
In this blog post, we introduce a framework for data pipeline testing using dbt (data build tool) and Mimesis, a fake data generator for Python.
Data quality is of utmost importance for the success of data products. Ensuring the robustness and accuracy of data pipelines is key to achieving this quality. At this point, data pipeline testing becomes essential. However, effectively testing data pipelines incorporates several challenges, including the availability of test data, automation, a proper definition of test cases, and the possibility of running end-to-end data tests seamlessly during local development.
This blog post introduces a framework for testing data pipelines built with dbt (data build tool) using Mimesis, a Python library for fake data generation. Specifically, we will
- use Pydantic to parse and validate dbt’s
schema.ymlfiles - implement a generic approach to auto-generate realistic test data based on dbt schemas
- use the generated data to test a dbt data pipeline.
Combining dbt’s built-in testing capabilities with Mimesis’s data generation abilities allows us to validate data pipelines effectively, ensuring data quality and accuracy.
All files discussed in this article are available in an accompanying GitHub repository. If you want to follow along, make sure to clone the repository.
Prerequisites
We assume the reader to be familiar with the following topics:
- Python Basics, incl. basic object-oriented programming
- dbt Basics, incl. model definitions, seeds, basic project structures, and data tests
- Pydantic Basics, incl. model definitions and parsing YAML files into Pydantic models
If you want to follow along, you must have Python 3.10 installed on your machine. Alternatively, our GitHub repository contains a Development Container Specification that allows you to set up a working environment quickly (requires Docker to be installed on your machine).
Motivation
As discussed in detail in this blog post, data quality is paramount for successful data products. High-quality data is data that meets domain-specific assumptions to a high degree. This includes:
- Semantic correctness: e.g., an email address matches a particular pattern, or the measured value of a sensor is always within a specific interval.
- Syntactic correctness: e.g., fields and data types are correct, and constraints are met.
- Completeness.
Meeting the requirements above heavily depends on the correctness and robustness of data pipelines, which makes testing them so important. Testing data pipelines ensures accurate transformations and consistent schemas. It helps to catch errors early and to prevent downstream impacts. However, effectively running data tests comes with some challenges:
- Realistic Test Data: Using production data can raise privacy concerns, while manually creating (realistic) test datasets is time-consuming and often incomplete.
- Dynamic Environments: Adapting to changing schemas or new sources can introduce errors.
- Automation in Testing: Data pipelines are often time-consuming and costly. Developer teams need the means to run data tests many times throughout the development lifecycle automatically and ensure the detection of problems early on.
- Local Test Execution: Not only should data pipeline tests be automated, but they should also be accessible to developers to run them on their local machines during development. This requires developers to easily generate test data and be able to execute data pipeline tests end-to-end.
Tools like dbt simplify data pipeline testing by providing a framework for modular, testable SQL-based workflows. But to truly test a pipeline effectively, we also need realistic datasets to simulate real-world scenarios – this is where libraries like Mimesis, a powerful fake data generator, come into play. The framework we introduce in this blog post aims at tackling the challenges above. Our approach allows developers to quickly auto-generate test data based on a schema definition and run data pipeline tests both locally and as part of CI/CD.
Mimesis – Fake Data Generation
Mimesis is a Python library that generates realistic data for testing purposes. It supports a wide range of data types, making it ideal for testing data pipelines without relying on production datasets. It also offers built-in providers for generating data related to various areas, including food, people, transportation, and addresses across multiple locales.
Let’s look at how easy it is to generate fake data with Mimesis.
|
1 2 3 4 5 6 7 8 9 |
from mimesis import Person from mimesis.locales import Local # Create an instance of the person provider for English data person = Person(locale=local.EN) # Generate a Name and an e-mail address print(person.full_name()) # e.g., "John Doe" print(person.email()) # e.g., "john.doe@example.com" |
Furthermore, we can use the Fieldset class to generate multiple values simultaneously for more significant amounts of data.
|
1 2 3 4 5 6 |
from mimesis import Fieldset from mimesis.locales import Locale # Create an instance of Fieldset and generate ten usernames fieldset = Fieldset(locale=Locale.EN) usernames = fieldset("username", i=10) # generates a list of 10 usernames |
Now that we have a basic understanding of how Mimesis operates, we’re all set to generate fake data and use it to test our dbt pipelines.
Combine dbt and Mimesis for Robust Data Pipeline Testing
Combining dbt’s transformation and testing capabilities with Mimesis’s ability to generate realistic test data allows us to create a strong framework for building reliable, scalable data pipelines. In the following sections, we’ll make our way up to testing our dbt pipelines with auto-generated fake data step-by-step.
First, we’ll set up our environment and install the necessary dependencies. Next, we’ll look into parsing dbt schemas using Pydantic. Finally, we’ll explore using the Pydantic models to automatically generate fake data for an arbitrary dbt seed or model.
Setting Up Your Environment
Firstly, clone the GitHub repository and navigate to the root directory:
|
1 2 |
git clone https://github.com/inovex/blog-dbt-mimesis.git cd blog-dbt-mimesis |
There are two options to set up your environment:
Option 1: Use the Development Container (recommended)
The repository includes a Development Container Specification for quick setup. All necessary dependencies are already installed if you run the code inside the Development Container.
Option 2: Manual Setup
Install the required dependencies using Poetry. This assumes you have Python 3.10 installed on your machine.
|
1 2 3 4 5 |
# install poetry pip install poetry poetry install # install dbt dependencies poetry run dbt deps --project-dir dbt_mimesis_example |
This project uses DuckDB. To create a DuckDB database, you must install DuckDB CLI on your machine. You can follow this guide to install it on your OS. Next, run the following command to create a database file inside the dbt_mimesis_example directory:
|
1 |
duckdb dbt_mimesis_example/dev.duckdb "SELECT 'Database created successfully';" |
Testing dbt Pipelines Using Mimesis
Having a working environment, we are ready to look at the code we will use to generate realistic data to test our dbt pipelines.
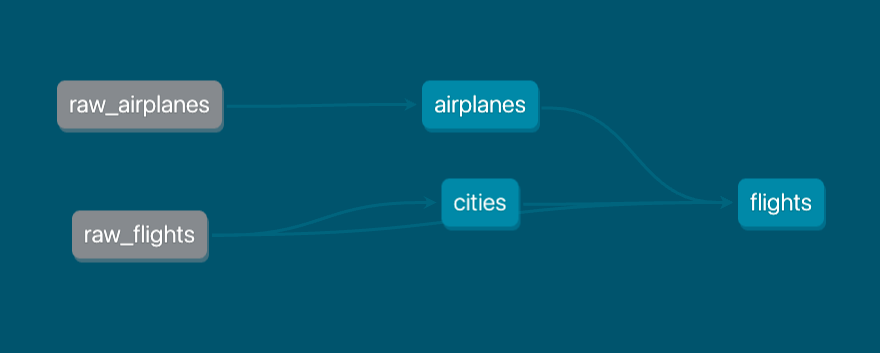
The lineage graph of the dbt_mimesis_example dbt project shows that there are two seeds – namely raw_airplanes and raw_flights – and three downstream models depending on those seeds: airplanes, cities, and flights. In dbt, seeds are CSV files typically located in the seeds directory and can be loaded to a data warehouse using the dbt seed command. Hence, to properly test our dbt pipeline, we need to ensure that we have two CSV files: raw_airplanes.csv and raw_flights.csv. To this end, we will use Pydantic to parse the schema.yml file inside the seeds directory. Subsequently, we’ll use the parsed schema definition to auto-generate fake data.
Step 1: Parsing dbt Schemas With Pydantic
Pydantic is a Python library that validates data using type annotations. It allows you to define models as Python classes, validate data against those models, and parse various input formats (e.g., JSON, YAML) into structured Python objects. This makes it an ideal tool for working with dbt’s schema.yml files, as it ensures that the schema definitions are valid and compatible with downstream processes like our test data generation.
Inside the data_generator/models.py, we define a few Pydantic models to parse our dbt
schema.yml files into structured Python objects:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from enum import Enum from pydantic import AliasChoices, BaseModel, Field class DataType(Enum): DATE = "date" VARCHAR = "varchar" INTEGER = "integer" class DBTColumn(BaseModel): """Basic DBT column""" name: str data_type: DataType data_tests: list[str] = [] meta: dict[str, str | bool] = {} class DBTTable(BaseModel): """DBT Table""" name: str columns: list[DBTColumn] class DBTSchema(BaseModel): """DBT Schema""" models: list[DBTTable] = Field(validation_alias=AliasChoices("models", "seeds")) |
The DBTSchema model represents a list of DBTTable objects. Subsequently, a DBTTable consists of a name and a list of columns represented by the DBTColumn model. Finally, a DBTColumn has a name, a data type, an optional list of data tests, and an optional meta-dictionary containing metadata about the column.
We can now use these models to parse our YAML-based dbt schema definition into structured Python objects:
|
1 2 3 4 5 |
from pydantic_yaml import parse_yaml_file_as from data_generator.models import DBTSchema schema = parse_yaml_file_as(model_type=DBTSchema, file="dbt_mimesis_example/seeds/schema.yml") print(schema) # prints a DBTSchema object representing the parsed schema |
Step 2: Auto-Generating Test Data with Mimesis
The next step is to use the structured Python objects representing the dbt schema to generate fake data. To this end, we create a TestDataGenerator class inside data_generator/generator.py that implements functionality to generate the data. Below, we’ll break it down step by step.
Initialize the class
Let’s define a constructor for our class. We need some key attributes like our schema and the locale, as well as a mapping of the data types in our schema to the corresponding Mimesis data types. Furthermore, we want to leverage the powerful providers Mimesis offers, so we add a key attribute
field_aliases, which allows us to map column names to the providers. The class has two more attributes that are initiated with None and an empty dictionary, respectively. We can use the iterations attribute later to decide how many rows should be generated for a given table. Similarly, the reproducible_id_store will help store primary keys for cross-referencing.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import random import pandas as pd from mimesis import Fieldset, Locale from mimesis.keys import maybe # mapping of dbt data types to mimesis providers DATA_TYPE_MAPPING = { "VARCHAR": {"name": "text.word"}, "DATE": {"name": "datetime.date"}, "INTEGER": {"name": "integer_number", "start": 0, "end": 1000}, } class TestDataGenerator: def __init__( self, schema: DBTSchema, locale: Locale = Locale.EN, data_type_mapping: dict = DATA_TYPE_MAPPING, field_aliases: dict = {} ) -> None: self.schema = schema self.reproducible_id_store: dict[str, list] = {} self.fieldset = Fieldset(locale) self.field_aliases = { key: {"name": value} for key, value in field_aliases.items() } self.data_type_mapping = data_type_mapping self.iterations = None |
Generate Random Row Counts
It’s not very realistic if each generated table has the same number of rows. Therefore, we’ll add a method
_generate_random_iterations that assigns a random number of rows to each table within a specified range (i.e., between
min_rows and
max_rows). We store the resulting dictionary in the iterations class attribute mentioned earlier.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def _generate_random_iterations(self, min_rows: int, max_rows: int) -> dict: """Generate a random number of iterations for each table within the specified limits Parameters ---------- min_rows : int Minimum number of rows to be generated for a table max_rows : int Maximum number of rows to be generated for a table Returns ------- dict Returns a dictionary with the table names as keys and their corresponding row numbers as values """ return { table.name: random.randint(min_rows, max_rows) for table in self.schema.models } |
Generate Unique Values
In some cases, our schema contains a uniqueness constraint in the form of a data test
unique, or a column is defined as a primary key column. In these cases, we need a way to generate unique values. The _generate_unique_values method expects a
DBTTable object and a
DBTColumn for which the values should be generated as inputs and returns a set of values generated using Mimesis.
Certain Mimesis providers may not generate enough unique values. For instance, the Airplane provider can only produce ~300 unique airplane models. This becomes problematic if the number of iterations specified for the given table is larger than the maximum number of unique values available. Therefore, we must handle this edge case and adapt the maximum number of rows generated for the particular table to the maximum number of unique values available.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
def _generate_unique_values( self, table: DBTTable, column: DBTColumn, iterations: int = None ) -> list: """Generate a specified number of unique values using Mimesis Parameters ---------- field_name : str _description_ iterations : int _description_ Returns ------- list _description_ """ iterations = ( iterations if iterations is not None else self.iterations[table.name] ) unique_values = set() consecutive_no_increase = 0 while len(unique_values) < iterations: previous_len = len(unique_values) new_values = self.fieldset( **self.field_aliases.get( column.name, self.data_type_mapping[column.data_type.value.upper()] ), i=iterations * 2, ) unique_values.update(new_values) # check whether any new values have been added since previous iteration if len(unique_values) == previous_len: consecutive_no_increase += 1 else: consecutive_no_increase = 0 if consecutive_no_increase == 3: # not enough values available, restarting with lower number of iterations for given table print( f"Not enough unique values for {column.name}. Creating maximum number available." ) self.iterations[table.name] = len(unique_values) self.generate_data() break return list(unique_values)[:iterations] |
Generate Data for a Table
Next, we need a method that creates synthetic data for a single table by iterating over its columns. The _generate_test_data_for_table method takes a DBTTable object as input and returns a Pandas data frame with the generated fake data for the corresponding table.
In the context of relational databases, there are usually relationships between tables. Whenever a table references a primary key from another table, it is referred to as a foreign key. Thereby, a value in a foreign key column must either be null or present as a primary key in the referenced table. This logical dependency is referred to as referential integrity. Mimesis does not natively support referential integrity when generating data. Therefore, we apply some logic to consider primary and foreign keys during data generation. To this end, we use the
meta field, an optional part of dbt’s schema definitions. Specifically, we added metadata describing whether a column is a primary or foreign key to the dbt_mimesis_example/seeds/schema.yml file.
Within the _generate_test_data_for_table method, we also check whether a column is a primary key, a foreign key, or a regular column and handle it accordingly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def _generate_test_data_for_table(self, table: DBTTable) -> pd.DataFrame: """Generate test data for a given table Parameters ---------- table : DBTTable pydantic model describing a dbt table iterations : int, optional Number of rows to be generated, by default 10 Returns ------- pd.DataFrame Returns a pandas DataFrame with the generated data based on the table's schema """ schema_data = {} for column in table.columns: # check if column has primary/foreign key constraints primary_key = column.meta.get("primary_key", None) foreign_key = column.meta.get("foreign_key", None) # generate data according to column type if foreign_key: schema_data[column.name] = self._handle_foreign_key( foreign_key, column, table ) continue elif primary_key: schema_data[column.name] = self._handle_primary_key(table, column) continue schema_data[column.name] = self._handle_regular_column(table, column) df = pd.DataFrame.from_dict(schema_data) return df |
Handle Foreign and Primary Keys
In case the column is defined as a primary or foreign key column, the _handle_key_column method is called.
First, it checks whether a set of values for the (referenced) primary key is already available in the reproducible_id_store class attribute (as you might remember, this is an initially empty dictionary). If not, it generates a unique set of values for the primary key and adds it to the dictionary. Finally, it returns either a random sample of the set of values available from the referenced primary key column or the set of values itself – depending on whether it’s a foreign or a primary key.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
def _handle_key_column( self, table: DBTTable, column: DBTColumn, foreign_key: str = None ) -> None: """Method to generate data for primary/foreign key columns Parameters ---------- table : DBTTable DBTTable object column : DBTColumn DBTColumn object foreign_key : str, optional foreign key, e.g., 'referenced_table.pk', by default None """ reproducible_id = foreign_key if foreign_key else f"{table.name}.{column.name}" iterations = self.iterations[foreign_key.split(".")[0]] if foreign_key else None if reproducible_id not in self.reproducible_id_store.keys(): # store generated data in reproducible_id_store self.reproducible_id_store[reproducible_id] = self._generate_unique_values( table, column, iterations ) if foreign_key is not None: return random.choices( self.reproducible_id_store[foreign_key], k=self.iterations[table.name] ) return self.reproducible_id_store[reproducible_id] |
Handle Regular Columns
Alternatively, the column is handled as a regular, non-key column. In that case, it returns a set of unique values if the unique data test is set for the column. Otherwise, it returns a list of generated values without ensuring uniqueness. It might also include null values – depending on whether or not the not_null data test is part of the column specification.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def _handle_regular_column(self, table: DBTTable, column: DBTColumn) -> list: """Method to generate data for regular columns, i.e., not primary/foreign key colums, and takes into account constraints wrt. nullability and uniqueness Parameters ---------- table : DBTTable DBTTable object column : DBTColumn DBTColumn object Returns ------- list Returns a list of generated values """ if "unique" in column.data_tests: return self._generate_unique_values(table=table, column=column) else: probability_of_nones = 0 if "not_null" in column.data_tests else 0.1 return self.fieldset( **self.field_aliases.get( column.name, self.data_type_mapping[column.data_type.value.upper()], ), i=self.iterations[table.name], key=maybe(None, probability=probability_of_nones), ) |
Generate Data for the Entire Schema
Finally, we want to implement logic to generate data for an entire schema. The generate_data method orchestrates the whole process by calling the helper methods we implemented to create data for all tables in a schema.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def generate_data( self, min_rows: int = 10, max_rows: int = 100 ) -> dict[str, pd.DataFrame]: """Generate test data for a given schema Parameters ---------- min_rows : int Minimum number of rows to be generated for a table max_rows : int Maximum number of rows to be generated for a table Returns ------- dict[str, pd.DataFrame] Returns a dictionary with table names as keys and pandas DataFrames containing generated data as values """ if self.iterations is None: self.iterations = self._generate_random_iterations(min_rows, max_rows) generated_data = {} for table in self.schema.models: df = self._generate_test_data_for_table(table=table) generated_data[table.name] = df return generated_data |
Full Picture
We’re all set to use the TestDataGenerator to generate some actual data based on the
schema.yml file. Let’s add some field aliases to use Mimesis’s
city and
airplane providers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from pydantic_yaml import parse_yaml_file_as from data_generator.models import DBTSchema FIELD_ALIASES = { "OriginCityName": "city", "DestCityName": "city", "AirplaneModel": "airplane", } # parse the schema schema = parse_yaml_file_as(model_type=DBTSchema, file="dbt_mimesis_example/seeds/schema.yml") # instantiate a TestDataGenerator generator = TestDataGenerator(schema=schema, field_aliases=FIELD_ALIASES) # Generate test data with row limits test_data = generator.generate_data(min_rows=50, max_rows=200) # Store the generated data inside our dbt Seeds directory for table_name, df in test_data.items(): print(f"Generated data for {table_name}") df.to_csv(f"/PATH/TO/YOUR/PROJECT/DIR/dbt_mimesis_example/seeds/{table_name}.csv") |
The repository also contains a data_generator/main.py file with a simple CLI implemented using click. It allows you to generate test data for an arbitrary dbt schema using the following command:
|
1 |
poetry run python data_generator/main.py --dbt-model-path dbt_mimesis_example/seeds/schema.yml --output-path dbt_mimesis_example/seeds --min-rows 100 --max-rows 1000 |
In this case, we are generating a random number of rows within the range 100-1000 for each of the seeds in our dbt_mimesis_example/seeds/schema.yml. You can adjust the number of rows by setting the --min-rows and --max-rows flags. Note: When using larger numbers of rows (e.g., > 1.000.000 min rows), generating the data might take some time.
Using Mimesis to Test dbt Pipelines
We successfully generated test data using the described method based on our dbt seeds schema. Now that we have some CSV files in our dbt seeds directory let’s run the dbt seed command to load the data into our DuckDB database and run our dbt pipeline and tests:
|
1 2 3 4 5 6 7 8 9 10 11 |
# navigate to the dbt project directory cd dbt_mimesis_example # load seeds into database poetry run dbt seed # run dbt pipelines poetry run dbt run # perform dbt test poetry run dbt test |
If everything went as expected, all tests should have passed, and you should now have five tables in your DuckDB database. Let’s inspect some values:
|
1 2 3 4 5 6 7 8 |
# Enter the duckdb database duckdb dev.duckdb # list tables .tables # inspect some values from the flights database SELECT * FROM flights LIMIT 5; |
In our case, the output of the SQL command looks like this. Yours should look similar but with different values, as Mimesis generates them randomly:
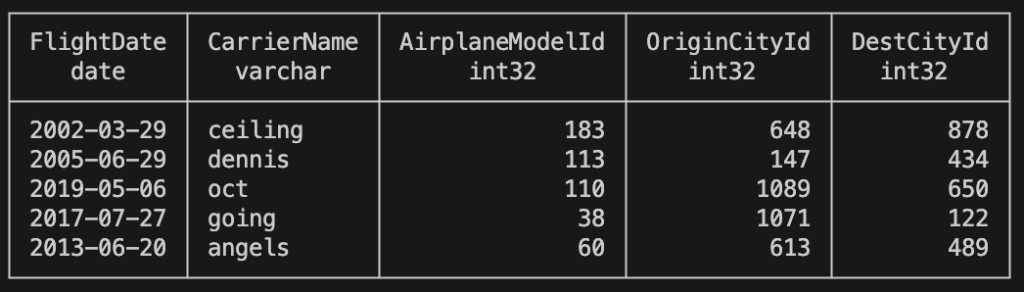
flights tableConclusion
This blog post explored how to use Mimesis to test data pipelines. We implemented a data generator that automatically creates fake data based on Pydantic models derived from parsed dbt schemas.
If you haven not done so already, check out our GitHub repository. It includes a GitHub Actions pipeline that automates dbt data testing using the approach we discussed. Have you tried applying this method to your dbt pipelines? We would love to hear your feedback! Happy testing! 🥳
If you want to dive deeper into the topics covered in this blog post, we recommend checking out the following resources:


