Notice:
This post is older than 5 years – the content might be outdated.
tl;dr (spoiler alert): We’ve trained an advanced neural network to query Elasticsearch based on natural language questions. Our model, called SeqPolicyNet, incorporates feedback from the retrieved database response by leveraging policy-based reinforcement learning. Hence, we overcome the non-differentiability of database operations and maintain the end-to-end trainability of our model. In our experiments SeqPolicyNet outperforms Memory Networks on Facebook’s bAbI Movie Dialog dataset and generalizes on unknown question patterns.
Motivation
Interest in using natural language as a universal interface has been increasing for quite some time. In the past years we have become used to giving short commands to our personal assistants Siri or Cortana. But while you can still control your smartphone via its touchscreen, devices like Google Home or Amazon Echo rely on voice as their only interface. Just recently, Google announced Google Duplex [1], which is able to perform phone calls to schedule your hairdressers‘ appointment or to reserve a table in a restaurant. These are stunning developments and one can only imagine where this will take us.
Many real-world challenges require using external background knowledge. In this article, we leverage natural language as a tool to query databases that store this information. Thereby, we address the barrier raised by domain-specific query languages. Many people do not know how to query a database and are therefore incapable to access the stored knowledge.
Wouldn’t it be great, if we could just type:
Who was the author of True Lies?
instead of the following statement?
{ „_source“: [ „author“ ], „query“: { „bool“: { „must“: [ { „term“: { „movie“: „true“ } }, { „term“: { „movie“: „lies“ } } ] } } }
The Task
The bAbI project [2] is a Facebook initiative to foster the development of conversational agents. For this project, we select a dataset out of bAbI following two conditions. First, our task needs to provide an external knowledge base (KB) in order to involve one of today’s prevalent databases. We will integrate Elasticsearch, which is one of the most popular NoSQL databases and dominant in search-related applications [3]. A major obstacle with database interaction is the non-differentiability of queries. Hence, models can either leverage intermediate labels or rely on reinforcement learning for training. Since intermediate labels are costly to produce and typically not available in real-world challenges, our second requirement is that our task should capture an end-to-end setting.
The Movie Dialog dataset [4] satisfies both of our requirements. On the one hand it comes with a KB that incorporates metadata about 17k films. On the other hand, the dataset challenges models to respond to natural language questions in a single-shot manner. The dataset consists of a pre-defined split of 96k samples for training, 10k for validation and 10k for testing. Each sample consists of a question-answer pair as shown below.
Who was the writer of True Lies? – Claude Zidi, James Cameron
What year was the movie Avatar released? – 2009
Who starred in The Dark Knight Rises? – Tom Hardy, Gary Oldman, Christian Bale
Our Approach
In this section we will introduce a QA system, which we call SeqPolicyNet. SeqPolicyNet will be used to solve the proposed task and learn to produce database queries given natural language questions. Thereby, our model only considers feedback from the retrieved response and does not leverage intermediate labels. For this reason, SeqPolicyNet is end-to-end trainable and can be distinguished from related approaches, like e.g. Seq2SQL [5]. The following figure shows the overall system architecture of SeqPolicyNet.

PointerNet is the core component of our model. Generally speaking, PointerNet processes the natural language inputs to a fixed-sized length output sequence. This happens in four consecutive steps that follow the framework: embed, encode, attend and predict [6, 7]. Afterwards, PointerNets output sequence is used to fill the query template and produce a domain-specific query. Eventually, the actual query is operated on Elasticsearch and the retrieved response is presented to the user.
Step 1: Using Embeddings to Create Word-Level Vector Representations
In a first step, the inputs are lowercased and transformed into their corresponding GloVe embeddings [8]. Embeddings are continuous vector representations of words which capture their semantic information. Our example: „Who was the writer of True Lies ?“ consists of seven words and the question mark. Furthermore, the database contains eleven categories, e.g. „author“ or „genre“. Hence, the embedding of these inputs would yield a tensor with 19 x 300 dimensions, where each word is represented by a 300-dimensional vector.

Step 2: Encoding the Word-Level Information into a Sequence-Level Representation
We designed PointerNet as a sequence-to-sequence (Seq2Seq) model [9]. The encoder receives the embedded inputs and transforms them into a single hidden state, called thought vector. While embeddings capture the meaning of individual words, one can think of the thought vector as a summary of the input sequence. In order to perform this transformation, our encoder is implemented as a two-layer bi-directional LSTM [10]. Bi-directional means that the LSTM can read the input sequence forward and backwards. Eventually, the thought vector results from concatenating the final hidden states of both layers and directions. Our encoder produces a 200-dimensional hidden state which is passed to the decoder.

Step 3: Attention Emphasises Important Inputs During Decoding
Our decoder is implemented as a two-layer uni-directional LSTM. Furthermore, we use pointer attention [11]. Attention mechanisms are inspired by the human ability to focus. When human are asked to identify friends in a picture, we do not inspect every pixel but concentrate on regions including faces. In the same manner, attention mechanisms enable the decoder to focus on certain parts of the input.
Given the thought vector and previous predictions, the decoder computes a probability distribution (attention vector) over the inputs to determine their importance. The following figure shows two different attentions over the database columns. In line A, the decoder considers multiple columns as relevant, at least movie, director and author. However, in line B author appears to be the only important column.

(A) Multiple relevant columns, e.g. director and author.
(B) The decoder accounts a high importance to author.
Step 4: Predicting the Output Sequence
Let’s assume that \(a_t\) represents the attention vector while predicting the t-th token of the output sequence. One can also look at it as a probability distribution over the input vocabulary. Since we use pointer attention, we consider\(pi(y_t|y_1, …, y_{t-1}, x, theta)\) to be a stochastic policy which is defined by the distribution\(a_t\). Hence, the token\(y_t\) is sampled from this distribution \(y ~ pi\).
This is the final step performed by PointerNet. In total, PointerNet outputs sequences with the length of four. These sequences are used to fill the query template and produce a domain-specific query.
Step 5: Using PointerNet’s Output to Produce a Query (Query Template)
The query template works as an interface between PointerNet and Elasticsearch. Therefore, PointerNet’s output sequences are either used to select a database column (selection pointer) or for entity extraction (extraction pointer). In the following figure we provide an example of the usage of these pointers.
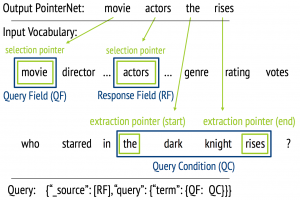
The extraction pointers are used to identify the query condition (QC). Due to the fact that we use them as start and end pointer, we can capture entities that are composed by a span of tokens with only two pointers. This allows us to extract entities of variable length with a reduced complexity. Furthermore, we identify the query field (QF), referring to the database column of the QC, and the response field (RF), defining the column containing the answer. The filled query template interfaces with Elasticsearch and operates the actual query.
Leveraging the Database Response for Training
The execution of the produced query yields a response by Elasticsearch. This response can consist of multiple entities, e.g. the authors Claude Zidi and James Cameron. In order to train our model on this feedback we match the database response with the ground-truth answer. Below we present several queries that were created from the same question and result in different responses.
| Who was the writer of True Lies?—Claude Zidi, James Cameron | ||||
|---|---|---|---|---|
| Query # | 1 | 2 | 3 | 4 |
| Query Field | movie | movie | movie | movie |
| Query Condition | the true lies | writer | true lies | true lies |
| Response Field | author | author | year | author |
| Response | {} | Roman Polanski | 1994 | Claude Zidi, James Cameron |
| Reward | -2 | -1 | -1 | +z |
Since the execution of queries is non-differentiable, we rely on deep reinforcement learning to train our model. While empty responses (-2) and valid queries with incorrect results (-1) are penalized, we reward valid queries yielding correct results (+z). Throughout our experiments we vary the size of z.
Formulating a reward function allows us to update the weights of PolicyNet by using REINFORCE. By sampling trajectories, we observe the episodic rewards and gradients of the stochastic policy and thereby update our network.
A major problem that we observed in our initial experiments, was SeqPolicyNet getting stuck in local optima. A simple solution to this problem was the introduction of a count-based reward boni \(R^+\), which we provided for the selection of rarely chosen column names in the QF and RF. Thereby, we incited SeqPolicyNet to explore unknown its environment instead of maximising its reward around local optima. The design of our exploration boni is inspired by upper confidence bounds [12].
Results
We compare our results to the state-of-the-art on the Movie Dialog dataset. The original paper [4] found promising performance of Memory Networks (MemNNs), only outperformed by a QA system based on Bordes, Chopra and Weston (2014) [13]. In later work on the adjusted WikiMovies dataset [14], MemNN even outperformed this QA system. For this reason, we consider MemNNs the most important benchmark for our approach.
We evaluate three different variants of our model. Firstly, we train SeqPolicyNet without boni and\(z=1\), which results in a reward function similar to the one of Seq2SQL. Our second variant is trained with highly increased reward \(z=25\) for correct results. Eventually, the third variant of SeqPolicyNet is trained with activated exploration boni. To determine the benefit resulting from available intermediate labels, we train PointerNet directly on these labels. This model, denoted as PointerNet-IL, runs out of competition since it requires human intervention for annotation and is not end-to-end trainable.
Furthermore, we define two metrics for evaluation purposes. Let \(Acc_vq\) denote the percentage of produced valid queries, i.e. queries that retrieve a non-empty response. Furthermore,\(Acc_cr\) is defined as the percentage of queries that yielded a correct result.
| Methods | \(Acc_{vq}\) | \(Acc_{cr}\) |
|---|---|---|
| Baseline LSTM | - | 6.5% |
| Supervised embeddings (ensemble) | - | 43.6% |
| Supervised Embeddings | - | 50.9% |
| MemNN | - | 79.3% |
| MemNN (ensemble) | - | 83.5% |
| QA system | - | 90.7% |
| SeqPolicyNet \(z = 1\) | 99.0% | 0% |
| SeqPolicyNet \(z = 25\) | 83.3% | 54.5% |
| SeqPolicyNet \(z = 25 \& R^+\) | 91.3% | 84.2% |
| PointerNet-IL | 93.9% | 90.6% |
The Design of the Reward Function Matters
Comparing the first and second variant of SeqPolicyNet (\(z=1\) vs.\(z=25\)) indicates that reward function design is crucial to performance. We observed that SeqPolicyNet gets trapped in local optima if we use a reward function similar to Seq2SQL. In this case, the model tends to produce simplistic queries. For the selection pointers it almost always chooses the pre-dominant column movie. Additionally, in most cases the extracted entity consists of a single word. Thereby, SeqPolicyNet focusses on the production of valid queries by avoiding queries that may result in empty responses.
Adjusting the reward function had several effects on the predictive behavior of SeqPolicyNet. The prediction of the RF shows an increased entropy, indicating that SeqPolicyNet derives from selecting the predominant column. Furthermore, the average length of the QC doubled. We did not notice a change in behavior of predicting QF, where SeqPolicyNet still predicts the column movie. However, these changes in the predictive behaviour caused a decreased share of valid queries, whereas the percentage of correct results highly increased.
It appears that for low positive rewards, which are sparse, the positive effect of additional correct results is outweighed by queries that become invalid. We account this to the weight updates, which involve averaging over the trajectories of the mini-batch. Increasing the positive rewards enhances the feedback signal and allows to overcome the local optima.
Outperforming MemNNs with Active Exploration Boni
Activating the reward boni in order to induce exploration has a positive impact on performance. We found that SeqPolicyNet derives from predicting the pre-dominant column in the QF and now outperforms MemNNs.
Although SeqPolicyNet with reward boni is not able to achieve the performance of the QA system. Leveraging intermediate labels raises our PointerNet-IL on the same level. This highlights the advantage of having a differentiable cost functional in supervised learning compared to a reinforcement learning approach.
SeqPolicyNet Generalizes on Unknown Question Patterns
We removed a randomly selected set of question patterns from training data to obtain a generalisation set. Training our model on this reduced set resulted in a slightly reduced performance. As expected, there was no difference for patterns seen in training. However, there was a drop in performance for unknown question patterns. We found that this was mainly due to queries that need the RF to be the column actor. Further analysis revealed that this class of questions is underrepresented and there is too few variation for SeqPolicyNet to learn this pattern sufficiently. The following figure illustrates this problem. While SeqPolicyNet selected the correct RF in epoch 40, the policy switches back to year in the following epochs.

Despite this underrepresentation problem we find that SeqPolicyNet generalises well. We attribute this to the Seq2Seq architecture as well as to the use of pre-trained word embeddings.
Conclusion
In this article we discussed an application of deep learning to interact with a database through natural language. Thereby, we addressed the problem raised by the existence of domain-specific query languages, which hinder many people from accessing information. A major obstacle for the application of neural networks in this setting is the non-differentiability of database operations. Traditional attempts leverage intermediate labels and therefore break the end-to-end trainability of the system. Furthermore, these approaches face increased costs due to the data annotation by experts.
In contrast, we use deep reinforcement learning to bridge the gap of non-differentiability. Hence, SeqPolicyNet is trained on question-answer pairs and does not require human intervention. We found that SeqPolicyNet using count-based reward boni outperforms the well-known MemNNs. In addition, the utilisation of pre-trained embeddings and a Seq2Seq architecture enables SeqPolicyNet to generalise on unknown question patterns.
Lessons Learned
- Deep Reinforcement Learning is
- Sensitive to the reward function design
- Instable: for our best model we observed that single runs deviated by about 8pp from the mean performance.
- Sample inefficient: Training SeqPolicyNet on a reduced training set (10k examples) lead to a drop in performance (-53.2pp). In contrast, PolicyNet-IL which used the intermediate labels performed only slightly worse (-1.5pp).
- There is an interesting blog post by Alex Irpan which deals with these topics
- Latencies to Elasticsearch are an important runtime issue
- Training on SeqPolicyNet on the 96k set for 50 epochs took ~12h on a single GPU
- Exploration boni
- Count-based boni are simple to apply, but work surprisingly well
- We did not try other methods like pseudo-counts or noise injection into parameter-/action-space
- Pre-trained embeddings are incredibly helpful
- Ambiguities in the KB cause about 4% of faulty results
- E.g. there are four movies called the three musketeers, released in 1973, 1993, 1994 and 2011 respectively. Even a human-in-the-loop would struggle to pick the right one when asked: „What was the release date of the film the three musketeers?“.
Read on
Find the whole thesis available for download at inovex.de.
References
[1] Google Duplex: Link
[2] The bAbI project: Link
[3] DB-Engines Ranking: Link
[4] Dodge, J., Gane, A., Zhang, X., Bordes, A., Chopra, S., Miller, A., … & Weston, J. (2015). Evaluating prerequisite qualities for learning end-to-end dialog systems. arXiv preprint arXiv:1511.06931.
[5] Zhong, V., Xiong, C., & Socher, R. (2017). Seq2SQL: Generating structured queries from natural language using reinforcement learning. arXiv preprint arXiv:1709.00103.
[6] Embed, Encode, Attend, Predict (explosion.ai): Link
[7] NLP-pipeline with word embeddings (einstein.ai): Link
[8] Pennington, J., Socher, R., & Manning, C. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
[9] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).
[10] Introduction to LSTMs: Link
[11] Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer networks. In Advances in Neural Information Processing Systems (pp. 2692-2700).
[12] Lai, T. L., & Robbins, H. (1985). Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6(1), 4-22.
[13] Bordes, A., Chopra, S., & Weston, J. (2014). Question answering with subgraph embeddings. arXiv preprint arXiv:1406.3676.
[14] Miller, A., Fisch, A., Dodge, J., Karimi, A. H., Bordes, A., & Weston, J. (2016). Key-value memory networks for directly reading documents. arXiv preprint arXiv:1606.03126.