
Im letzten Teil dieser Artikelserie zu KubeEdge wird in einem Beispiel gezeigt, wie Daten von einem Sensor über die Edge bis hin zur Cloud gesendet werden. Die gesendeten Daten werden in der Cloud in einer Time Series Database abgelegt und anschließend über Grafana visualisiert.
Anwendungsfall
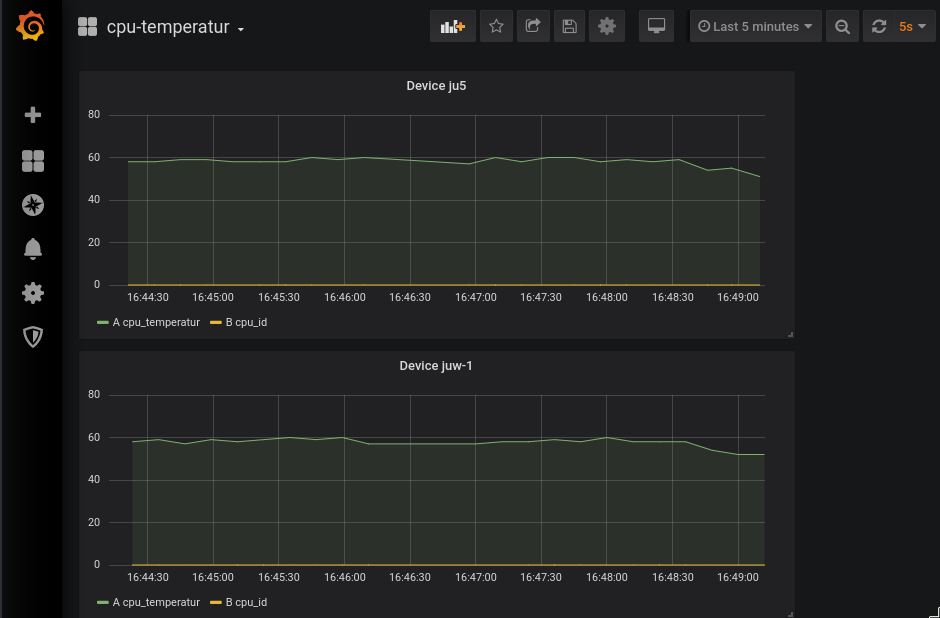
Im Anwendungsfall wird die CPU-Temperatur oder ein simulierter Wert erhoben und über MQTT an den EdgeCore gesendet. Der EdgeCore überträgt die Daten mit einem zusätzlichen MQTT Topic an die Kubernetes Cloud. Der DeviceController des CloudCores trägt die Daten daraufhin in die entsprechende Kubernetes-Ressource ein. Ein weiteres Programm, das ebenfalls im Cluster ausgeführt wird, speichert sie in einer Timeseries Datenbank und Grafana visualisiert sie in einem Dashboard – wie in der Abbildung „Grafana Ansicht„ dargestellt.

Insgesamt müssen für den Anwendungsfall vier Programmen auf der Edge oder der Cloud deployed werden. Die Abbildung „Komponenten Deployment“ zeigt, wo die Systeme deployed werden.
Funktionsweise und Grenzen des Anwendungsfalles
kubeedge-database
Die kubeedge-database Applikation wird die Daten aus den Ressourcen auslesen und in die Datenbank eintragen. Dafür werden die Device-Ressourcen abgerufen, die im vorherigen Artikel angelegt wurden. Über die Kubernetes API werden die Daten ausgelesen und in die Datenbank überführt.. Die nachfolgende Tabelle definiert, was die einzelnen Spalten für eine Bedeutung haben.
| Column | Datentyp | Beschreibung |
| time | Timestamp | Zeitstempel der Datenerhebung. |
| value | Text | Wert des Sensors. |
| namespace | Text | Kubernetes Namespace des Devices. |
| sensor | Text | Name des Sensors. |
| active | Bool | Dieser Wert zeigt an ob ein Device noch aktiv ist oder gelöscht wurde. |
| device | Text | Device Name |
Durch den Namespace, den Namen und das Device kann jeder Sensor eindeutig zugeordnet werden. Die eindeutige Zuordnung eines jeden Sensors hilft bei der Visualisierung der Daten in Grafana. Die Tabelle wird automatisiert beim Starten des Programms angelegt.
Grafana
Grafana ist ein Open Source Tool, das Daten über Dashboards visualisiert. Es wird häufig in Verbindung mit dem Monitoring Tool Prometheus eingesetzt. In diesem Anwendungsfall wird anstatt des Prometheus Backends ein PostgreSQL ausgewählt. Die Daten aus der PostgreSQL können so direkt in einen Graphen visualisiert werden. Die Verwendung von Variablen in der Abfrage ermöglicht es, die Anfrage auf unterschiedliche Devices und Sensoren zu begrenzen. Damit die Daten in einem Graphen angezeigt werden können, müssen sie zu einem Zahlenwert konvertiert werden. PostgreSQL / TimescaleDB
PostgreSQL ist ein Datenbankmanagement-System auf Open-Source-Basis, ähnlich wie MySQL oder MariaDB. In diesem Anwendungsfall wurde PostgreSQL verwendet, da es über das Plugin „TimescaleDB“ nativ Zeitreihen unterstützt. Die Datenbank wird in Kubernetes ohne persistente Speicherung der Daten betrieben. Wird die Datenbankinstanz also neugestartet, können alle Daten verloren sein. Für eine produktive Datenbank sollte daher auf die Persistierung der Daten geachtet werden, bspw. durch ein externes Speichermedium.
Sensor
Der Sensor ist in diesem Fall ein Programm, welches über das Tool „lm-sensors“ die CPU Temperatur ausliest oder Zufallszahlen generiert. Die Daten werden im Anschluss an den MQTT-Broker übertragen. Der Sensor arbeitet mit zwei Werten: die CPU-Temperatur, die dem entsprechenden gemessenen oder generierten Wert entspricht, und die die CPU-ID. Letzterer Wert wird im aktuellen Anwendungsfall nicht verwendet. Zwischen zwei gesendeten Werten vergehen in diesem Programm zehn Sekunden. Das Programm ist also in keinster Weise mit einem real existierenden Sensor vergleichbar, kann aber für erste Tests und ein Kennenlernen von KubeEdge gut verwendet werden.
Umsetzung Anwendungsfall
In diesem Abschnitt werden die Programme auf den entsprechenden Systemen deployed. Für die Interaktion mit dem Kubernetes Cluster wird das bekannte Tool “kubectl“ verwendet.
PostgreSQL / TimescaleDB
Zuerst wird die Datenbank im Cluster deployed, da einige andere Dienste auf dieser Aufbauen. Zum Deployen kann das nachfolgende Manifest genutzt werden. In der Ressource wird automatisch ein Passwort für die Datenbank angelegt, das auf ein entsprechend sicheres Passwort geändert werden sollte. Die Datenbank wird als Kubernetes Deployment erstellt und ein Service für die interne Kommunikation angelegt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
apiVersion: v1 kind: Secret metadata: name: timescale-rootpw type: Opaque stringData: password: changeme --- apiVersion: v1 kind: Service metadata: name: timescale spec: selector: app: timescale ports: - protocol: TCP port: 5432 targetPort: 5432 name: postgres --- apiVersion: apps/v1 kind: Deployment metadata: name: timescale labels: app: timescale spec: selector: matchLabels: app: timescale template: metadata: labels: app: timescale spec: containers: - name: timescale image: timescale/timescaledb:1.4.1-pg11 env: - name: POSTGRESQL_PORT_NUMBER value: "5432" - name: POSTGRES_PASSWORD valueFrom: secretKeyRef: name: timescale-rootpw key: password ports: - containerPort: 5432 protocol: TCP name: postgres |
Dieser Abschnitt beschreibt das Anlegen unterschiedlicher Rollen, die für einzelne Datenbanken genutzt werden sollen. Das Einrichten der Datenbankschemata wird über den “kubectl exec“ Befehl durchgeführt. Dieser erlaubt es, andere Befehle direkt im Container eines Pods auszuführen. Eine Alternative wäre das Erstellen eines Kubernetes Jobs um die Datenbankschemata zu erstellen.
|
1 2 3 4 5 6 7 |
POD_NAME=$(kubectl get po -l app=timescale -o jsonpath='{.items[0].metadata.name}') kubectl exec -ti ${POD_NAME} -- psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE ROLE kubeedge WITH LOGIN PASSWORD 'kubeedge'; CREATE ROLE grafana WITH LOGIN PASSWORD 'grafana';" kubectl exec -ti ${POD_NAME} -- psql -U postgres -c "CREATE DATABASE grafana WITH OWNER grafana" kubectl exec -ti ${POD_NAME} -- psql -U postgres -c "CREATE DATABASE demo WITH OWNER kubeedge" |
kubeedge-database
Abschließend wird die kubeedge-database Applikation gestartet und ebenfalls im Cluster deployed. Hierzu kann einfach die in dem Repository https://github.com/subpathdev/kubeedge-database liegende Definition verwendet werden. Im Anschluss muss noch das Passwort für die Datenbank und der entsprechende Nutzer gesetzt werden. Der Nachfolgende Codeblock zeigt, wie das Deployment ausgeführt wird. Für die Eingabe des Nutzers und des Passwortes wird in dem Codeblock der zuvor bereits angelegte Nutzer mit seinem Passwort gesetzt.
|
1 2 3 4 5 6 7 |
curl https://raw.githubusercontent.com/subpathdev/kubeedge-database/master/kubernetes.yaml -o kubeedge-database.yaml sed -i 's/user: demo/user: kubeedge/g' kubeedge-database.yaml sed -i 's/password: test-password/password: kubeedge'/g' kubeedge-database.yaml kubectl apply -f kubeedge-database.yaml |
View (Edge-Applikation)
Zum Visualisieren wird Grafana deployed. Grafana ist in diesem Deployment so definiert, dass es zur Datensicherung die Datenbank verwendet. Das Grafana Deployment ist ebenfalls im Github Repository verfügbar und kann mit folgendem Befehl auf das Cluster deployed werden. Hier sollte das Passwort entsprechend angepasst werden. Das Administrator-Passwort für Grafana wird auf verryStrongPassword gesetzt.
|
1 2 3 4 5 6 7 |
curl https://raw.githubusercontent.com/subpathdev/kubeedge-database/master/grafana.yaml -o grafana.yaml # nun wird das Passwort verändert sed -i ‘s/test-grafana-password/grafana/g’ grafana.yaml kubectl apply -f grafana.yaml |
Nun kann über die Adresse des Master-Nodes und dem Port 30975 auf Grafana zugegriffen werden. Es existiert aktuell nur ein Nutzer (admin) mit dem Passwort „verryStrongPassword“. Hier muss eine neue Datenbankverbindung angelegt werden. Dazu wird „Create your first data source“ ausgewählt. Als Datenquellen wird PostgreSQL selektiert. Für die Konfigurationen dient nachfolgende Tabelle als Hilfe.
| Konfiguration | Wert |
| Host | timescale.default.svc.cluster.local |
| Database | demo |
| User | kubeedge |
| Passwort | kubeedge |
| SSL-Mode | disable |
Nach dem Anlegen der Datenverbindung werden die Dashboards erstellt. Am einfachsten ist es, die beiden Dashboards über die folgenden Befehle herunterzuladen und in Grafana zu importieren.
|
1 2 3 |
curl https://raw.githubusercontent.com/subpathdev/kubeedge-database/master/Devices.json -o Devices.json curl https://raw.githubusercontent.com/subpathdev/kubeedge-database/master/Sensors.json -o Sensors.json |
Über das Plus-Symbol kann der Import der Dashboards ausgewählt werden. Mit „Upload .json“ können die Devices.json- und Sensor.json-Dateien in Grafana importiert werden. In der Abbildung “Dashboard hinzufügen“ ist dieser Schritt visualisiert.
Sensor
Zum Abschluss des Installationsabschnitts wird der Sensor auf dem Edge und im Cluster deployed. Die Anwendung steht als Container zur Verfügung sodass diese mit den CLI-Parametern gestartet werden kann. Die Parameter sind in der nachfolgenden Tabelle mit einer Beschreibung definiert.
| Parameter | Beschreibung |
| deviceID | Setzt die DeviceID. Diese ist beim Anlegen der Kubernetes-Ressource von Bedeutung. Der Standardwert für die Device ID ist: “43098512438508132096394-a41fcb“ |
| ipAddress | Ist die IP-Adresse des MQTT-Brokers inkluse des Ports. Der Standardwert ist hier „tcp://127.0.0.1:1884“. |
| user | Einige MQTT-Broker unterstützen User-Password-basierte Authentifizierung. Der MQTT-Nutzer wird mit dieser Flag gesetzt. |
| password | Ist das Passwort, welches zum MQTT-Nutzer gehört |
| simulate | Die Daten werden nicht mithilfe des Tools lm-sensors ausgelesen. Stattdessen werden random-Daten generiert und an den Broker gesendet. |
Die beiden nachfolgenden Befehle zeigen, wie das Programm gestartet und das Device im Cluster angelegt wird. Zum Starten wird auf einer nicht-virtuellen Edge folgender Befehl verwendet: „docker run subpathdev/cpu_temp_mqtt_client:v0.1 -deviceID cpu-sensor-01“
Sollte eine virtuelle Edge verwendet werden, wird zusätzlich noch das „simulate“-Flag gesetzt:
„docker run subpathdev/cpu_temp_mqtt_client:v0.1 -deviceID cpu-sensor-01 -simulate“
Zum Anlegen des Devices wird zuerst ein DeviceModel erstellt. Dieses kann kann einfach aus dem Repository „https://github.com/subpathdev/CpuTempMqttClient/“ entnommen werden.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
kubectl apply -f https://raw.githubusercontent.com/subpathdev/CpuTempMqttClient/master/deviceModel.yaml cat <<EOF | kubectl apply -f - apiVersion: devices.kubeedge.io/v1alpha1 kind: Device metadata: name: cpu-sensor-01 labels: model: cpu-sensor description: Cpu-Sensor spec: deviceModelRef: name: cpu-sensor nodeSelector: node-role.kubernetes.io/edge: "" status: twins: propertyName: CPU_Temperatur reported: value: “0” metadata: type: int propertyName: cpu_id reported: value: “0” metadata: type: int EOF |
Nun wird alle zehn Sekunden ein Wert gemessen bzw. generiert. Dieser Wert wird an den MQTT-Broker gesendet, dann an die Kubernetes API übertragen, in der Datenbank gespeichert und über Grafana visualisiert.
Bei Fragen oder Anmerkungen kann die KubeEdge Community wie folgt erreicht werden:
- Mailingliste ( https://groups.google.com/forum/#!forum/kubeedge )
- Slack-Workspace ( https://join.slack.com/t/kubeedge/shared_invite/enQtNjc0MTg2NTg2MTk0LWJmOTBmOGRkZWNhMTVkNGU1ZjkwNDY4MTY4YTAwNDAyMjRkMjdlMjIzYmMxODY1NGZjYzc4MWM5YmIxZjU1ZDI )
- Twitter ( https://twitter.com/kubeedge )
Quellen
- https://kubeedge.io/en
- https://github.com/kubeedge/kubeedge
- Schulungsunterlagen: LFS458 Kubernetes Administration (Linux Foundation)
- https://www.hpe.com/emea_europe/en/what-is/edge-computing.html#targetText=Edge%20computing%20is%20the%20practice,a%20centralised%20data-processing%20warehouse.
- https://github.com/rancher/k3s
Die Inhalte dieser Arbeit stammen aus dem Projekt KOSMoS – Kollaborative Smart Contracting Plattform für digitale Wertschöpfungsnetze. Dieses Forschungs- und Entwicklungsprojekt wird mit Mitteln des Bundesministeriums für Bildung und Forschung (BMBF) im Programm „Innovationen für die Produktion, Dienstleistung und Arbeit von morgen“ (Förderkennzeichen 02P17D026) gefördert und vom Projektträger Karlsruhe (PTKA) betreut. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt bei den Autor:innen.


