In this blog post, I will compare four tools for machine learning experiment tracking. A similar comparison has already been presented about two years ago in this blog post about Frameworks for Machine Learning Model Management. However, the present article will differ in the tools examined. In the previous post the open-source tools MLflow, Sacred, and DVC have been compared. The present comparison will include the open-source tools ClearML, MLflow as well as the closed-source options DAGsHub and Neptune.
Many components influence whether a machine learning model experiment can be considered a success. Besides the hyperparameters which are used to configure the machine learning algorithm, the data used to train the model, the code used during training play a crucial role. In addition, the computational environment, which includes software dependencies and hardware specifications is important as well. Usually, an experiment produces one or multiple models and is evaluated by calculating metrics, which assess the quality of a model/experiment.
All those dependencies should be stored and be accessible through the experiment tracking tool. The general structure of the tools is as shown in figure 1:
MLflow
MLflow is probably the oldest and most widely used tool. As it is open-source, it can be used for free. The fundamentals of MLflow have already been described in the former blog post. However, I will also give a short introduction here.
To make the comparison between the tools as easy as possible, the code will focus on the tools and not include any actual training code in the code snippets.
|
1 2 3 4 5 6 7 8 9 |
import mlflow mlflow.set_tracking_uri("postgresql://postgres:postgres@172.3...) mlflow.set_experiment("project1") #group runs with mlflow.start_run() as run: hyperparams = {"lr": 0.01,} mlflow.log_params(hyperparams) #Train a model with pytorch and store it in the var “model” mlflow.pytorch.log_model(model, "log_r",) mlflow.log_metric("acc", 0.99) |
To start tracking with MLflow, a run has to be started. By using a context manager, the run will be ended automatically. MLflow differentiates between metrics and params; both can be logged to MLflow by using the respective function. MLflow provides functions to log one value (in which case the first parameter is the name of the value, and the second parameter is the value itself, line 9), or to log multiple values (here a dictionary is passed as the only parameter and the name and values of the dictionary will be used line 6).
Grouping multiple runs together allows easy viewing and comparison in the UI. This can be achieved by setting an experiment (line 3).
Metadata (params, metrics, etc.) are by default stored in a local text file. However, other possibilities exist; such as saving them in a SQL Database, which can be achieved by specifying a tracking URI (line 4).
By default, models logged with MLflow are stored in the local file system. Though it is possible to change the location, e.g. to an S3 bucket.
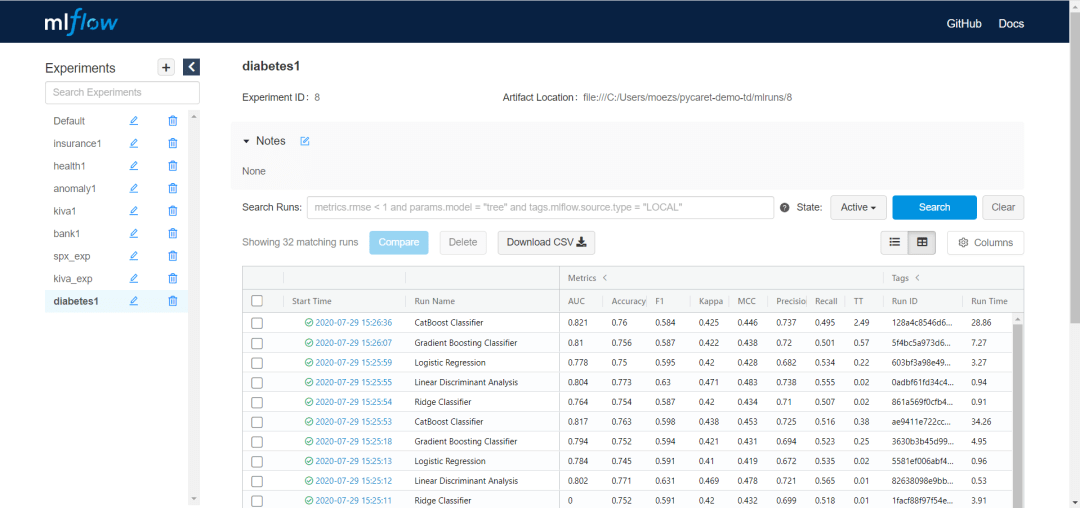
MLflow provides requirements to keep track of machine learning experiments. It does not provide a dedicated way to keep track of the data used for training, however. It does not support automated tracking of the environment either. It can be used for free in teams, however, this requires shared data storage which has to be set up by yourself.
Neptune
Neptune is a tool developed by Neptune Labs. While the Client Software (Python Package) is open-source, the server code is not publicly available. Free as well as paid plans exist.
To get started with Neptune, an account has to be created at neptune.ai and an API token has to be generated. To track experiments the API token has to be set as an environment variable and a project (similar to an experiment in MLflow) has to be created in the Neptune Web App. After those setup steps, Neptune is ready to go.
|
1 2 3 4 5 6 7 8 9 |
import neptune.new as neptune run = neptune.init(project="tbud/Conv2AI") hyperparams = {"lr": 0.01,} run["hyperparams"] = hyperparams #Training run["loss/train"].log(the_current_loss) torch.save(model, "log_r.mdl") run["model"].upload("log_r.mdl") run["acc"] = 0.99 |
After importing the new Neptune API, we can initialize a run and assign it to a project.
Neptune does not differentiate between metrics and hyperparameters. To log values with Neptune, a notation with square brackets and strings as keys (e.g. run[„some_key“]) is used, which is similar to accessing a value in a dict. To track series such as the loss, the log function has to be used. This automatically generates a plot in the GUI. To upload a trained model, it first has to be saved locally and can then be uploaded to Neptune using the upload function.
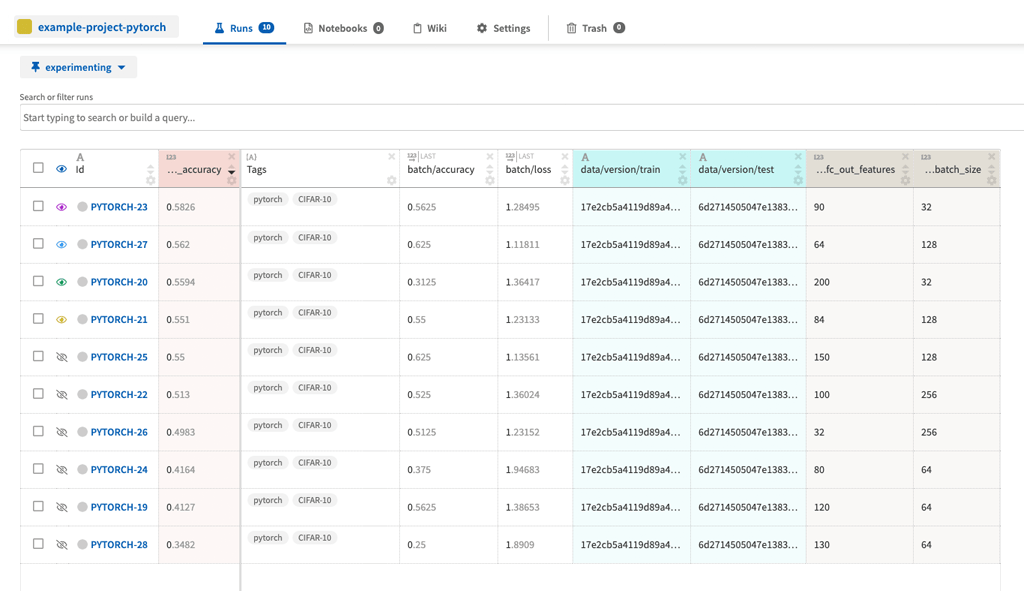
The GUI of Neptune looks similar to the MLflow GUI. It includes all the basic functionalities that MLflow has but also has additional nice-to-have features such as query completion for filtering or an option to save customized views.
Similar to MLflow, Neptune’s focus is tracking metrics and hyperparameters. The setup is easier as with MLflow, however, using Neptune raises Data Governance questions. For single users Neptune can be used for free. When working in teams, a paid plan is needed and the prize is calculated based on the usage.
ClearML
ClearML is open-source developed by Allegro AI, it was formerly known as Allegro Trains. Multiple options to use ClearML exist, it can be self-managed for free, used with a free as-a-Service plan for up to three team members or used with a paid plan.
|
1 2 3 4 5 6 7 8 9 |
from clearml import Task, Logger, Dataset path = Dataset.get(dataset_project="Project/data", dataset_name="ds_1").get_local_copy() task = Task.init(project_name="Demo", task_name="Task1", reuse_last_task_id=False, output_uri="gs://tb_project1",) hyperparams = {"lr": 0.01,} task.connect(hyperparams) #Training … torch.save(model, "log_r.mdl") task.get_logger().report_scalar("model", "accuracy", 0.99, 0) |
Compared to the other tools, ClearML has in my opinion the most difficult but powerful API. Besides its hyperparameter and metric tracking capabilities, ClearML provides a possibility to store and manage datasets. It works similar to Data Version Control (before up- or downloading files, hash sums are checked to avoid traffic if the data has not changed). This allows versioning Datasets even for binary files.
To get the local path to a dataset managed with ClearML, the dataset has to be queried with the Dataset.get() function. The get_local_copy() function ensures that a local copy is available and returns the path which can then be used for training.
In ClearML, a task is similar to a run in MLflow and describes something that is executed and should be tracked. In line 4 a task is initialized and assigned to a project. Setting reuse_last_task_id to False ensures that this task will not override an old task. The output_uri specifies the location for the artifacts (e.g. the model) and is in this example set to a Google Cloud Storage. By initializing a task, the tracking is automatically started. ClearML allows logging hyperparameters by connecting an object to a task.
When a model is saved locally, ClearML automatically uploads it to the artifact store and connects it to the task.
Metrics can be reported to a logger, where the first argument is the title of the plot, the second is the name of the series, the third is the value and the last is the iteration (x-coordinate). It should be noted that executing Task.init automatically tracks the used python packages and their versions, providing an additional amount of information.

While the overview table of the experiments looks similar to Neptune and MLflow, the detailed view of the task is very nested and can easily overwhelm new users. This is in my opinion the biggest downside of ClearML compared to the other tools: due to its huge amount of possibilities it requires more time to familiarize. However, I think this time is well invested since ClearML provides a lot of options and possibilities for the user – not only because it can be used for free but as well as a hosted service.
DAGsHub
In contrast to the other presented tools, DAGsHub offers a different approach. It makes use of existing open-source technologies and provides unified storage and GUI for them (DAGsHub itself is not open-source though):
- DVC is used to keep track of the data and models
- Git keeps track of the code
- MLflow or the DAGsHub Client can be used to track hyperparameters and metrics
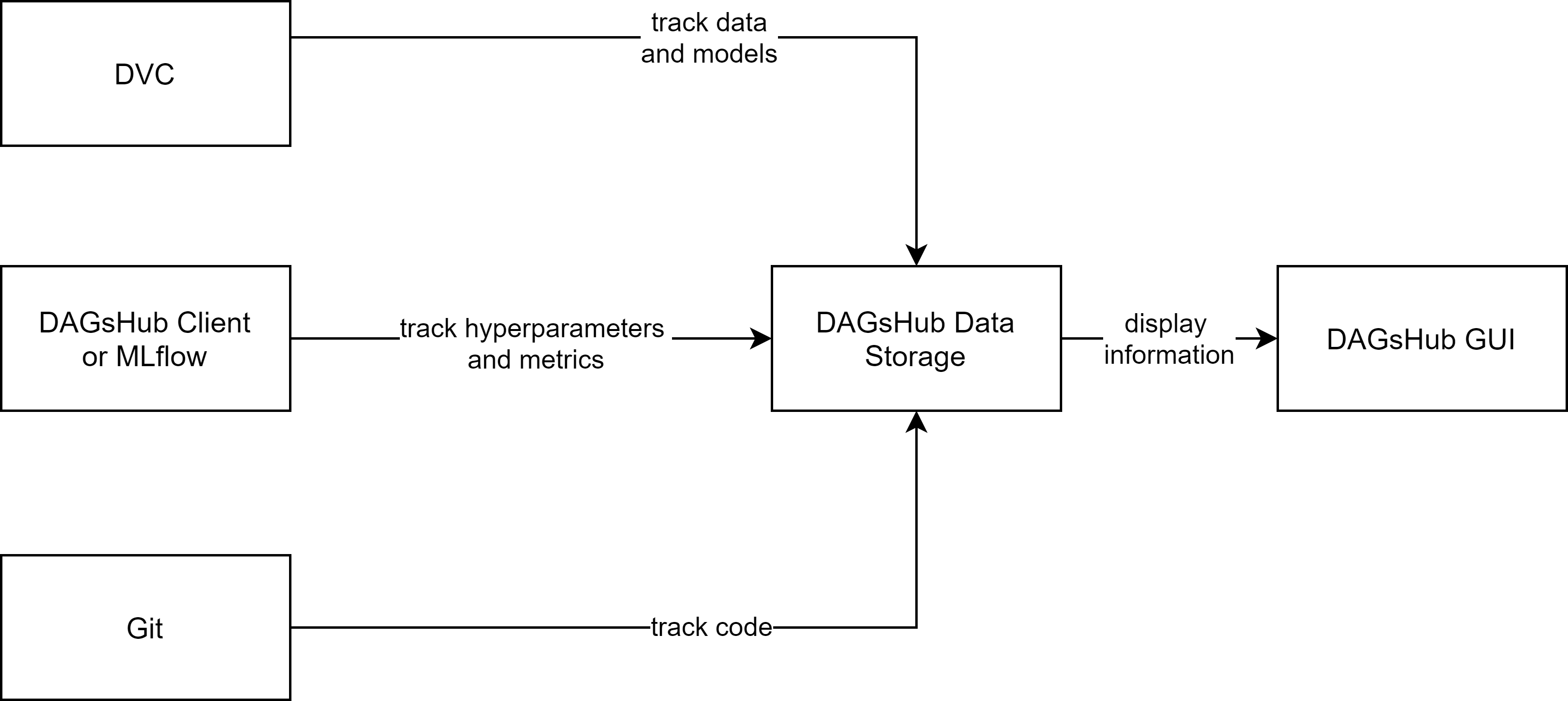
As a result, the code to track hyperparameters and metrics with MLflow can be reused for DAGsHub in a similar fashion. The most important advantage of DAGsHub is the unified storage and its GUI for machine learning projects.
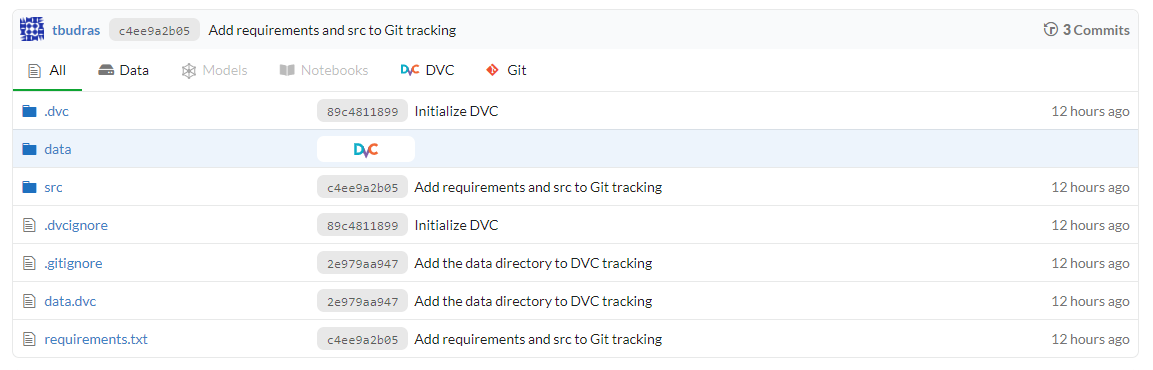
With a free DAGsHub plan, the number of collaborators and storage is limited. Paid plans exist which allow working in bigger teams. DAGsHub probably has the most potential for teams that already use DVC and/or MLflow and want to keep using the tools but would benefit from unified storage and GUI.
Summary
In this blog post the four machine learning experiment tracking tools MLflow, ClearML, Neptune and DAGsHub have been introduced.
All tools provide sufficient capabilities to track hyperparameters and metrics. They have different strengths and weaknesses when it comes to ease of use, pricing and more advanced requirements such as tracking data or computational environment.
MLflow has a well-structured API and can be used for free. Neptune, on the other hand, offers a simple setup and highly functional GUI but requires a paid plan. In comparison to the two previous tools, ClearML handles the tracking of data and the computational environment. Additionally, it is open-source and can be self-hosted or used as a free or paid Service. DAGsHub can be considered as a good choice for teams already using DVC and MLflow who like to have unified storage and GUI.


