
Data is of major importance for data products, as it is either made available to consumers through interfaces or significantly influences the predictive quality of machine learning and AI models. The term data quality is generally used to describe the degree to which data corresponds to the real things or facts it represents.
As it is often difficult or impossible in practice to evaluate the quality of data based on this definition, it is usually estimated based on the deviation from pre-defined assumptions. The domain of a data product implies a variety of assumptions, e.g. about the range of values, the distribution, or the correlation of certain attributes:
- The name of a person is always present
- The age of a person is an integer and not a negative
- An email address matches a certain pattern
- The measured value of a sensor is always within a certain interval
- The size of an apartment should have a positive correlation with its price
- The goods dispatched are never greater than the last stock of goods
Why is it important to ensure data quality?
High-quality data is data that meets domain-specific assumptions to a high degree. In addition to the semantic correctness of the data (see examples above), assumptions can also refer to syntactic correctness (fields, data types, etc.), completeness or freshness. In contrast to that, we speak of erroneous data or data of poor quality if critical assumptions are not fulfilled. Even if most assumptions are met, the violation of a single critical one can lead to serious consequential damage.
The initial challenge in ensuring data quality is to extract all domain-specific assumptions about the datasets from the knowledge base of the domain experts, future users, and data consumers. Interviews or workshops are usually suitable for this purpose. In addition, it is important to establish a regular exchange and a feedback channel to update or adjust the assumptions if necessary.
To explicitly define assumptions about data, to systematically check them, and to react appropriately in the event of anomalies is essential for ensuring data quality:
- If the data itself is the product that is provided via interfaces (e.g. financial market data), incorrect data has a direct negative impact on customer satisfaction and can lead to negative reviews, loss of trust, and cancellations.
- If an ML model is applied to incorrect data, it produces incorrect forecasts (garbage in, garbage out). In the worst case, incorrect conclusions are drawn or even wrong decisions are made based on incorrect predictions. Incorrect predictions can also have a negative impact on the user experience, leading to a loss of trust, frustration, and abandonment of the product.
- Personal data must be accurate and, if required, kept up to date following the principle of accuracy set out in the GDPR. With the right to correction, the GDPR also guarantees data subjects the right to demand the immediate correction of incorrect data.
How can data quality be ensured?
Nowadays, there are a large number of tools that can be used to validate assumptions about data. The basic usage is similar for all these tools. They generally differ in the range of assumptions they support and the ability to integrate various backends like databases, compute engines, etc.
First, all assumptions about datasets are recorded, e.g. in the form of YAML or JSON files. These files contain, for example, information about expected value ranges, the presence of certain values, etc.. It is advisable to store these files in a version control system and update them regularly.
The integration of validation into the respective data product is usually complicated. Depending on the use case, there may be different forms of integration. In the following, a general distinction is made between delta and result validation, although a combination of both approaches may also be necessary. It is assumed that an increment is to be integrated into a target dataset, e.g. by using an INSERT or MERGE operation. This does not necessarily have to be the case with result validation which can also be applied to the result of a DELETE or UPDATE operation.
Validation of the current batch before the transaction (delta validation)
In some scenarios, it is sufficient to validate the current batch before the transaction without having to validate the result of the transaction, e.g. when appending to a target dataset. It is assumed that the integration of a valid batch into a valid target dataset always produces a valid result dataset. This is the case, for example, if only the schema (i.e. column names and data types), the presence of certain attributes, or the number of elements is checked.
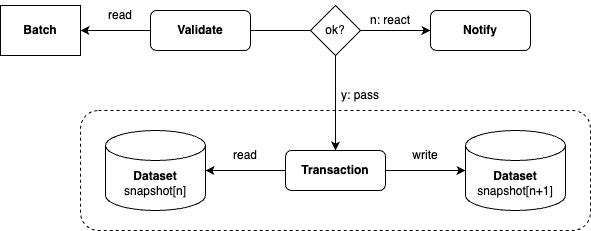
Validation of the resulting dataset after the transaction (Result Validation)
In some scenarios, it is not sufficient to validate the batch to be integrated before the transaction. In such cases, the integration of a valid batch into a valid target dataset can lead to an invalid result dataset. An example of this would be the integration of bank transfers into a transaction history, in which it must be ensured that the account balance can never fall below the granted credit. In scenarios in which DELETE or UPDATE operations are executed, it can also be useful to perform a result validation, e.g. in the case of GDPR deletion requests. One possible strategy for implementing a result validation is to perform the change of a target dataset analogous to a merge in the main of a git repository. In the Apache Iceberg Cookbook, this procedure is also described as the Write-Audit-Publish (WAP) pattern.
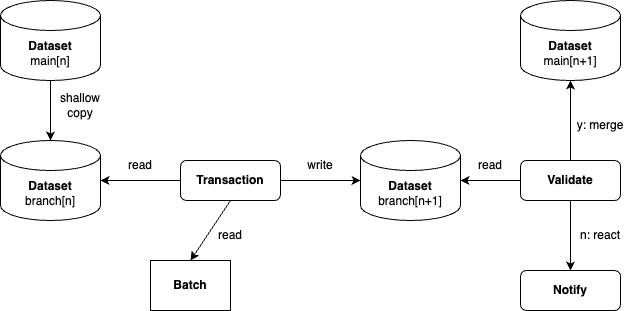
The original state of the target dataset (main[n]) corresponds to the latest commit of the main, to use the analogy of a version control system. A zero-data copy creates a clone of the original target dataset (branch[n]), on which the operation is then executed. This creates a temporary, resulting dataset (branch[n+1]). As the operation was carried out on the clone, the original target dataset (main[n]) remains unchanged. The validations are now carried out on the temporary, resulting dataset (branch[n+1]). If the validation is successful, the original target dataset (main[n]) is overwritten with the temporary, resulting dataset (branch[n+1]). This exposes the resulting dataset (main[n+1]) for further processing by downstream data consumers.
How to handle incorrect data?
The decision depends very much on the use case and the possible consequences. For example, incorrect data can have serious consequences in one case, while in another case it is only perceived as a harmless anomaly. In addition, not every assumption is equally critical: it may make sense to deal with the absence of an important attribute differently than with the exceeding of a certain tolerance value.
Scenarios in which incorrect data can cause major damage
- Example 1: Marketing data is made available to advertisers for a fee via APIs. Incorrect data can have a significant negative impact and a direct effect on advertisers‘ sales.
- Example 2: A recommender system generates product recommendations based on a user’s interactions on a streaming platform. Incorrect data can lead to unsuitable recommendations that negatively impact the user experience.
- Example 3: Sales forecasts are calculated based on internal company reporting. Management allocates resources for the upcoming financial year based on these forecasts. Incorrect data can lead to suboptimal decisions.
In examples 1, 2, and 3, once erroneous data has been identified, it is appropriate to initially block it from further processing and to apply a fallback strategy. In the first example, temporarily not providing data and possibly compensating customers could be significantly less harmful than providing incorrect data. In the second example, an alternative recommender model could be used temporarily that is not based on the interaction history and only recommends general popular products, for example. In the third example, it is also less harmful to make a delay in the provision of correct data transparent through appropriate communication than to issue incorrect data unnoticed.
On the other hand, there are scenarios in which erroneous data can be handled more reactively. This particularly includes use cases where no major damage is to be expected as a consequence of incorrect data.
Scenarios in which incorrect data would not cause major damage
- Example 4: Temperature sensors are installed at various points in a cooling system. These sensors are technically only capable of measuring temperature values within a certain range. In some cases, unrealistic measured values may be temporarily transmitted due to external sources of error.
- Example 5: Social media data is processed for sentiment analysis on an internal dashboard. The data is obtained via publicly accessible APIs, the schema of which can change unannounced over time. The data is regularly provided incompletely or late.
- Example 6: Tracking events are processed and made available for internal data products. Each data product has different data quality requirements.
In examples 4, 5, and 6, it might be adequate to continue processing the data even if validation fails and simply send a notification. Particularly when providing data for internal consumers, as in example 6, it would also be possible to attach the validation results to the data as meta information. Not every assumption is equally important for every consumer. By additionally providing the validation results, each consumer can decide for himself how to deal with the data.
Which tools can be used to ensure data quality?
In the open source landscape, alongside the most popular Python library Great Expectations, other libraries for validating assumptions on data have also become established. A promising alternative product from the Python ecosystem is Soda, which offers a more intuitive usage concept and extensive support for various backends. For integration into Java or Scala applications, AWSLabs has developed deequ, which is based on Apache Spark and also exists in a Python version, pydeequ.
In the case of Great Expectations and Soda, there are also SaaS offerings on a subscription model in addition to the commercially usable open-source versions. In the proprietary space, Databricks offers Delta Live Tables, for example, which allows you to define assumptions via constraints and checks and react accordingly via an ON VIOLATE clause. Customers of Snowflake can make use of their integrated Data Quality Monitoring framework based on so called Data Metric functions (DMFs).
Of course, you can also use generic frameworks such as Spark and dbt to implement data quality checks. Although this requires a significantly larger implementation effort, it can be customized to your individual needs.



