
Willkommen zum zweiten Teil der Blogserie „Intelligentes Service-Ticket-System für die Wartung“! In diesem Teil stellen wir verschiedene Komponenten vor, die auf Methoden des maschinellen Lernens basieren und das Intelligenten Service-Ticket-Systems (ISTS) auf eine gewisse Art und Weise „intelligent“ machen. So werden Anlagenführer:innen wie auch Service-Techniker:innen bei der Bearbeitung von Instandhaltungsaufträgen unterstützt.
Falls Du den vorangegangenen Artikel verpasst hast, findest du hier die Einführung in den Use Case und das Lösungskonzept des ISTS.
Infrastruktur für Machine Learning Services
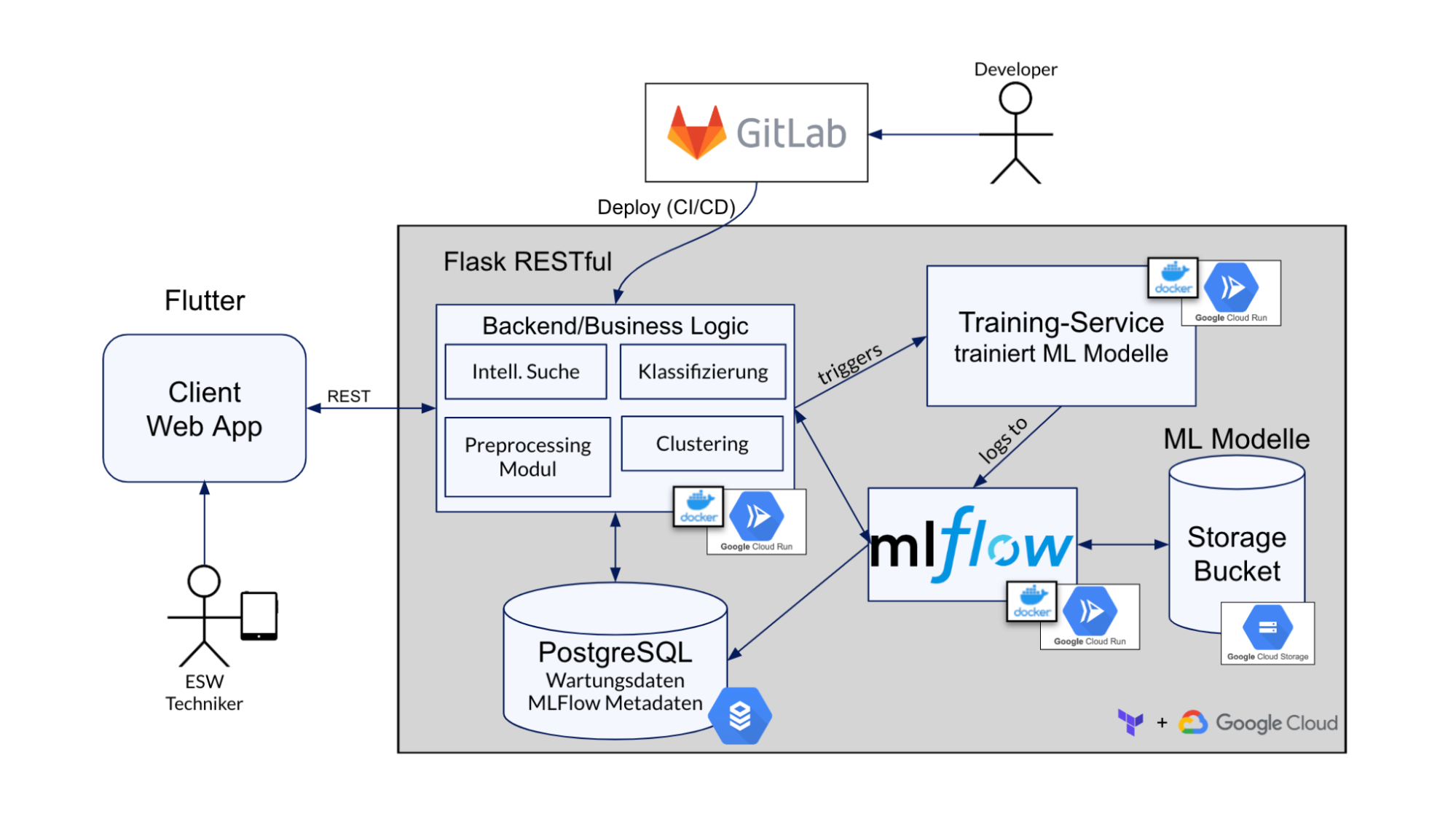
Das ISTS setzt sich aus mehreren ML-Services zusammen, die miteinander interagieren und kommunizieren. Diese Services sind als Cloud-Run-Instanzen bereitgestellt. Alle Code-Versionen werden in Gitlab verwaltet und die aktuellste Version wird über eine CI/CD Pipeline in Google Cloud Run gepusht wo diese als Docker Container laufen. In Google Cloud Run laufen die Container bisher nicht durchgehend, sondern werden nach einer bestimmten Zeit, in der sie inaktiv sind, wieder herunter gefahren. Dadurch muss man nur für die tatsächliche Laufzeit bezahlen und spart Ressourcen. Dies ist allerdings nur während der Entwicklungszeit eine Option. Wenn das Projekt live geht und genutzt werden soll, würde diese Funktion deaktiviert werden, um zeitintensive Kaltstarts zu vermeiden.
Die persistente Datenspeicherung wird ebenfalls durch GCP verwaltet. Einerseits gibt es die Cloud SQL Services, wo sich PostgreSQL-Datenbanken für die Services befinden. Andererseits haben wir Cloud Storage Buckets, hier sind Rohdaten und ML-Modelle gespeichert.
Statt GCP per Hand zu konfigurieren, verwenden wir Terraform. Terraform ist ein Infrastructure-as-Code (IaC) Tool, mit dem man Konfigurationen in ein Skript schreiben kann. Terraform setzt dann unsere im Text beschriebene Configs um. Somit sind die Configs versionierbar, automatisierbar sowie selbst dokumentierend.
Die Infrastruktur für die Machine Learning Services ist in drei Bereiche aufgeteilt:
Zunächst werden die Modelle trainiert. Hierzu haben wir einen Trainingsservice entwickelt, der regelmäßig von unserem Backend via einer REST-Schnittstelle getriggert wird. Im Trainingsservice wird das Klassifikationsmodell anhand der aktuellen Daten aus der Datenbank trainiert. Das (auf Wikipedia-Daten vortrainierte) Smart-Search-Modell wird aus einem Google Cloud Storage Bucket geladen und dann ebenfalls auf den aktuellen Daten nachtrainiert.
Zum Verwalten und Versionieren der Modelle verwenden wir MLFlow. Hier werden die Hyperparameter der Modelle geloggt, die Metriken der Modelle wie Accuracy und Precision werden gespeichert. Die Artefakte der Modelle werden in einem Google Cloud Storage Bucket gespeichert und die Verweise dazu ebenfalls von MLFlow verwaltet und gespeichert.
Die Daten von MLFlow sind in einer Postgres-Datenbank persistiert. Diese Datenbank ist in Google Cloud SQL gehostet.
Die besten trainierten Modelle werden dann zur Ausführung von unserem ISTS Backend geladen und dort bei Bedarf ausgeführt und aufgerufen.
Welche ähnlichen Fehler traten in der Vergangenheit bereits auf?
Eine der Hauptaufgaben des intelligenten Ticketsystems ist die „Intelligente Suche“. Maschinenführer:innen, die ihr Problem in die Web App eingeben, sollen vorangegangene ähnliche Probleme vorgeschlagen werden. Wenn zum Beispiel eine LED-Lampe der Maschine nicht funktioniert, soll das ISTS in der Lage sein, ihnen ähnliche Probleme wie „Beleuchtung funktioniert nicht“ oder „Licht ist kaputt“ vorzuschlagen. Dies erleichtert die Erstellung und Bearbeitung von Tickets auf folgende Weise:
- Maschinenführer:innen müssen keine Zeit mit dem Eintippen einer langen Problembeschreibung verschwenden. Stattdessen können sie ein paar Schlüsselwörter eingeben, auf deren Grundlage eine Liste mit Vorschlägen zur Auswahl bereitgestellt wird.
- Techniker:innen haben eine Liste mit einheitlichen Problemen, die leichter zu verstehen und zu bearbeiten sind. Darüber hinaus werden ihnnen auf der Grundlage ähnlicher Problembeschreibungen potenzielle Problemlösungen angeboten, was die Bearbeitungszeit eines Tickets weiter verkürzt.
Um ähnliche Probleme zu identifizieren, wurde das NLP-Modell Word2Vec implementiert. Word2Vec ist ein zweischichtiges neuronales Netz, das darauf trainiert ist, sprachliche Kontexte von Wörtern zu erkennen. Das Modell analysiert einen großen Textkorpus, um herauszufinden, welche Wörter häufig zusammen im gleichen Kontext verwendet werden. Die analysierten Wörter werden dann in einen mehrdimensionalen Vektorraum eingeordnet, der auf dem Kontext basiert, in dem sie erscheinen. Die Position eines Wortes im Vektorraum wird als Worteinbettung bezeichnet, die einen mehrdimensionalen Vektor darstellt.
Word2Vec hat zwei Ansätze: einen CBOW- und einen Skip-Gram-Ansatz. Beim CBOW-Ansatz wird ein Zielwort auf der Grundlage seines Kontextes vorhergesagt. Im Gegensatz dazu wird beim Skip-Gram-Ansatz der Kontext des Wortes auf der Grundlage des Zielwortes vorhergesagt.
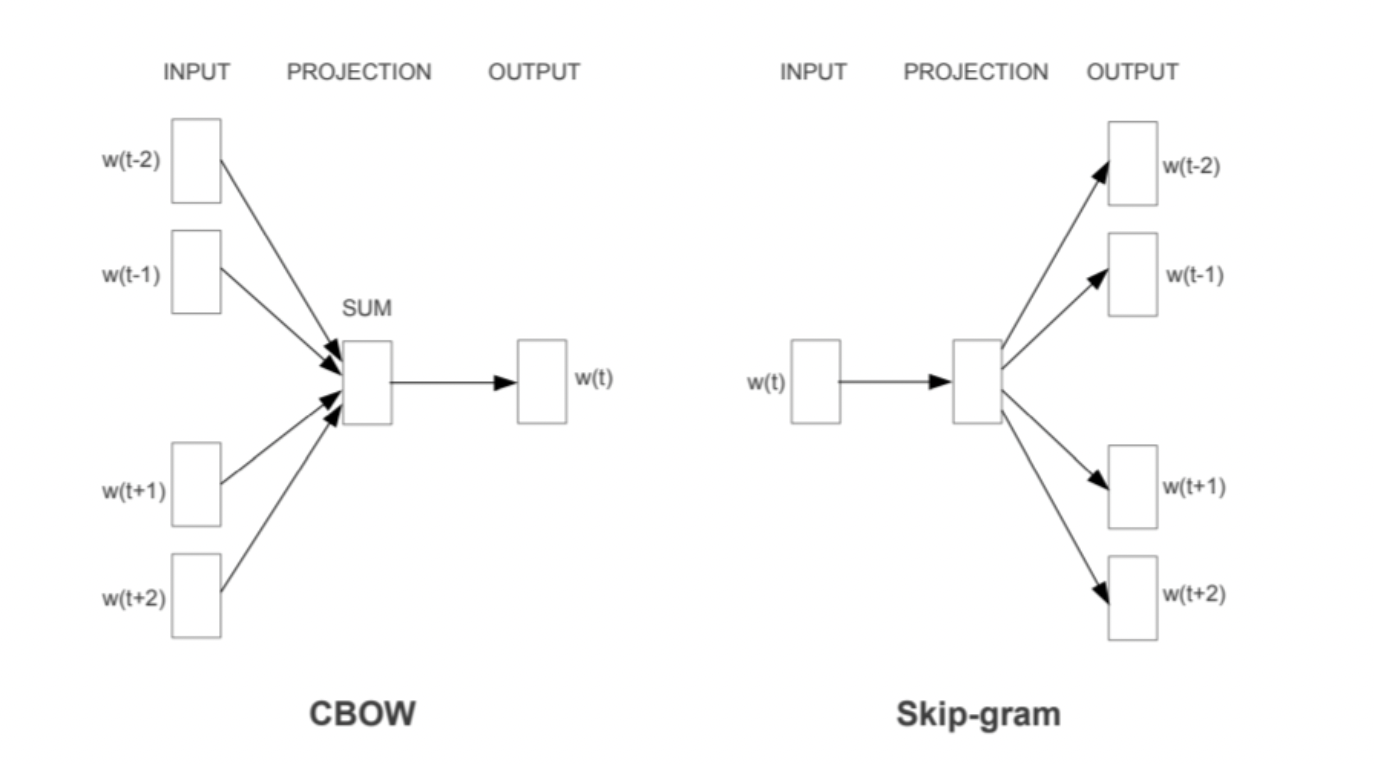
Quelle: Exploiting Similarities among Languages for Machine Translation
Die folgende Abbildung zeigt die grundlegende Struktur des W2V-Modells. Zunächst wird für jedes Wort eine Worteinbettung nach dem Zufallsprinzip initialisiert (könnte auch wie im Beispiel als ein One-Hot-codierter Vektor dargestellt werden). Dann wird die Eingabe an eine versteckte Schicht weitergegeben, die eine voll verbundene Schicht ist, deren Gewichte die Worteinbettungen sind. Die Ausgabe der vollständig verknüpften Schicht wird durch einen Softmax-Klassifikator geleitet, um die Wahrscheinlichkeiten der Zielwörter aus dem Vokabular zu ermitteln.
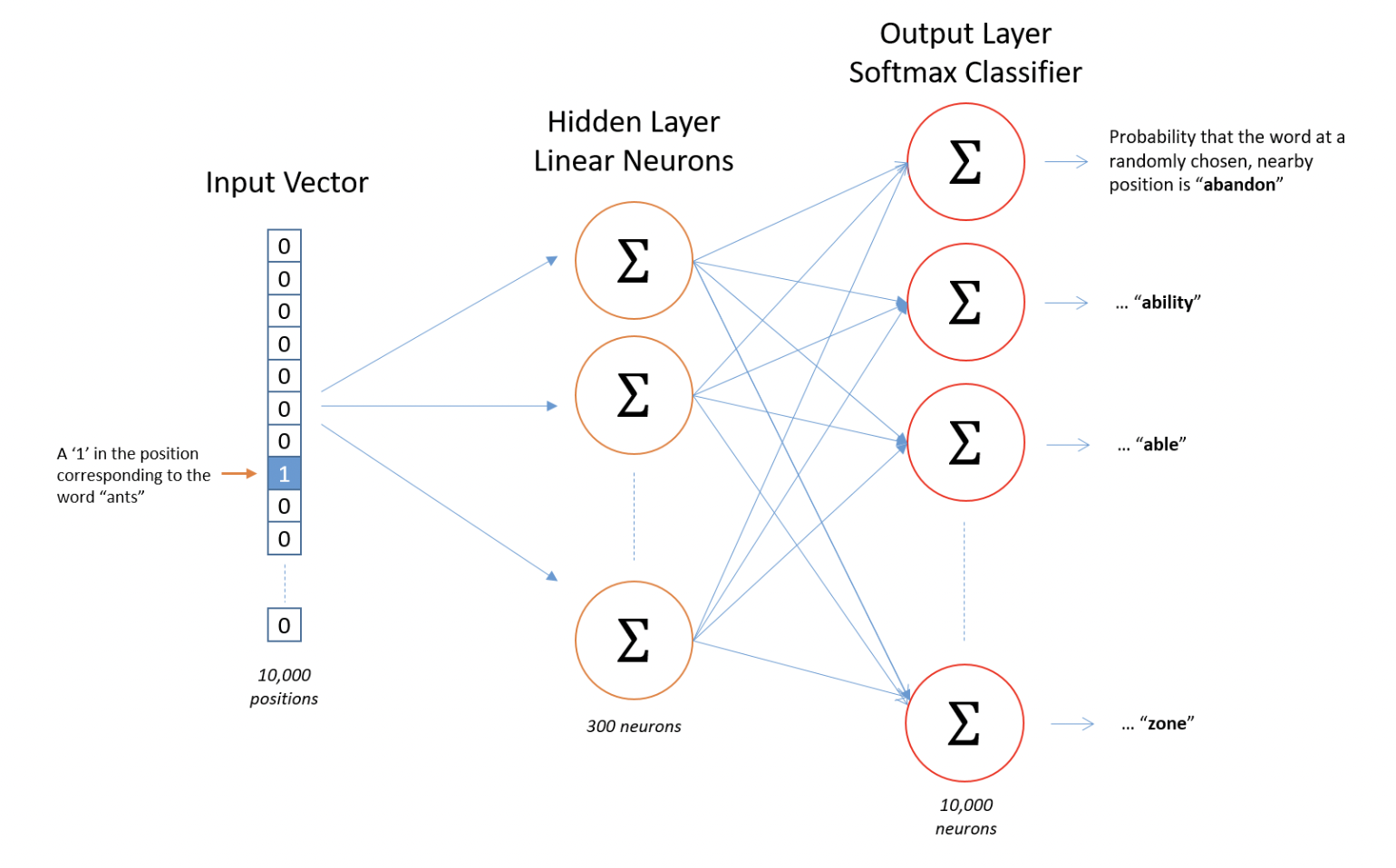
Source: The Architecture of Word2Vec.
Für unseren Anwendungsfall haben wir ein CBOW-Word2Vec-Modell implementiert, da es für kleinere Datensätze besser geeignet ist. Das Modell sagt jedes Wort im Satz auf der Grundlage des Kontexts voraus, in dem es erscheint. Nehmen wir ein Beispiel: „LED Lampe an der Maschine ist kaputt“. Bei jedem Durchlauf des Modells wird ein Wort aus dem Satz ausgeblendet (z. B. das Wort „Lampe“), und das Modell versucht, dieses Wort anhand des Kontexts (z. B. „LED __ an der Maschine ist kaputt“) vorherzusagen. Wir kombinieren die Worteinbettungen der einzelnen Wörter aus dem Kontext, um eine Kontexteinbettung zu bilden. Die Kontexteinbettung wird an die versteckte Schicht weitergegeben, um vorherzusagen, welches Wort fehlt. Idealerweise sollen die Wahrscheinlichkeiten des echten Zielworts, d. h. „Lampe“, nahe bei 1 liegen, während die Wahrscheinlichkeiten der anderen Wörter nahe bei 0 liegen sollen. Nach jeder Trainingsiteration werden die Worteinbettungen auf der Grundlage der analysierten Sätze angepasst.
Zunächst wurde das implementierte Word2Vec-Modell auf der Grundlage des deutschen Wikipedia-Korpus mit rund 50.000 Artikeln trainiert. Anschließend wurde das Modell auf Basis der kundenspezifischen Daten des ESW nachtrainiert.
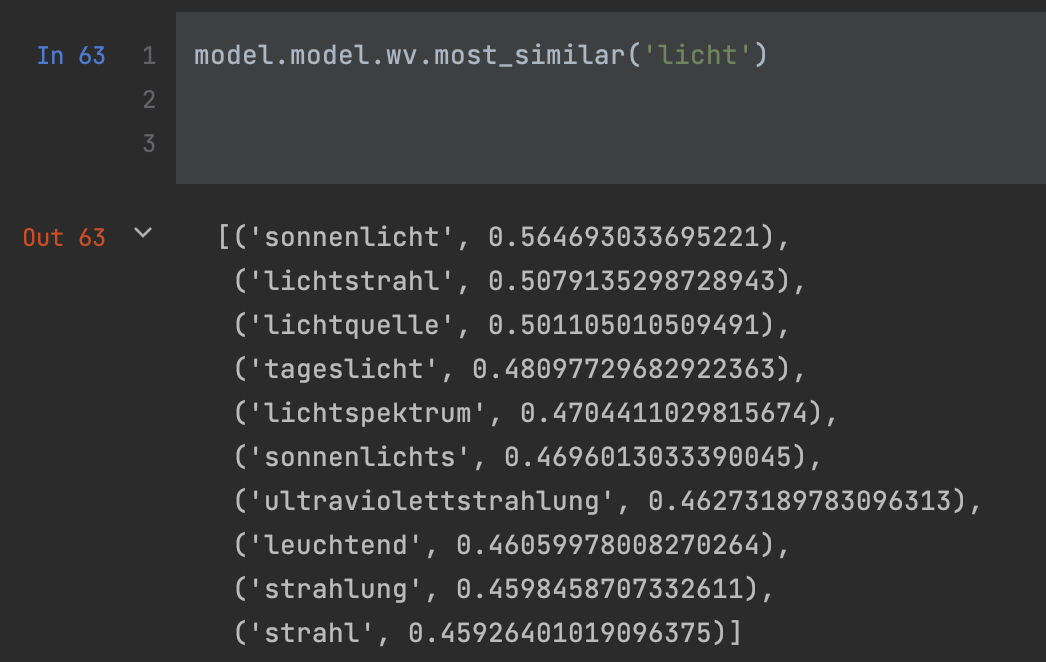
Nach dem Training konnte unser Modell erfolgreich ähnliche Wörter identifizieren, wie aus den Beispielen ersichtlich:
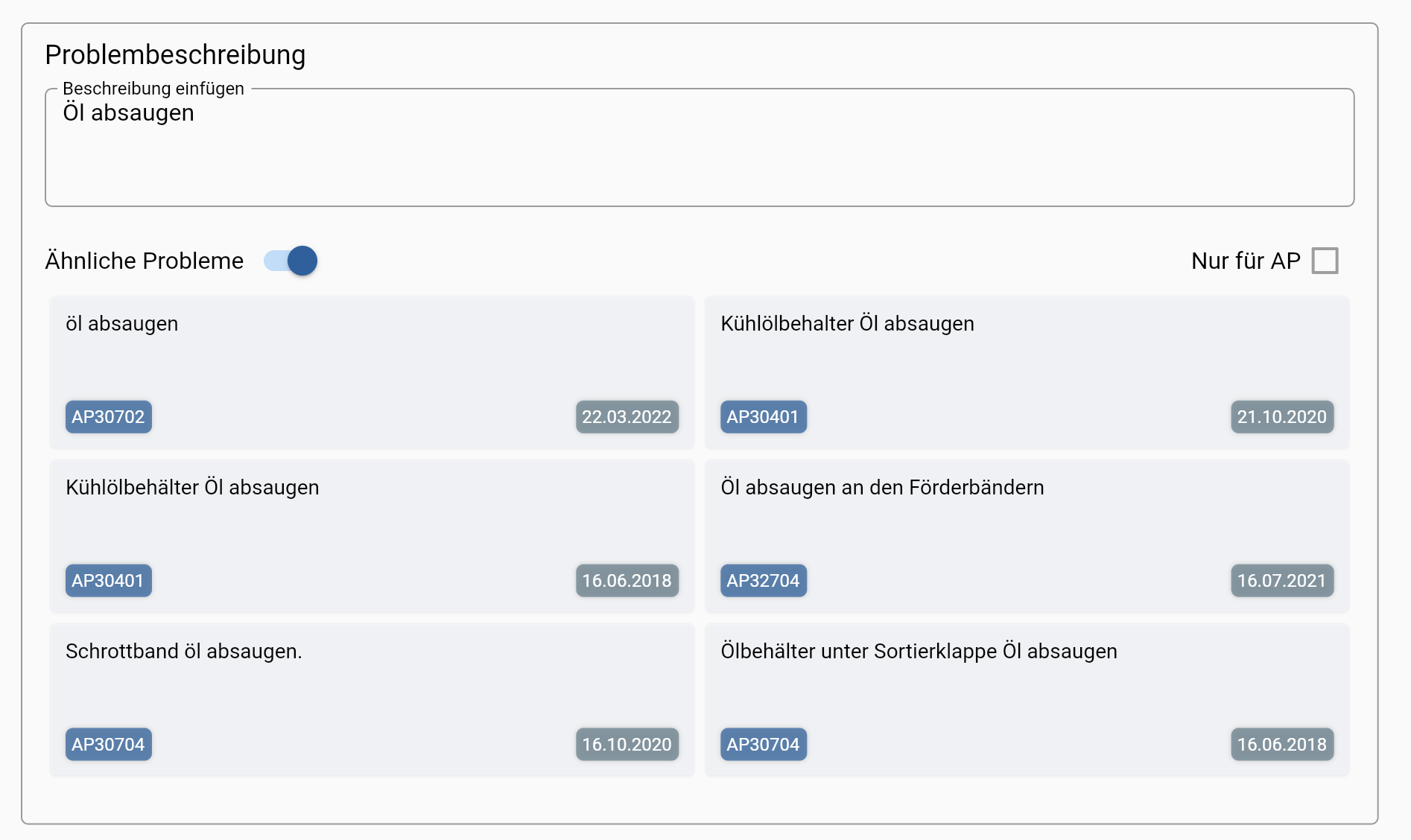
Es ist wichtig zu erwähnen, dass unser Modell auch in der Lage ist, Wörter zu erkennen, die eine ähnliche semantische Bedeutung haben, aber völlig anders geschrieben werden, wie z. B. „Licht“ und „Strahlung“.
Clustering häufiger, ähnlicher Beschreibungen
Eine weitere Anforderung an das ISTS ist eine Filtermöglichkeit nach häufigen Problemen und Lösungen. Um die Häufigkeit angeben zu können, wollen wir semantisch ähnliche Probleme/Lösungen zusammenfassen. Die Schwierigkeit besteht darin, die Ähnlichkeit von Texten zu berechnen. Da zum Beispiel „Verriegelung an der Tür hinten defekt“ und „Verriegelung reagiert nicht“ für einen Mensch als ähnliche Probleme erkennbar sind. Für den Computer, der nur die einzelnen Wörter betrachtet, sind sie unterschiedlich. Um sie zusammenzufassen, werden Cluster mit ähnlichen Problemen oder Lösungen benötigt.
TF-IDF
Vor dem Clustering wird der Text in einen Vektor umgewandelt mit Hilfe des TF-IDF Vectorizer. TF-IDF (Term Frequency – Inverse Document Frequency) definiert die Wichtigkeit eines Wortes in einem Dokument. Gegeben ist ein Korpus mit mehreren Dokumenten. Der Wert gibt an, wie oft jedes Wort in dem gegebenen Dokument vorhanden ist und wie oft in den anderen Dokumenten. Das bedeutet, dass ein Wort, das oft in einem Dokument vorkommt, relevant für das Dokument ist. Das bedeutet im Umkehrschluss, dass das Dokument sich sehr wahrscheinlich auf das Wort bezieht. Tritt ein Wort aber häufig in mehreren Dokumenten auf, ist es entweder relevant für alle oder für keines der Dokumente. Das macht es schwer, ein Dokument durch dieses Wort zu finden.
Der TF-IDF wird für jedes Wort im Korpus berechnet. Mit jedem Auftreten des Wortes im Dokument wird der TF-IDF Wert erhöht und mit jedem Auftreten in den anderen Dokumenten verringert sich der Wert.
Folgende Variablen sind wichtig:
- N: ist die Anzahl der Dokumente, die in einem Datensatz sind
- d: ist das gegebene Dokument aus dem Datensatz
- D: ist die Sammlung aller Dokumente
- w: ist das gegebene Wort aus einem Dokument
TF-IDF besteht aus zwei Teilen: die Term-Frequency und die Inverse-Document-Frequency.
Die Term-Frequency wird durch die Frequency f(w,d) berechnet und gibt die Häufigkeit von Wort w im Dokument d an.
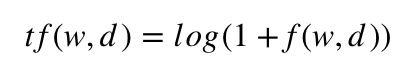
Quelle: Formel der Term-Frequency
Die Inverse-Document-Frequency idf(w,D) wird durch die Frequency f(w,D) berechnet und gibt die Häufigkeit von Wort w in der Sammlung aller Dokument D an.
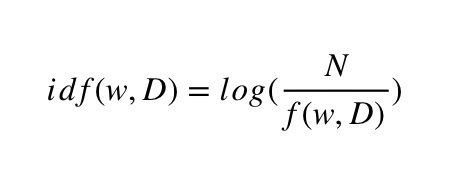
Quelle: Formel der Inverse-Document-Frequency
Um den TF-IDF Score zu berechnen, werden die zwei Häufigkeiten multipliziert.
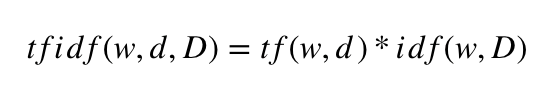
Quelle: Formel des TF-IDF Score
Darauf wenden wir ein dichte-basiertes Clustering an, da man keine Anzahl der Cluster vorgeben muss, wie zum Beispiel KMeans. Wir haben uns für OPTICS entschieden, da es weniger Parameter gibt und diese zudem noch leicht anzupassen sind. Um OPTICS zu verstehen, muss man als erstes DBSCAN betrachten, da sie aufeinander aufbauen.
DBSCAN
DBSCAN ist ebenfalls ein dichte-basiertes Clustering. Die Idee ist es, dass jedes Objekt in einem bestimmten Radius (Eps-Nachbarschaft) eine Mindestanzahl von Objekt (MinPts) enthält, um einem Cluster zugewiesen zu werden.
Die Eps-Nachbarschaft NEps(p) von einem Punkt p ist somit definiert als NEps(p) = {q E D | dist(p,q) <= Eps}. Daraus ergeben sich 2 Arten von Punkten in einem Cluster: Kernpunkte und Randpunkte. Kernpunkte befinden sich in einem Cluster und Randpunkte am Rand eines Clusters. Ein Kernpunkt q ist als dieser definiert wenn |NEps(q)| >= MinPts gilt.
Um die Bildung von Clustern zu verstehen, brauchen wir noch 3 weitere Begriffe, die sich auf die Beziehung zwischen den Punkten beziehen.
Ein Cluster wird definiert durch 3 wichtige Begriffe:
- Directly density-reachable
Ein Punkt p ist direkt density-reachable von einem Punkt q, wenn p in der Eps-Nachbarschaft von q ist, unter der Bedingung, dass q ein Kernpunkt ist. - Density-reachable
Ein Punkt p ist density-reachable, wenn die Punkte einer Kette von Punkten „directly density-reachable“ vom Vorgänger sind. - Density-connected
Die Punkte p und q sind density-connected, wenn beide von einem Punkt o „density-reachable“ sind.
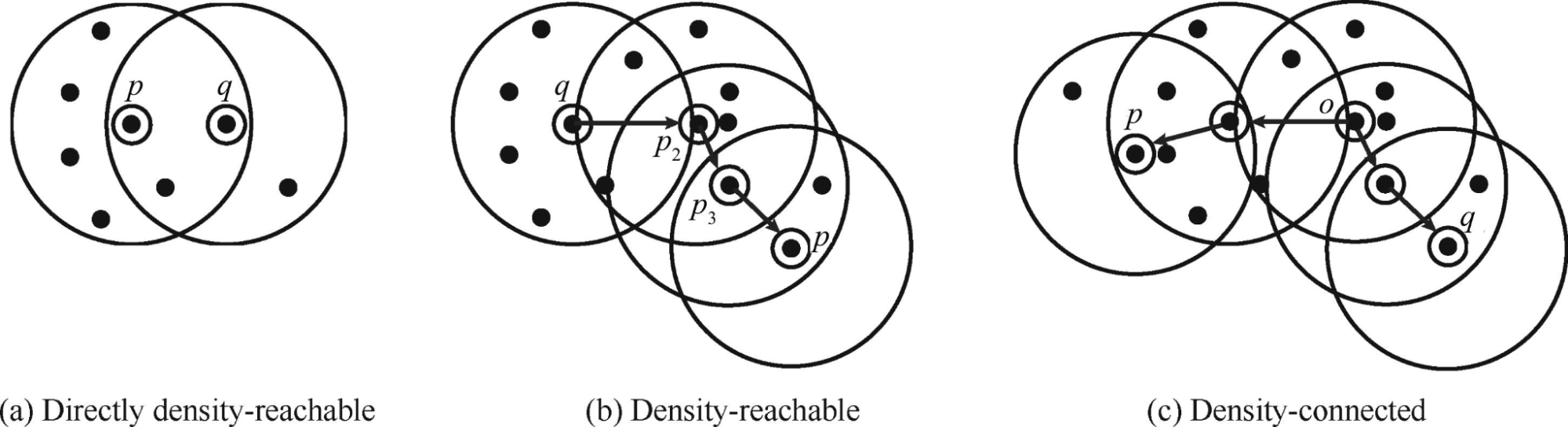
Quelle: PERAFÁN-LÓPEZ, Juan Carlos; SIERRA-PÉREZ, Julián. An unsupervised pattern recognition methodology based on factor analysis and a genetic-DBSCAN algorithm to infer operational conditions from strain measurements in structural applications. Chinese Journal of Aeronautics, 2021, 34. Jg., Nr. 2, S. 165-181.
Wann gehört ein Punkt zu einem Cluster?
Ein Punkt q gehört zum Cluster C, wenn er von Punkt p, der zum Cluster C gehört, „density-reachable“ ist und wenn q und p „density-connected“ sind. Somit ist ein dichte-basiertes Cluster eine Menge von density-connected Objekten, die maximal ist unter Berücksichtigung der Dichteerreichbarkeit. Als Rauschen werden Punkte definiert, die zu keinem Cluster gehören.
OPTICS
OPTICS (Ordering Points to Identify Cluster Structure) basiert auf DBSCAN. Der Unterschied ist, dass OPTICS jedes Objekt nach ihrer Erreichbarkeitsdistanz in einer Vorrangwarteschlange einordnet. Der OPTICS-Algorithmus generiert die erweiterte Cluster-Ordnung, bestehend aus der Reihenfolge der Punkte und der Erreichbarkeitsentfernung. Diese bestimmt die Clusterzugehörigkeit.
Das Festlegen von Epsilon auf einen niedrigeren Wert führt zu kürzeren Laufzeiten und kann als maximaler Nachbarschaftsradius von jedem Punkt betrachtet werden, um andere potenziell erreichbare Punkte zu finden.
Anwendung des Modells
Ähnliche Probleme sind durch OPTICS in Cluster eingeteilt. Wir können die Häufigkeit bestimmen, indem wir die Probleme innerhalb eines Clusters pro AP (Arbeitsplatz) zählen und durch die Gesamtanzahl von Problemen am AP teilen. Die n häufigsten Probleme sollen vorgeschlagen werden, sobald man im Frontend einen AP ausgewählt hat.
Welche:r Service-Techniker:in ist der/die Richtige?
Um zu verhindern, dass Maschinenführer:innen eine falsche Problemkategorie in das Ticket-System eintragen, wodurch dann falsche Techniker:innen gerufen werden, haben wir ein Klassifizierungsmodell auf den Daten der vergangenen Aufträge trainiert.
Training
Das Modell besteht intern aus fünf verschiedenen Teilmodellen. Für jede der Fehlerkategorien Elektronik, Mechanik, Sensorik, Hydraulik und Pneumatik wird ein eigener Algorithmus trainiert.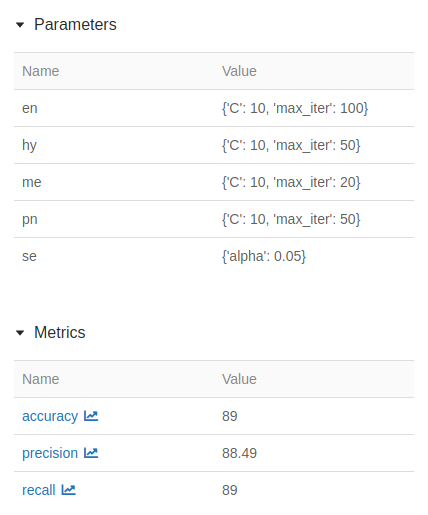
Die Problembeschreibungen der vergangenen Tickets, die als Feature für das Modell dienen sollen, werden für das Training zunächst mit einem TF-IDF-Vectorizer umgewandelt, damit die Algorithmen das Feature verarbeiten können.
Nach dieser Transformation wird nun für jedes der fünf Teilmodelle, aus denen das gesamte Modell am Ende besteht, der bestmögliche Algorithmus gesucht.
Die Algorithmen, die getestet werden, sind ein Naive Bayes Classifier und eine logistische Regression. Für beide Algorithmen wird jeweils noch ein Grid-Search auf einige vordefinierte Hyperparameter durchgeführt, um diese zu optimieren.
Nachdem hierdurch für jede Kategorie das Modell mit der höchsten Präzision gefunden wurde, werden die besten Modelle mit den besten Hyperparametern jeweils auf den Trainingsdaten trainiert. Daraufhin werden die Modelle auf Testdaten noch einmal validiert und eine durchschnittliche Präzision auf allen fünf Modellen berechnet.
Die Hyperparameter der Teil-Modelle werden dann in MLFlow gespeichert und das gesamte Modell mit dem Python-Modul pickle in eine Bytestreamdatei verpackt und als Artefakt in einem Google Cloud Storage Bucket gespeichert.
Anwendung des Modells
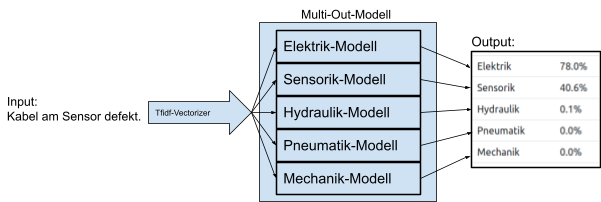
Zur Anwendung des Multi-Out-Modells wird die Problembeschreibung, die als Input dient, ebenfalls mit einem TF-IDF-Vectorizer in einen Wortvektor umgewandelt.
Der Vektor wird dann als Input in das Multi-Out-Modell gegeben, das ihn jeweils an die fünf internen Modelle weitergibt. Die einzelnen Modelle sagen dann jeweils die Wahrscheinlichkeit vorher, dass die Problembeschreibung zu der Kategorie gehört.
Das Objekt der Multi-Out-Klasse fügt diese Ergebnisse dann zusammen und gibt das Ergebnis als ein Dictionary zurück.
Outro
Das intelligente Service-Ticket-System ist eine Lösung, die entwickelt wurde, um die täglichen Arbeitsprozesse innerhalb der ESW-Gruppe zu erleichtern. Das System vereinfacht insbesondere die tägliche Arbeit der ESW-Mitarbeiter:innen. So müssen beispielsweise Maschinenführer:innen nicht mehr alle notwendigen Informationen in einen Auftrag eintragen, da viele Felder bereits vorausgefüllt sind.
Darüber hinaus werden Maschinenbedienenden die letzten, häufigsten oder ähnlichen Probleme vorgeschlagen, sodass sie keine zusätzliche Zeit für das Schreiben langer Problembeschreibungen aufwenden müssen. Zusätzlich wird ihnen eine Problemkategorie vorgeschlagen, um die Auftragserstellung weiter zu vereinfachen.
Techniker:innen profitieren ebenfalls von der Anwendung, da ihnen potenzielle Problemlösungen vorgeschlagen werden, was den Prozess der Auftragsbearbeitung beschleunigt. Ein: Teamleiter:in kann mit Hilfe von benutzerdefinierten Filtern (z. B. letzte/häufigste Probleme) einfach durch die Aufträge navigieren und erhält einen umfassenderen Überblick über die erstellten Aufträge.
Die ISTS App läuft in der Google Cloud unter Verwendung von Docker Images. Der „intelligente“ Teil der Anwendung ist in Form von zwei Machine-Learning-Modellen implementiert: dem intelligenten Suchmodell Word2Vec und Naive Bayes, zusammen mit logistischer Regression als Modell zur Klassifizierung von Kategorien. Zusätzlich wurde ein Clustering ähnlicher Probleme implementiert, um ähnliche Problembeschreibungen zu gruppieren und die häufigsten Probleme zu identifizieren.
Literaturverzeichnis
[1] SINGH, Prasoon. Deep Dive Into Word2Vec. Medium [online]. 13 September 2019 [viewed 19 October 2022]. Available from: https://medium.com/analytics-vidhya/deep-dive-into-word2vec-7fcefa765c17
[2] ANKERST, Mihael, et al. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod record, 1999, 28. Jg., Nr. 2, S. 49-60.
[3] BORCAN, Marius. TF-IDF Explained And Python Sklearn Implementation. Medium [online]. 08 June 2020 [viewed 23 October 2022].
Available from: https://towardsdatascience.com/tf-idf-explained-and-python-sklearn-implementation-b020c5e83275
[4] ESTER, Martin, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. In: kdd. 1996. S. 226-231.
[5] KHAN, Kamran, et al. DBSCAN: Past, present and future. In: The fifth international conference on the applications of digital information and web technologies (ICADIWT 2014). IEEE, 2014. S. 232-238.


