
tl;dr
- Data Science, Machine Learning Engineering, Software Engineering, and IT-Operations know-how is required to turn a prototypical machine-learning model into an end-user ready service.
- Thus, a cross-functional team is essential for the successful development of a data product.
- In order to reduce complexity, start with a simple model, for example, a pre-trained model and a simple REST-Service, to demonstrate the principle functionality of the service and improve model complexity as well as infrastructure in agile iterations: change both as needed.
Machine learning and especially deep learning models have proven to be a powerful tool for a huge variety of tasks e.g.: question answering, text-summarization, object detection, optimal price prediction, and recommender systems. Thousands of blog articles demonstrate the simplicity of implementing such highly-sophisticated models from literature with millions of parameters using modern machine learning frameworks like Pytorch, Tensorflow, or Keras in simple notebooks. Unfortunately, transforming these models into a productive data product is a non-trivial tasks that goes far beyond such prototypical notebooks. Apart from the rigorous model evaluation, advanced data engineering, software engineering, and IT-operations know-how are required to address the hidden technical debts in machine learning systems [1]: ranging from building and maintaining a serving infrastructure, addressing scalability issues, introducing CI/CD pipelines, addressing model versioning, addressing prediction uncertainties, and model as well as system monitoring.
We had the unique opportunity to develop such an End-to-End machine learning system from a prototype model to a fully scalable data product with a team of five interdisciplinary students from the TUM Data Innovation Lab during a period of six months as part of an educational research experience. We chose to implement an image captioning system: a system for generating short describing captions for images and, thus, combining computer vision and natural language understanding.
Approaching the Data Product Development
In order to leverage the skills and interests of the students, as well as the research and software-driven characteristics of this project, we approached the project in agile iterations based on the Scrum-framework.
We initially started with a brainstorming session in order to generate ideas and to scope the project. Based on this session, we created an initial backlog with user stories and tasks. We addressed the items in the backlog in bi-weekly sprints with a focus on creating demonstrable increments after each iteration. From a high-level perspective, an agile workflow for a data science project does not differ much from a typical software engineering project: epics are defined, stories are written and estimated, a sprint is planned, and finally, a review and retrospective are conducted in order to present the increment of the last sprint and to identify potentially continuous process improvements (see Fig. 1). However, compared to other software projects, a data science project has to deal with more uncertainties as it highly depends on available training data and extracting the hidden information with previously unknown methods. In order to handle such uncertainties, we incrementally increased the complexity of our models and in parallel implemented the needed infrastructure and software components. In cases where we could not estimate the complexity due to uncertainty, we made use of timeboxed tasks.

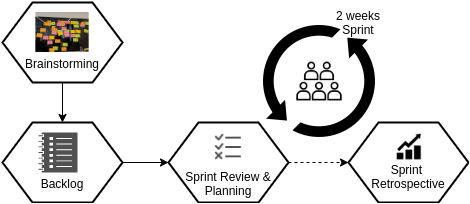
From Iteration 1 to Iteration n: Towards an End-to-End Image Captioning System
Following our agile approach and our End-to-End idea, we started experimenting with a pre-trained image captioning model. As a next step, we set up the first infrastructure components, implemented model versioning and deployment processes. Thus, a working prototype could already be demonstrated after a few iterations. As a next step, we improved the model quality and finalized our infrastructure and serving infrastructure.
From Pre-Trained Model to a ResNet-based Encoder-Decoder Network Architecture
There are hundreds of papers describing different deep learning architectures and approaches for image captioning. Given such a fast-moving research area, finding a starting point is nontrivial.
We started with a reimplementation of the im2txt model [2] for our image captioning system: the model consisted of a well-established encoder-decoder network architecture. For the image encoding, we used the pre-trained ResNet for transforming an image into a latent space. The decoder in our network consists of a recurrent neural network for generating the caption (see Fig. 2). Thus, only the decoder part had to be trained. We trained the model using a typical sequence generating approach, i.e. we trained the model for predicting the next (most likely) word. In order to generate new captions for an image, we applied an autoregressive approach feeding back the previously generated (sub) captions until a stop token is generated.
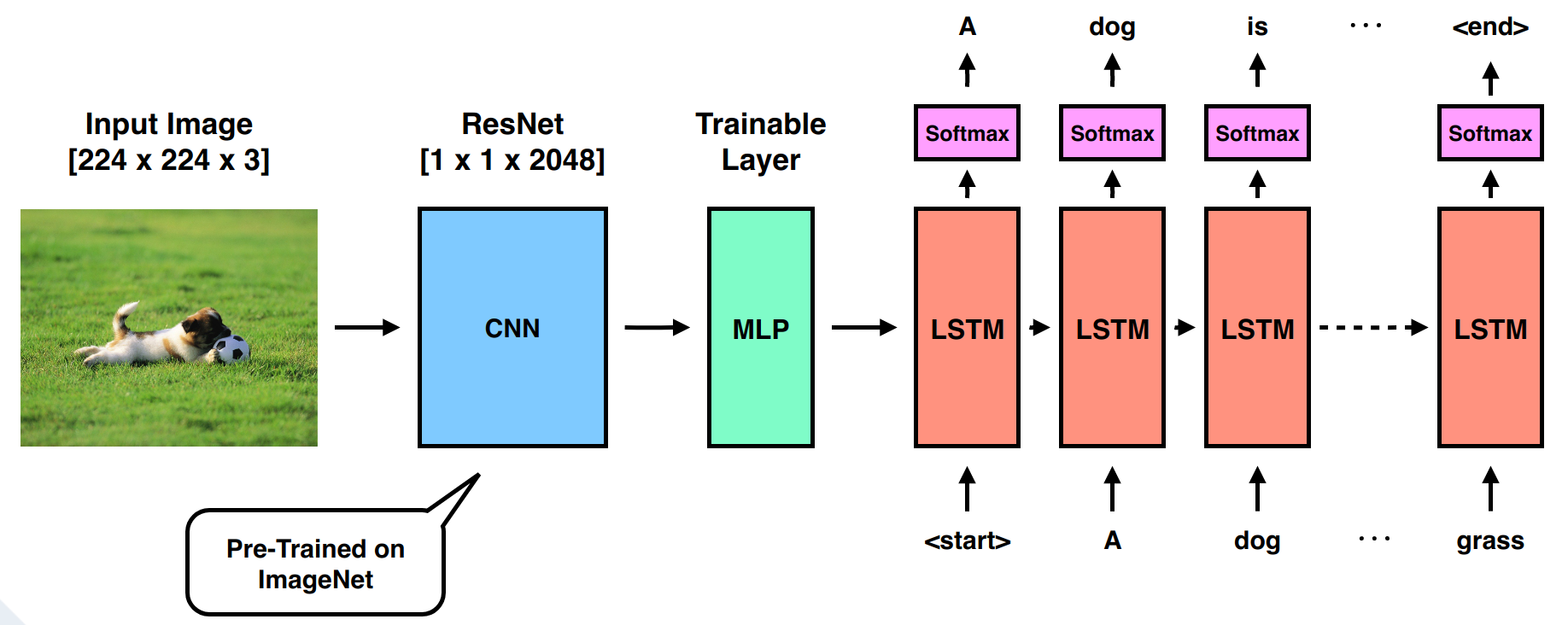
Setting up the infrastructure, drafting the architecture and implementing the required components:
From a high-level perspective, we wanted to realize (1) a scalable image captioning service that can be accessed via REST-API and web interface and (2) a system that allows to versionize and manage models. And, thus, finally serve as a general blueprint for an artificial intelligent infrastructure.
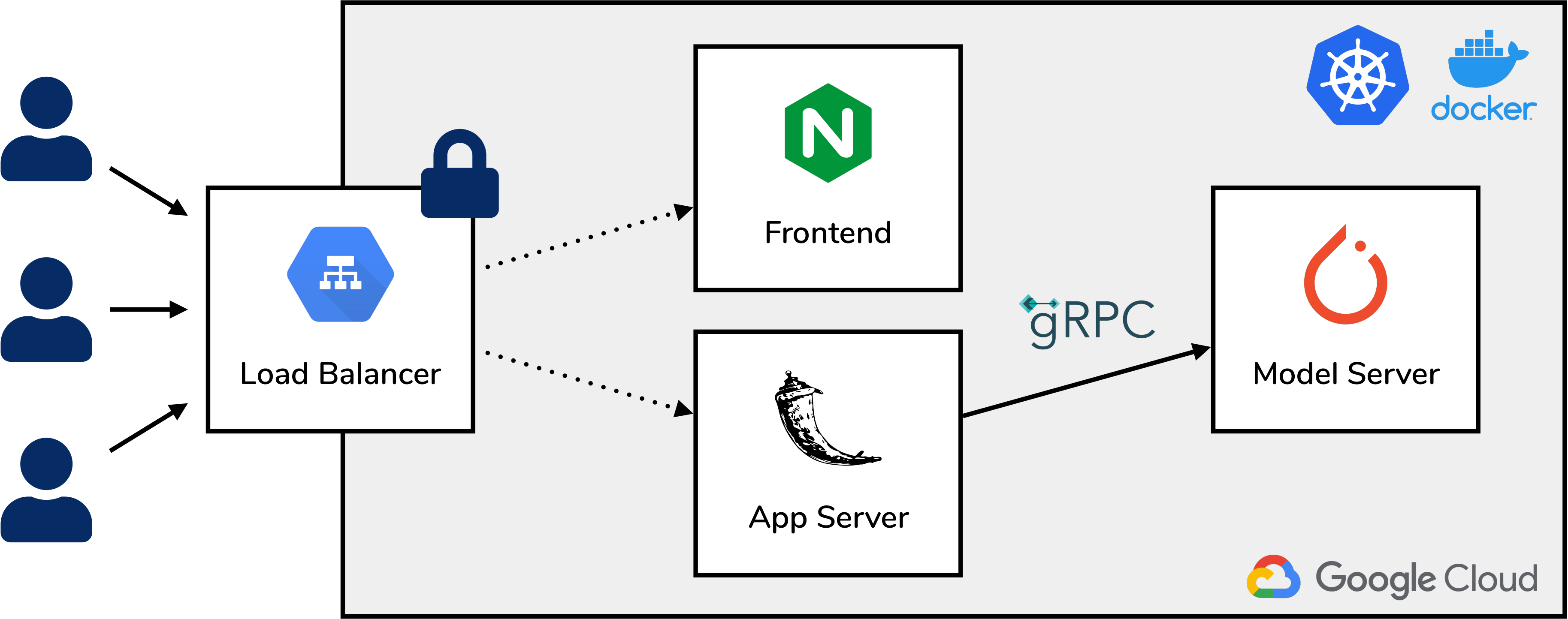
We chose to implement the components as loosely coupled microservices in the Google Cloud using a Kubernetes cluster making use of the built-in auto-scaling features, state-of-the-art deployment mechanisms, and a machine learning model repository. We implemented three services in total: a frontend, an application server, and a model server (see Fig. 3). The frontend is responsible for serving a Vue.js graphical user interface and was dockerized together with an Nginx web server. The application server is solely a gateway between our frontend and the model server allowing decoupling of components and providing authentication as well as logging functionalities. Finally, the model server is the core component of our architecture as it performs the inference of image captions from a given image making use of the latest model in a MLflow-based model repository. On top of that, we implemented training and evaluation workflows, also in our cloud infrastructure, for experimental deep learning research, in our case, for the development of an image captioning model. Results of the different experiments, conducted by all team members, are stored in MLflow for reproducibility and for the seamless deployment of new and improved models.
Of course, in order to achieve a production-ready state of our system, we implemented continuous integration (CI) and continuous deployment (CD) pipelines for the automatic building, testing and deployment of our components. We made use of Kubernetes Helm in order to realize an infrastructure-as-code approach, which allows reproducible and simple setup of even complex and complicated system architectures in the cloud.
From Vanilla Encoder-Decoder Network to a State-of-the-Art Model
Having a first encoder-decoder model and a system for serving our model allowed us to further improve the model quality. Based on the literature and the experiments using our cloud-based evaluation and testing workflows, we identified two main problems:
- As we use the encoder-decoder network in an autoregressive manner, i.e. generating in each iteration the next word and feeding the already generated captions back into our model until a stop token is generated, our model has no chance of correcting a previously generated word. In order to improve on this greedy approach, we implemented a beam-search approach which considers the top K likely words in each iteration and outputs the most likely caption overall considered paths.
- We were able to yield another significant improvement by introducing an attention mechanism to our network architecture: having an encoder-decoder network architecture relies on the fact that the encoder correctly summarizes the important features of the input image. Attention breaks down the input into smaller parts and allows the decoder to prune unnecessary parts.
Furthermore, we implemented a teacher-forcing approach for training our decoder, i.e. at every decoding step the input is the ground truth instead of the previous decoding output. This is especially important in the earlier training phase (when outputs are expected to be incorrect) and leads to faster convergence of the training process.
Towards the Production System
Finally, in our last iterations, we activated and tested the Kubernetes auto-scaling features, added Prometheus and Grafana for monitoring our system, and implemented an API that enabled the programmatical captioning of new images using an API-Key for service authentication.
We also improved our frontend by integrating a feature to rate generated captions in order to collect user-based feedback and, thus, to enable automatic re-training and further improvements of our models in the future. Finally, we added a feature to visualize (for each word of the predicted caption) the region of the image which yielded the prediction by making use of the network’s attention (see Fig. 5).

Testing the System
Evaluating an image captioning model is not straightforward as a good caption is highly subjective. A trivial measure, which just compares the generated output with the ground-truth captions is highly problematic, as it does not consider the dynamic and flexibility of language. Thus, BLEU, Meteor, Rouge, CIDEr are all typically used metrics with different aspects of the quality of a language model. All with different strengths and weaknesses. For the inclined reader, we provide an overview of the evaluation results in Table 1. Our latest model yielded state-of-the-art performance results, in some parts also slightly better than the reference models published in scientific literature, due to differences in the implementation e.g. higher beam width and taking into account multiple captions per image while training.

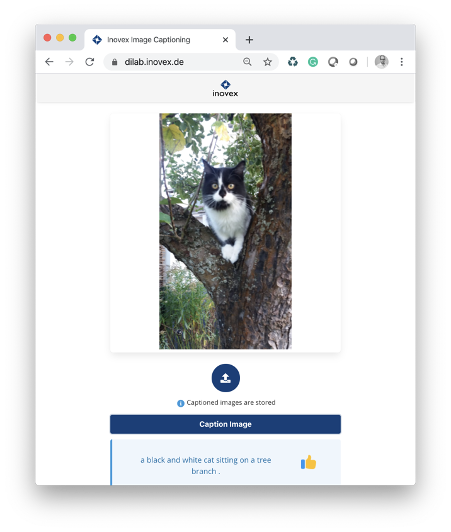
Conclusion
We implemented an image captioning system from whiteboard to a fully functional cloud-based service with model management, automatic deployment, and automatic scaling capabilities. Our model is based upon a state-of-the-art deep learning model for image captioning. We started with a simple deep learning architecture and improved the model continuously in agile iterations. At the same time, we extended our serving and AI infrastructure. We deployed and embedded our model into a microservice architecture that ensures high availability under the assumption of unreliable infrastructure.
Addressing the model, infrastructure, and software development in short iterations and continuously extending the components helped us to reduce uncertainties and to scope our project.
We identified a key ingredient for successfully developing such an End-to-End system: A team with broad interests and skills which frequently discussed methodical and technical issues and shared their knowledge.
Therefore we were able to continuously improve the system and to collaborate as a team.
References
[1] D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Hidden Technical Debt in Machine Learning Systems, Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), 2015
[2] Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan, Show and Tell: A Neural Image Caption Generator, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015
[3] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio, Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, International Conference on Machine Learning (ICML), 2015


