweise von KubeEdge ein.
Was ist Edge Computing
Edge Computing ist eine offene IT-Architektur, welche beim Mobile Computing oder im Internet of Things (IoT) (oder bei Industrial Internet of Things (IIoT)) eingesetzt wird. Das Ziel von Edge Computing ist die Reduzierung der Latenz und des Datenvolumen. Zur Umsetzung dieser Ziele wird die Datenverarbeitung bereits zum Teil auf den erhebenden Geräten selbst durchgeführt oder auf lokale Systeme. Die vorverarbeiteten Daten werden dann für zentrale Analysen in ein zentrales Cloud System gesendet. Ein weiteres Ziel ist die Unabhängige Funktionalität von Edge Rechenzentren ohne zentrale Kontrollinstanz. Bei dem Beispiel IIoT wäre es denkbar unvorteilhaft wenn eine smarte Fabrik nur arbeiten kann wenn diese auch mit dem zentralen Cloud System kommunizieren kann.
In diesem Use-Case werden die Daten direkt am Sensor aufbereitet und in einer entsprechenden Form direkt an die KubeEdge MQTT API gesendet.
KubeEdge
![]()
Im Dezember 2018 wurde KubeEdge von Mitarbeiter:innen des Unternehmens Huawei in der Version v0.1 unter der Apache 2 Lizenz veröffentlicht [1]. KubeEdge leitet sich aus den Namen Kubernetes und Edge ab und ist wie bereits Kubernetes in der Programmiersprache Golang (oder kurz Go) geschrieben.
Über das vergangene Jahr wurde vor allem die Cloud-Komponente verallgemeinert, sodass diese nicht nur mit der Huawei-Cloud kompatibel ist. Es sind aber auch weitere Teile, wie einige Device Mapper für die Device-Schnittstelle zu KubeEdge oder ein Installationsprogramm, hinzugekommen. Die hier beschriebenen und genutzten Prozesse sind bereits seit der Version v0.3.0 in KubeEdge implementiert. KubeEdge ist aktuell als Sandbox-Projekt bei der Cloud Native Computing Foundation (CNCF) registriert. Die CNCF ist eine Tochter der Linux Foundation. Die KubeEdge Community ist offen für weitere Anwendungsfälle die mit KubeEdge gelöst werden können. Um die Grundlagen von KubeEdge besser zu verstehen, geht der nächste Abschnitt näher auf die grundlegende Funktionalität von Kubernetes ein.
![]() Kubernetes wurde initial 2014 als Open-Source-Projekt veröffentlicht und hat sich seitdem zu einem De-facto-Standard für Container-Orchestrierung entwickelt. Ein Kubernetes Cluster übernimmt hierbei das Life-Cycle-Management von Applikationen im Cluster. Zum Life-Cycle-Management gehören neben dem Instanziieren von Applikationen auch das Überprüfen, ob diese noch funktionsfähig sind. Unter dem Begriff Autoscaling bietet Kubernetes die Möglichkeit, auf unterschiedliche Lasten zu reagieren und so weitere Instanzen einer Applikation zu erstellen – oder diese bei Bedarf wieder zu löschen. Der Kubernetes Scheduler, die Komponente die die Applikationen im Cluster verteilt, ermöglicht, die Applikationen anhand von Affinitätsregeln zu verteilen. Ein einfaches Beispiel für eine Affinitätsregel ist die Zuordnung einer Applikation zu Rechenknoten, die eine GPU verbaut haben.k
Kubernetes wurde initial 2014 als Open-Source-Projekt veröffentlicht und hat sich seitdem zu einem De-facto-Standard für Container-Orchestrierung entwickelt. Ein Kubernetes Cluster übernimmt hierbei das Life-Cycle-Management von Applikationen im Cluster. Zum Life-Cycle-Management gehören neben dem Instanziieren von Applikationen auch das Überprüfen, ob diese noch funktionsfähig sind. Unter dem Begriff Autoscaling bietet Kubernetes die Möglichkeit, auf unterschiedliche Lasten zu reagieren und so weitere Instanzen einer Applikation zu erstellen – oder diese bei Bedarf wieder zu löschen. Der Kubernetes Scheduler, die Komponente die die Applikationen im Cluster verteilt, ermöglicht, die Applikationen anhand von Affinitätsregeln zu verteilen. Ein einfaches Beispiel für eine Affinitätsregel ist die Zuordnung einer Applikation zu Rechenknoten, die eine GPU verbaut haben.k
KubeEdge baut auf der Funktionalität von Kubernetes auf und erweitert bzw. modifiziert diese für Anwendungsfälle auf Edge-Knoten. KubeEdge selbst ist dabei in verschiedene Komponenten aufgeteilt (siehe: Komponenten). Die zentrale Cloud-Komponente, die für das Management der Edge-Knoten benötigt wird, kommuniziert mit dem API Server eines Kubernetes Clusters. Der notwendige Kubernetes Cluster kann auch für das Hosten der KubeEdge Cloud-Komponente verwendet werden. Durch die starke Integration von Kubernetes in KubeEdge können Anwender:innen die gängigen Kubernetes-Kommandozeilenbefehle nutzen. Zudem bietet KubeEdge dadurch die Möglichkeit, die Standard-API-Ressourcen von Kubernetes, wie z. B. Pods und Deployments, wie gewohnt zu verwenden.
Kubernetes unterstützt seit der Version 1.7 das Erstellen von eigenen API-Ressourcen mithilfe von sogenannten „Custom Resource Definitions“ (CRD). Um KubeEdge in allen Teilen nutzen zu können, müssen eigene CRDs im Cluster vorinstalliert werden. Die CRDs werden im weiteren Verlauf des Artikels beschreiben.
KubeEdge und Kubernetes
KubeEdge hat sich bewusst dafür entschieden, eine starke Kubernetes-Integration anzustreben, um so von der Funktionalität von Kubernetes zu profitieren. Der deklarative Ansatz von Kubernetes bietet die Möglichkeit, immer einen Abgleich zwischen Ist- und Soll-Zustand zu machen. Falls bei diesem Vergleich Unterschiede identifiziert werden, kümmert sich Kubernetes darum, den gewünschten Ist-Zustand wieder zu erreichen. Durch den deklarativen Ansatz kann eine Entkopplung der Kubernetes-internen (und -externen) Komponenten erreicht werden. Der Ausfall einer Komponente muss damit nicht sofort Auswirkungen auf die Applikationen in dem Cluster haben. So können die Kubernetes-Knoten z. B. selbständig weiterarbeiten – auch wenn der API Server nicht erreichbar ist. Dieses Verhalten ist in Edge-Umgebungen sehr hilfreich, da dort meistens keine stabile Netzwerkverbindung vorhanden ist oder auf den Mobilfunk zurückgegriffen wird.Ein weiterer Vorteil der Entkopplung einzelner Komponenten ist ihre Austauschbarkeit. KubeEdge macht von diesem Architekturansatz gebrauch und implementiert einige Komponenten anders, als es die Kubernetes-Standardimplementierung für diese Komponenten vorsieht.
Komponenten
In diesem Abschnitt erkläre ich die Grundlagen von KubeEdge und dessen Aufbau. Als Übersicht und Orientierungshilfe arbeiten wir uns an dem Architekturbild von KubeEdge (Abbildung: Architektur KubeEdge) entlang.
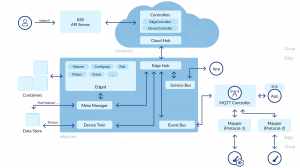
Cloud-Komponenten
Die Cloud-Komponente muss so ausgeführt werden, dass sie über HTTP oder HTTPS auf den Kubernetes API Server zugreifen kann. Um die Verbindung zu konfigurieren, wird die Kubernetes Config verwendet. Lässt man den CloudCore in einem Kubernetes Cluster laufen, kann die Erstellung der Kubernetes Config von dem Cluster selbst übernommen werden. In unserem Use Case wird diese Variante verwendet und ein Service Account generiert – und damit implizit auch ein Access Token. Man kann aber auch eine User-Password-Kombination verwenden. Bei der Verwendung von Role Based Access Control (RBAC) kann dem CloudCore eine eingeschränkte Rolle zugewiesen werden.
Im Konzept von KubeEdge übernimmt der CloudCore die Funktionalität eines Verbindungspunktes, der über einen Cloud Hub mit den Edge Nodes kommuniziert.
Diese Kommunikation kann entweder über das Websocket-Protokoll, HTTP(S) oder über Quick realisiert werden. Die Informationen, die vom Edge Node über den Cloud Hub kommen, werden an die beiden Controller weitergegeben. Die Hauptaufgabe der Controller ist es, die Informationen zwischen den Kubernetes-Ressourcen und den Edge Nodes zu synchronisieren. Der DeviceController übernimmt dabei die Aufgabe, die Device- und DeviceModel-Ressource zum entsprechenden Edge Node zu synchronisieren. Der EdgeController synchronisiert die Edge-Node-Informationen, wie die Auslastung des Edge Nodes oder welche Pods auf dem Edge Node gestartet werden sollen.
Wie bereits mehrfach angedeutet, nutzt KubeEdge zwei CRDs. Die erste CRD definiert ein sogenanntes DeviceModel, mit der zweiten CRD kann eine Instanz von diesem DeviceModel erstellt werden. Beide Ressourcen befinden sich beim KubeEdge-Projekt noch im Alpha Level. Das Alpha Level beschreibt die Stabilität einer API – weitere Abstufungen sind Beta Level und Stable Level. Beim Alpha Level können Änderungen sofort gemacht werden. Die Anwender:innen müssen dafür nicht benachrichtigt werden. Damit die API das Beta Level erreichen kann, muss sie bereits gut getestet worden sein und alle geforderten Features unterstützen. Bei dem Stable Level hingegen ändert sich die API über viele Versionen nicht mehr. Das DeviceModel soll eine Vorlage für ein Device geben und sich im Besonderen um die Zugriffsberechtigungen kümmern, während das Device eine Instanz von einem DeviceModel ist. Die CRDs für das Release 1.0 können in dem GitHub Projekt von KubeEdge gefunden werden [2].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
apiVersion: devices.kubeedge.io/v1alpha1 kind: DeviceModel metadata: name: cpu-sensor spec: properties: - name: Temperatur description: current cpu temperatur type: int: accessMode: ReadWrite defaultValue: “0” unit: Degree Celsius |
Im DeviceMode (siehe Block DeviceModel)l kann zu den einzelnen Eigenschaften eine genauere Spezifizierung erstellt werden. In dieser können wir z. B. festlegen, ob der Wert von anderen Systemen verändert werden darf. Eine Änderung des Wertes wird über Edge auf den Sensor synchronisiert. Dieser muss selbständig entscheiden, welche Aktionen er nun durchführen muss. Beispiele für eine Anwendung sind z. B. Starten einer Messung oder das Stoppen einer Maschine.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
apiVersion: devices.kubeedge.io/v1alpha1 kind: Device metadata: name: device-name labels: description: CPU-Sensor model: cpu-sensor spec: deviceModelRef: name: cpu-sensor nodeSelector: nodeSelectorTerms: - matchFields: - key: ''.metadata.name” operator: In values: - edge status: twins: - propertyName: Temperatur reported: metadata: timestamp: '1550049403598' type: int value: “21” desired: metadata: timestamp: '1550049403598' type: int value: “22” |
Die Device-Definition Device-Resource.yaml (siehe Block Device-Resource.yaml) legt einen Sensor an. Dieser Sensor speichert in einem String die aktuell gemessene Temperatur ab. In den Manifest-Feldern „kind“ und „apiVersion“ wird definiert, welches API-Objekt in welcher API-Version erstellt werden soll. Wie gewohnt werden die Metadaten, z. B. Name und Namespace des Objektes, und die Spezifikation des Objektes in den entsprechenden Feldern definiert. Unter dem Feld „nodeSelector“ kann spezifiziert werden auf welchen Edge Nodes das entsprechende Device synchronisiert werden soll. Für die Selektion der Edge Nodes stehen die bekannten Mechanismen von Kubernetes und dessen NodeSelector zur Verfügung, so kann ein Device z. B. auf Knoten in einer bestimmten Zone synchronisiert werden oder wenn sie ein bestimmtes Label haben. In der Device-Definition (siehe Block Device-Resource.yaml.) wird die „matchFields“-Variante des NodeSelectors verwendet und selektiert alle Knoten, die den Namen „edge“ haben.
Das Feld „deviceModelRef“ referenziert auf ein DeviceModel. In dem Statusblock werden die Device Twins und deren erfassten Werte abgespeichert. Die Beziehung hierbei ist immer eine 1 zu m Beziehung. Ein Device kann mehrere Sensoren haben, ein Sensor kann jedoch nur einem Device zugeordnet werden. Jeder Twin beinhaltet den propertyName, der sich aus dem DeviceModel ableitet, und den erfassten Werten inklusive des Zeitstempels wann dieser Werte erfasst wurde.
Die Felder „desired“ und „reported“ unterscheiden sich nur in der Interpretation der Software. Das Feld „reported“ definiert die tatsächlich gemessenen Werte eines Sensors, wohingegen der Feld „desired“ den Soll-Zustand des Sensors beschreibt. Der Edge Node synchronisiert die gemessenen Sensordaten in den CloudCore und liest hier den Soll-Zustand („desired“) aus. Bei einem Sensorwert-Update wird der Eigenschaft-Value des „reported“-Feldes, so wie der Zeitstempel, geupdated.
Das Aktualisieren eines Sensorwertes führt zu einem Update-Event in der Kubernetes API. Diese Events, die Erstellung, Löschung oder Änderung eines API-Objektes, kann ein System bei dem Kubernetes API Server abonnieren. Die Abonnierung solcher Events kann für spezielle Ressourcen durchgeführt werden. So kann ein System nur die Events der Ressourcenart „Device“ abonnieren. Diese Event-Architektur erlaubt es, bei Änderungen der Werte weitere Verarbeitungsschritte einzuleiten.
Edge Komponente
Die Verbindung zwischen Cloud und Edge Node endet auf dem Edge Node im EdgeHub. Der EdgeHub dient als Kommunikationsendpunkt und verteilt die Informationen an die Subkomponenten. Die Synchronisation der Devices und DeviceModels wird über die DeviceTwin-Komponente vorgenommen. Der DeviceTwin schreibt die Informationen in eine lokale SQLite3-Datenbank (auf der Abbildung als Data Store bezeichnet). Die persistenten Informationen werden zusätzlich an den EventBus gesendet, wo die Informationen über eine MQTT-Schnittstelle an den DeviceMapper oder direkt an das Device geleitet werden. Informationen über die Erstellung oder Entfernung von Devices werden nur im Data Store persistiert.
Die Synchronisation des Node-Status und der Pods wird über den MetaManager vorgenommen, der diese Informationen ebenfalls in den Data Store schreibt und die Information dem Edged zur Verfügung stellt. Der Edged ist eine angepasste Implementierung des Kubernetes Kubelet. Zu den Aufgaben des Kubelets/Edged gehören das Starten, Stoppen und Verwalten von Pods. Ergänzend werden Metriken der laufenden Pods und des Knoten selbst gesammelt und dem Kubernetes API Server zur Verfügung gestellt. Der MetaManager sammelt diese Metriken und sendet diese über den EdgeHub and den CloudCore.
Für die Synchronisierung der Sensordaten auf dem Edge-Node bietet KubeEdge eine MQTT-Schnittstelle an, die entweder direkt von einem Sensor oder über einen sogenannten Mapper angesprochen werden kann. Ein Mapper kommt dann zum Einsatz, wenn die Sensoren nicht das von KubeEdge geforderte Protokoll bzw. Format direkt unterstützen. Wenn ein Sensor Daten sendet bevor der DeviceTwin auf dem Edge Node synchronisiert ist, werden alle Daten verworfen und mit einer Fehlermeldung beantwortet.
Ausblick
Im nächsten Teil des Tutorials wird die Basisinfrastruktur für den Anwendungsfall aufgesetzt. Hierfür wird auf einem PC ein lokales Kubernetes Cluster mit dem CloudCore aufgesetzt. Zusätzlich wird auf einem Raspberry Pi die Edge Komponente von KubeEdge installiert. Zum Verproben des Setups werden erste Testdaten gesendet.
Verweise
[1] https://github.com/kubeedge/kubeedge
[2] https://github.com/kubeedge/kubeedge/tree/release-1.0/build/crds/devices
Die Inhalte dieser Arbeit stammen aus dem Projekt KOSMoS – Kollaborative Smart Contracting Plattform für digitale Wertschöpfungsnetze. Dieses Forschungs- und Entwicklungsprojekt wird mit Mitteln des Bundesministeriums für Bildung und Forschung (BMBF) im Programm „Innovationen für die Produktion, Dienstleistung und Arbeit von morgen“ (Förderkennzeichen 02P17D026) gefördert und vom Projektträger Karlsruhe (PTKA) betreut. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt bei den Autor:innen.


