
Machine Learning Algorithmen findet man mittlerweile überall: auf dem Smartphone, im Auto, auf Cloud-Servern, usw. Allerdings haben diese Algorithmen oft hohe Anforderungen an Rechenleistung und Speicherkapazität. Ist es möglich, ein Machine Learning Modell auf einem kleinen und leistungsschwachen, aber dafür sehr günstigen Gerät zu implementieren?
Die Anwendungsfelder für solche Algorithmen sind vielfältig, wie zum Beispiel Wearables, die Sensordaten on-board auswerten oder IoT-Setups mit geringer Bandbreite oder gar keiner Internetverbindung.
Um diese Anwendungen zu ermöglichen, müssen Machine Learning Modelle entwickelt werden, die so kompakt sind, dass sie auf einen Mikrocontroller mit wenigen MB Speicher passen und mit begrenzter Rechenleistung ausgeführt werden können.
In diesem Blog-Artikel beleuchten wir diese Problemstellung näher und stellen die Herausforderungen sowie mögliche Lösungswege anhand eines Showcases der TinyML-Technologie vor.
Was ist TinyML?
Der Begriff TinyML (Tiny Machine Learning) ist nicht streng definiert. Die „tinyML Foundation“ umschreibt mit diesem Begriff ein „schnell wachsendes Feld an Machine-Learning-Technologien und -Anwendungen einschließlich Hardware, Algorithmen und Software, die in der Lage sind, mit sehr niedrigem Stromverbrauch on-device Sensordaten zu analysieren. Dies ermöglicht eine Reihe von always-on Use Cases und zielt auch auf akkubetriebene Geräte ab.“
Ein TinyML-Projekt zeichnet sich maßgeblich durch einen optimalen Kompromiss zwischen der Performance (Inferenzzeit und Genauigkeit der Vorhersagen) und der Größe des Modells aus.
Implementierung eines TinyML-Showcase
Um die Herausforderungen eines TinyML-Projekts darzustellen, haben wir einen konkreten Showcase mit dem Projektnamen „TinyMeter“ implementiert. Die Problemstellung beinhaltet, den Zählerstand eines analogen Wasserzählers anhand eines Kamerabilds zu ermitteln. Dabei haben wir einen klassischen Ansatz des überwachten Lernens verfolgt: ein großer Trainingsdatensatz mit vielen Bildern von unterschiedlichen Zählerständen und dem dazu passenden Wert des Zählerstands als Label wird verwendet, um ein Machine Learning Modell zu trainieren.
Die Herausforderung ist es, das Machine Learning Modell so zu verkleinern und zu optimieren, dass es auf einem kleinen und vor allem günstigen Mikrocontroller ausgeführt werden kann. Da die Anwendung von neuronalen Netzen für unsere Problemstellung aus dem Bereich Computer Vision prädestiniert ist, stellen wir die Herausforderungen eines TinyML-Projekt im Folgenden spezifisch anhand von neuronalen Netzen dar.
Aufbau des Projekts

TinyML ist eine interdisziplinäre Thematik, daher muss man die Anforderungen aus zwei Perspektiven zu betrachten: Machine Learning und Hardware/Embedded.
Eine Anforderung an die Hardware ist zum Beispiel, dass sie klein und günstig ist. Daraus folgt, dass nur begrenzte Rechenleistung und Speicherkapazität zur Verfügung stehen. Andererseits muss die Hardware aber auch die gängigen ML-Frameworks unterstützen und über genügend Speicher (Arbeits- & Flash-Speicher) verfügen, damit das neuronale Netz tatsächlich ausgeführt werden kann. Für das neuronale Netz musste trotz geringer Größe eine gewisse Komplexität erhalten bleiben.
Mit diesen Anforderungen im Hinterkopf haben wir die Hardware und das ML-Framework, wie im Folgenden beschrieben wird, für unseren Showcase ausgewählt. Im weiteren Verlauf des Artikels stellen wir den Aufbau unseres Teststands für den Showcase dar und wie wir damit geeignete Datensätze zur Entwicklung unserer Machine-Learning-Modelle generiert haben. In der zweiten Hälfte des Artikels geben wir eine Übersicht über Methoden zur Verkleinerung von neuronalen Netzen und wenden diese Methoden auf unsere Problemstellung an. Schließlich beschreiben und bewerten wir das Gesamtsystem und diskutieren die wesentlichen Erkenntnisse aus unserer Showcase-Implementierung.
Welche TinyML-Frameworks gibt es?
TinyML ist ein junges Thema und dementsprechend ist die Auswahl an verfügbaren Frameworks klein. Nennenswert sind eigentlich nur drei: PyTorch Mobile, Edge Impulse und TensorFlow Lite.
PyTorch Mobile ist auf mobile Endgeräte ausgelegt und deswegen gibt es keine dedizierte Bibliothek für Mikrocontroller.
Edge Impulse ermöglicht eine einfache und intuitive Möglichkeit, neuronale Netze zu trainieren und zu implementieren. Die vereinfachte Bedienung kommt aber zu einem Preis, denn man ist auf die Nutzung der Weboberfläche von Edge Impulse beschränkt und schreibt eigentlich keinen eigenen Code. Eines der Hauptziele des Projekts ist es, die Herausforderungen jedes einzelnen Schrittes in einem TinyML-Projekt in Erfahrung zu bringen. Edge Impulse vereinfacht viele dieser Schritte und nimmt somit Erfahrungen vorweg, die wir selber machen wollen. Aus diesem Grund haben wir uns gegen Edge Impulse entschieden.
TensorFlow Lite ist eine kompakte Version von TensorFlow, das die Implementierung von neuronalen Netzen auf mobilen Endgeräten, Mikrocontrollern und anderen Edge-Geräten ermöglicht. Als etablierte Plattform kann TensorFlow neben einer sehr guten Dokumentation und vielen Code-Beispielen vor allem dadurch punkten, dass es man neuronale Netze in kompaktere TensorFlow-Lite-Netze (.tflite Files) umwandeln kann. TensorFlow Lite bietet eine Erweiterung namens TF-Lite-Micro, die die Ausführung der TF-Lite Netze auf Mikrocontrollern ermöglicht. Dazu werden die .tflite-Files in C-Byte Array umgewandelt, die in den Firmware Code des Microcontrollers eingebunden werden.
Hardware-Auswahl
Die erste Herausforderung eines TinyML-Projekts ist die Auswahl einer geeigneten Hardware-Plattform. Bei der Auswahl für den Showcase sind mehrere Anforderungen relevant: unter anderem die Kompatibilität mit TensorFlow Lite, ausreichend Speicher, und die Kompatibilität mit Kamera-Modulen. Für den Showcase wählen wir darüber hinaus gezielt Hardware, die tatsächlich „tiny“ ist, das heißt, sehr eingeschränkt in Speicher und Rechenleistung und vor allem günstig ist – in unserem Fall unter 30 Euro.

Auf dem Markt gibt es mittlerweile viele Mikrocontroller, die diesen Anforderungen größtenteils genügen, wie zum Beispiel Mikrocontroller aus dem Arduino Umfeld, die ESP Modelle von Espressif oder verschiedene Mikrocontroller von STM, und weiteren Herstellern. Für unseren Showcase nutzen wir das ESP-EYE Board von Espressif mit einem ESP32 Chip, einem Kameramodul, 8,5 MB Arbeitsspeicher und 4 MB Flash-Speicher. Dieser Mikrocontroller hat mehrere Vorteile; unter anderem ein bereits verbautes Kameramodul und externen SPI RAM. Außerdem ist er günstig und das hauseigene Framework ESP-IDF von Espressif liefert Funktionalitäten wie Kameratreiber sowie viel Beispiel-Code.
Der Vergleich zwischen einem Raspberry Pi 3 B und dem ESP-EYE in Tab. 1 verdeutlicht, dass der ESP-EYE tatsächlich „tiny“ ist:
| ESP-EYE | Raspberry Pi 3 B | |
| RAM / Flash | 8,5 MB / 4 MB | 1 GB / je nach SD-Karte |
| Prozessor | 32 Bit / 2 Kerne / 240 MHz | 64 Bit / 4 Kerne / 1.2GHz |
| Preis (1/2023) | ~ 25 € | ~ 60 € |
| Gewicht | 20 g | 42 g |
Für den Showcase haben wir bewusst einen Wasserzähler mit einfachem Aufbau (Modell: Kaltwasserzähler 3/4″ von KNM) gewählt, der es uns ermöglicht den Zählerstand leicht zu manipulieren, was unerlässlich ist, um einen Trainingsdatensatz zu erstellen
Aufbau des Teststands
Um große Trainings- und Testdatensätze zu erstellen, ist es unerlässlich, eine möglichst automatisierte Methode zu entwickeln, mit der schnell und einfach eine große Menge an unterschiedlichen Zählerständen generiert werden kann.

Der Wasserzähler (in Abb. 3) besteht aus zwei Einheiten, dem unteren Teil, der an die Wasserleitung angeschlossen wird, und dem oberen Teil, dem Zählwerk. Im unteren Teil befindet sich eine Turbine, die vom Wasser angetrieben wird und die Rotationsbewegung mit einem Magnet an einen weiteren Magneten im Zählwerk überträgt. So können beide Teile wasserdicht getrennt werden. Diese Eigenschaft machen wir uns zunutze, um den Zählerstand zu manipulieren. Die Rotation der Turbine wird durch einen Magneten simuliert, der an dem Schaft eines DC-Motors befestigt wird. Mit Hilfe eines 3D-gedruckten Gehäuses für den DC-Motor und das Zählwerk werden beide Komponenten im richtigen Abstand und Ausrichtung zueinander gehalten.
Eine weitere 3D-gedruckte Halterung erlaubt die Befestigung des ESP Boards vor dem Zählwerk, so dass die Kamera auf den Zählerstand ausgerichtet ist. Diese Halterung wird nur für einen Teil der Aufnahmen genutzt, sodass Datensätze mit unterschiedlichen Rahmenbedingungen erstellt werden können. Zum Beispiel haben wir den Abstand und die Ausrichtung der Kamera gegenüber dem Zähler und die Beleuchtung variiert. Folglich weisen die Bilder in den Trainingsdatensätzen schon nach der Erstellung eine gewisse Vielfalt auf, was für eine robuste Performanz des neuronalen Netzes wichtig ist.
Generierung der Trainingsdaten
Erstellung des Datensatzes
Mit dem Teststand ist es möglich, schnell einen großen Datensatz an Bildern mit unterschiedlichen Zählerständen zu erstellen. Dabei gehen wir wie folgt vor:
- Der DC-Motor wird mit Spannung versorgt (2V-2.5V, sonst dreht der Zählerstand zu schnell hoch).
- Ein Python-Skript schickt in regelmäßigen Abständen HTTP-GET Requests an den Webserver, der auf dem ESP läuft.
- Der ESP antwortet mit einem Bild des aktuellen Zählerstands mit einem Zeitstempel als Dateiname.
- Es wird ein großer Datensatz mit über 1000 Bildern erstellt.
- Im Nachgang wird jedes 50. Bild des Datensatzes manuell mit einem Label (hier der Zählerstand) versehen.
- Die Label der restlichen Bilder werden mit Hilfe dieser manuell gelabelten Stützstellen und dem Zeitstempel interpoliert.
Mit dieser Methode haben wir viele unterschiedliche Datensätze erstellt, mit unterschiedlicher Beleuchtung, Ausrichtung und Auflösung.
Analyse des Zählerstands
Der erste Datensatz mit ca. 1000 Bildern wurde in der Auflösung 320×240 und in Farbe aufgenommen. Später haben wir herausgefunden, dass es vorteilhaft ist, den Datensatz in Grautönen zu erstellen. Durch den Wechsel von Farb- zu Graustufenbildern kann gleichzeitig die Größe des neuronalen Netzes reduziert und insbesondere durch die gesparte Laufzeit die Auflösung der Bilder auf das Doppelte erhöht werden (640×480).
In Abb. 4 ist ein Beispiel einer Aufnahme eines Zählerstands dargestellt.

Der Zählerstand in Kubikmeter wird durch 8 Ziffern dargestellt, von denen 5 der Vorkommastelle entsprechen und 3 der Nachkommastelle. Die vierte Nachkommastelle wird durch eine rotierende Scheibe dargestellt, diese wurde im Showcase jedoch außen vor gelassen, da die Bestimmung dieser Nachkommastelle wenig Mehrwert bringt und aufgrund der anderen Darstellung im Vergleich zu den übrigen Ziffern die Komplexität des Problems deutlich erhöht hätte. Wie man in Abb. 4 erkennen kann, entsteht bei der Bestimmung der dritten Nachkommastelle ein weiteres Problem: die kontinuierliche Bewegung der Zahl erzeugt Zustände, die zwischen zwei Ziffern liegen. Die anderen Zahlen bewegen sich nicht kontinuierlich, sondern springen direkt auf die nächste volle Zahl um.
Lösung des Computer Vision – Tasks
Formulierung des ML-Problems
Bei der Erkennung von Zahlen oder Text auf Bildern handelt es sich um eine klassische Problemstellung für überwachtes Lernen. Das Erkennen des analogen Zählerstands lässt sich herunterbrechen auf das Erkennen der einzelnen Ziffern. Nun handelt es sich lediglich um ein Klassifikationsproblem, das für jede einzelne Ziffer gelöst und zu dem gesamten Zählerstand zusammengefügt werden muss.
Um dieses Klassifikationsproblem zu lösen, trainieren wir ein neuronales Netz, das die folgenden Ein- und Ausgabe hat:
- Eingabe: Ausschnitt einer Ziffer in Grauwerten.
- Ausgabe: Wert für Wahrscheinlichkeit, dass das Eingangsbild Ziffer (0-9) darstellt. Die Summe dieser Werte ergibt immer 100.
Als Klassifikationsergebnis wird die Ziffer gewählt, für die die Wahrscheinlichkeit am höchsten ist. Dieser Vorgang wird für alle Ziffern durchgeführt und die Ergebnisse werden anschließend zu einem Zählerstand zusammengefügt.
Aufteilung in Training-, Validation- und Test-Datensatz
Aus den Bildern des kompletten Wasserzählerstandes können die einzelnen Ziffern anhand der Bildkoordinaten ausgeschnitten werden, die zur Vereinfachung am Anfang einmal manuell bestimmt werden. So muss das Modell später nur eine Klassifikation einer einzelnen Ziffer ausführen. Dadurch entstehen 10 Klassen (0-9), die durch die führenden Nullen stark unbalanciert sind, d.h. es gibt viel mehr Nullen als andere Ziffern. Da unbalancierte Datensätze zu einem schlechten Klassifikator führen, werden die Klassen durch Over- und Undersampling balanciert. Dadurch wird sichergestellt, dass die Klassen nahezu gleich verteilt sind.
Die Daten werden anschließend in jeweils ein Trainings-, Validations- und Test-Set aufgeteilt, entsprechend mit einem 70/20/10-prozentigen Anteil. Um eine robustere Performance des neuronalen Netzes zu erreichen, bietet es sich an, die Vielfalt der Daten künstlich zu erhöhen. Die Trainings-, Validierungs- und Testdatensätze lassen sich durch Data Augmentation erweitern. Dafür werden die Helligkeit, Rotation, Schärfe und der Kontrast variiert. Da jedes Bild mit dem Zählerstand als Label versehen ist, kann auch jeder einzelnen Ziffer das richtige Label zugeordnet werden. So können die Datensätze umgewandelt werden und zu einer Sammlung an Aufnahmen von einzelnen Ziffern und dem dazugehörigen Label umgewandelt werden. Mit diesen Datensätzen kann nun das neuronale Netz trainiert werden.
Architektur und Beschreibung des Ausgangsmodell
Die Basis unseres Convolutional Neural Networks (CNN) stammt aus den Beispielen zur Lösung des MNIST-Datensatzes. Dieses wird mittels Hyperparameter-Tuning optimiert, wobei die Zielfunktion des Tunings aus der Anzahl an Parametern des Netzes und der Accuracy besteht, die mit dem Netz erreicht wird. Dadurch werden Hyperparameter selektiert, die zu einem besonders schlanken und effektiven Netz führen. Mit diesen ermittelten Werten wird das Netz in Abbildung 5 erzeugt: Das Eingangsbild wird durch zwei Convolutional Layer verarbeitet, bestehend aus Batch Normalization, Faltung und Max Pooling. Vor dem Flatten Layer (Reduktion der Dimension) werden die Tensoren nochmals mit der Batch-Normalization normalisiert und anschließend wird die Klasse im finalen Output Layer ermittelt.

Performance-Evaluierung des ursprünglichen CNN
Um Vergleichswerte für die spätere Evaluierung der Leistung des Netzes auf dem Mikrokontroller zu bestimmen, evaluieren wir das oben dargestellte Netz auf einem Entwicklersystem. Auf einem Macbook Pro 2018 benötigt dieses Ausgangsmodell für die Klassifikation einer Ziffer ~52 ms. Im Schnitt liegt die balancierte Accuracy des Modells bei 98,8 % – für unseren Showcase ausreichend. Das Ausgangsmodell ist hierbei mit 2,5 MB so groß, dass es nicht vom ESP geladen werden kann. Deswegen liegen nur die gemessenen Inferenzzeiten auf der Entwicklungsmaschine vor. Die Ergebnisse sind in Tab. 2 nochmals zusammengefasst.
|
Tensorflow 2
|
|
| Inferenz Zeit |
52,68 ms
|
| Accuracy | 98,80 % |
| Größe | 2.588 KB |
Wie verkleinert man ein tiefes neuronales Netz?
Das oben beschriebene Ausgangsmodell muss verkleinert werden, um es auf dem Zielsystem, hier dem ESP, lauffähig zu machen, möglichst ohne dabei die Accuracy der Ergebnisse zu kompromittieren. Es gibt verschiedene Verfahren, um neuronale Netze in dieser Hinsicht zu optimieren. Einen Teil dieser Optimierungsmöglichkeiten stellen wir im Folgenden vor
Pruning
Beim Pruning (dt. Beschneidung) werden die Gewichtsmatrizen des neuronalen Netzes während des Trainings nach und nach auf Null gesetzt, um eine sogenannte “sparse matrix“ (dt. dünnbesetzte Matrix) zu erhalten. Die resultierende dünnbesetzte Matrix lässt sich effizient komprimieren und die Inferenzzeit des Netzes wird verbessert, da Multiplikationen mit 0 ignoriert werden können. In unseren Experimenten bestätigt sich, dass sich dünnbesetzte Modelle deutlich effizienter komprimieren lassen. Das bringt zwar Vorteile bei der Übertragung und Persistierung der Modelle, aber aufgrund einer Limitierung des TFLite Frameworks – es unterstützt noch kein sogenanntes Structural Pruning – werden die 0-Operationen nicht ignoriert. Zudem erreicht das komprimierte Modell nach dem Entpacken wieder seine ursprüngliche Größe. Folglich setzen wir für unsere Zwecke kein Pruning ein, da sich für uns kein sichtbarer Vorteil erschließen lässt.
Quantization
Bei der Quantisierung werden kostenintensive Floating Point Operationen durch günstigere Integer Operationen ersetzt. Dadurch reduziert sich der Speicherbedarf des Netzes und die Latenz zur Inferenz. Ein Modell lässt sich sowohl nach dem Training quantisieren, Post-Training Quantization (kurz PTQ) als auch während des Trainings, Quantization-Aware Training (kurz QAT). Beide Methoden sind mit Verlust der Performance behaftet, wobei QAT laut Literatur den geringeren Verlust vorweisen soll. Dafür lassen sich mit PTQ bereits trainierte Modelle einfach konvertieren. Bei unseren Vorab-Experimenten erwies sich der Unterschied des Verlusts zwischen PYQ und QAT als geringfügig (0,02 %), wodurch wir uns für PTQ entschieden haben, da wir hiermit sowohl ein quantisiertes als auch ein nicht-quantisiertes Modell erhalten. Quantisierung ist bei unserem Showcase eine der wichtigsten Optimierungen, da bei der Initialisierung der Tensoren auf dem Mikrocontroller 8-Bit-Integer anstatt 32-Bit-Floats allokiert werden, was mit einem deutlich geringerem Speicherverbrauch einhergeht.
Knowledge Distillation
Knowledge Distillation ist eine Form der Komprimierung, bei der das Wissen eines sogenannten Teacher-Modells auf einen Student übertragen werden kann. Diese Methode wird häufig bei großen, komplexen neuronalen Netzen angewendet, bei denen ein Modell zu groß für die Anwendung ist. Stattdessen kann das Modell als Teacher genutzt werden, um das gelernte Wissen auf einen kleineren Student zu transferieren. Diese Technik ist für unseren Showcase besonders interessant, da der verfügbare Speicher auf dem Mikrocontroller begrenzt ist. Wir nutzen sogenannte Response-based Knowledge Distillation, bei welcher der Student versucht, die Vorhersagen des Teachers nachzuahmen, indem über den sogenannten „distillation loss“ der Fehler zwischen den Logits des Studenten und des Teachers minimiert wird.
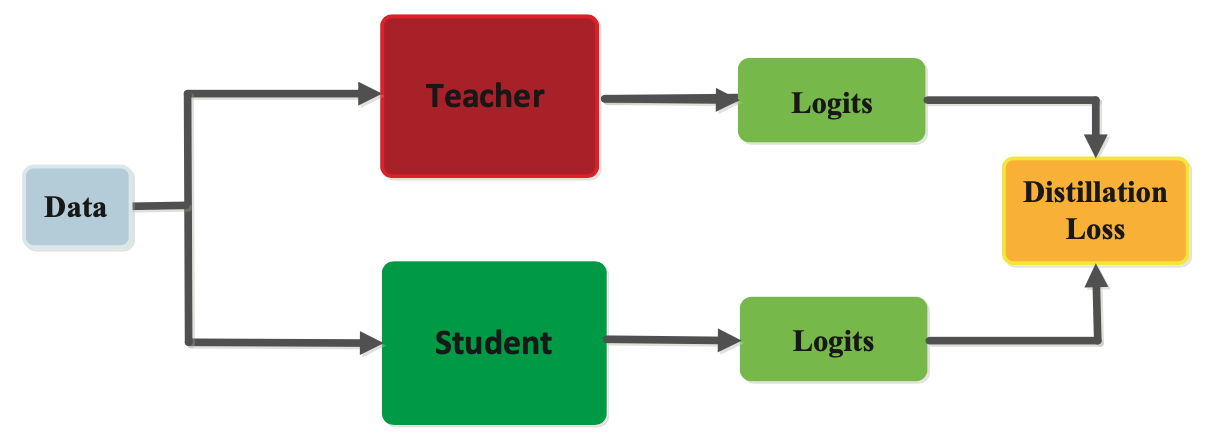
Dadurch lernt der Student die gleichen Vorhersagen wie der Teacher zu treffen. In unseren Experimenten konnten wir dadurch Studenten trainieren, die teilweise nur 25 % der Teacher Model Größe besitzen. Dies verringert sowohl die Laufzeit für die Inferenz als auch den benötigten Speicher. Die Komprimierung ist natürlich verlustbehaftet, was sich bei uns mit einem Verlust von ~0,4 % (Balanced Accuracy) bemerkbar macht. Mehr Details zum Thema Knowledge Distillation gibt es im Blogeintrag Deep Mutual Learning: A Critical Analysis of Online Distillation.
Kernel Optimierungen
Neben der Optimierung der Hyperparameter der Netze kann auch die Ausführung der Modelle optimiert werden. Hierfür kann die Implementierung von Tensorflow Micro bestimmte Operationen durch für die Hardware optimierte Operationen ersetzen, die teilweise in Assembler geschrieben sind. Für unseren Showcase nutzen wir die von Google Developers entwickelten Kernel-Optimierungen, die beim kompilieren der Firmware eingebettet werden.
Verkleinerung des Netzes für das TinyMeter: Ergebnisse
Performance/Leistung im Vergleich
Wie im vorherigen Kapitel erwähnt, ist das Ausgangsmodell zu groß, um es auf den ESP laden zu können. Die beschriebenen Optimierungen sind daher notwendig, um das Modell auf dem ESP ausführen zu können. In Tab. 3 werden die Auswirkungen der Optimierungsschritte dargestellt. Die Tabelle enthält zur Übersicht nur die wichtigsten Daten. Die nicht quantisierten Modelle konnten nicht auf den ESP geladen und ausgeführt werden, deshalb sind diese nicht aufgeführt. Auch ist die quantisierte Tensorflow-2-Version für uns nicht interessant. Die Tensorflow 2- und Lite-Modelle wurden auf einem Macbook Pro 2018 ausgeführt.
| Framework | Tensorflow Micro (ESP32s3) | Tensorflow Lite | Tensorflow 2 | ||||||
| Quantisiert | ✔︎ | ✔︎ | ✖︎ | ✖︎ | |||||
| Knowledge Distillation | ✔︎ | ✖︎ | ✔︎ | ✖︎ | ✔︎ | ✖︎ | ✖︎ | ||
| Optimierte Inferenz (ms) | 225,43 | 386,43 |
6,39
|
17,36
|
0,58
|
0,74
|
52,68
|
||
| Inferenz (ms) | 914,45 | 2355,3 | — | — | — | — | — | ||
| Accuracy (%) | 98,50 | 98,70 | 98,50 | 98,70 | 98,39 | 98,80 | 98,80 | ||
| Größe (KB) | 54 | 192 | 54 | 192 | 192 | 744 | 2.588 | ||

Zusammenfassend lässt sich sagen, dass die Optimierungen unserer Modelle die Größe von 2.588 KB auf 54 KB reduzieren. Der Performanceverlust ist mit ~0,3 % Accuracy, gemessen an der Reduktion des Speicherbedarfs, bemerkenswert gering. Dies ist aber höchstwahrscheinlich spezifisch für unsere Problemstellung und nicht direkt generalisierbar. In unserem Fall kann Knowledge Distillation die Größe des Netzes um ~25 % reduzieren. Die genutzten Kernel-Optimierungen haben jeweils einen großen Effekt auf quantisierten Netzen.
Erkenntnis und finales Modell
Der Grund hierbei ist, dass nach dem Aufruf der Aktivierungsfunktion der Output nochmals quantisiert werden muss. Die Kernel-Optimierungen verbessern diesen Schritt, wodurch die Quantisierung erst ihre volle Stärke zeigt. Tab. 3 zeigt die Laufzeiten für TF Lite, TF Micro und TF2 . In diesem Fall können nur die quantisierten Modelle auf den ESP geladen werden, da die Modelle sonst zu groß sind. Abb. 6 vergleicht schematisch den Aufbau des Ausgangsmodells und des optimierten Modells. Die Größen der Fully Connected Layer und der Convolutional Layer wurden bei der Knowledge Distillation jeweils halbiert. Insgesamt lässt sich zusammenfassend sagen, dass wir die Modellgröße bei nur geringen Performance-Verlusten stark reduzieren konnten.
TinyMeter: Das Gesamtsystem
Das hinsichtlich der Größe optimierte Modell ist, wie oben dargestellt, klein genug, um auf dem ESP-EYE ausgeführt zu werden. Um den Showcase zu vervollständigen und das Modell final zu bewerten, wird das Modell in eine Gesamtapplikation eingebettet. Das Modell besteht dabei lediglich aus einem Array aus Hexadezimal-Werten, das als Variable von der Firmware eingebunden werden kann, die auf dem ESP-EYE läuft. Darüber hinaus gibt es eine Desktop-Anwendung, über die das System konfiguriert und Zählerstände ausgelesen werden können. Die Funktionalität der einzelnen Komponenten wird im Folgenden näher beschrieben.
Firmware
Die Firmware auf dem ESP-EYE implementiert folgende Funktionalitäten:
- Fotoaufnahme mit dem Kamera-Modul.
- Algorithmus zur Bestimmung des Zählerstands (mittels des oben beschriebenen neuronalen Netzes).
- REST API zur Kommunikation mit der Desktop-Applikation.
Die Firmware stellt somit alle Funktionalitäten zur Verfügung, um den Zählerstand mit Hilfe des Kamerabilds zu ermitteln und um die Kommunikation mit einem Frontend zu errichten. Das ermöglicht eine einfache Bedienung durch den Endbenutzer.
Desktop-Anwendung
Die Desktop-Anwendung ermöglicht es Endbenutzer:innen, auf den ESP-EYE zuzugreifen und den Zählerstand zu ermitteln. Sie erfüllt folgende Funktionen:
- Darstellung des Kamerabildes
- Auswahl der einzelnen Ziffern im Kamerabild
- Anfrage & Darstellung des Zählerstands
- Speichern von Zählerständen
- Prüfung auf Plausibilität und Konsistenz der Zählerstände
Der Konfigurationsprozess beginnt mit dem Laden des aktuellen Kamerabildes. Der User kann auf diesem nun die einzelnen Ziffern mit einer entsprechend großen Box per Mausklick aus (Abb. 7). Die Informationen über Position und Größe der Ziffern werden im nächsten Schritt an den ESP-EYE übermittelt. Nun kann man eine Bestimmung des Zählerstandes anfragen. Dieser wird unter dem Zählerstand auf dem Kamerabild angezeigt – führende Nullen werden ignoriert. Als letzten Schritt kann der ermittelte Zählerstand gespeichert werden.

Im Tab History können die gespeicherten Zählerstände eingesehen werden. Bei gespeicherten Zählerständen, die unplausibel wirken (etwa weil ein kleinerer Wert ermittelt wurde, als ein Zeitschritt davor), wird eine Warnung angezeigt, aus der hervorgeht, dass dieser Zählerstand überprüft werden muss. Endbenutzer:innen können dann den Zählerstand händisch korrigieren.
Finale Performance-Evaluierung des TinyMeters
Testaufbau
Die Performance des Algorithmus wird in einem letzten Test auf dem ESP-EYE getestet. Für diesen Test nimmt der ESP-EYE neue Bilder auf und im Anschluss wird der Zählerstand ermittelt. Bei diesem Live-Test haben wir die Bilder und die zugehörigen Zählerstände manuell überprüft, um die Accuracy des Algorithmus auf komplett neuen Bildern mit unterschiedlicher Belichtung, Winkel, etc. zu bestimmen.
Wie bereits im Kapitel „Generierung der Trainingsdaten“ angesprochen, ist die Ermittlung der letzten Ziffer besonders herausfordernd, da durch die kontinuierliche Bewegung dieser Drehscheibe oft Zwischenzustände zwischen zwei Ziffern entstehen. Diese Zwischenzustände sind eine Herausforderung für unseren Algorithmus und sind oft der Grund, weswegen der gesamte Zählerstand nicht korrekt ermittelt wird.
Aus diesem Grund wird die Accuracy mit unterschiedlichen Metriken berechnet, um die Stärken und Schwächen unseres Algorithmus hervorzuheben. So wird einerseits die Accuracy der einzelnen Ziffern als auch die des gesamten Zählerstands ermittelt. Außerdem wird auch die Accuracy bestimmt, wenn die führenden Nullen (sehr einfach zu ermitteln) und die letzte Ziffer jeweils bewusst ignoriert werden, um zu verdeutlichen, wie der Accuracy-Verlust zustande kommt (Tab. 4).
|
Richtige Vorhersage von |
führende Nullen | letzte Ziffer | Accuracy |
| Alle Ziffern (1) | ✔︎ | ✔︎ | 96,62 % |
| Alle Ziffern (2) | ✔︎ | 93,24 % | |
| Alle Ziffern (3) | ✔︎ | 99,77 % | |
| Alle Ziffern (4) | 99,45 % | ||
| Gesamter Zählerstand | ✔︎ | ✔︎ | 73,77 % |
Auswertung
Wie unschwer zu erkennen ist, reduziert die Vorhersage der letzten Ziffer die Accuracy nicht unerheblich (Vergleich (1) und (3)). Außerdem verbessert eine große Anzahl an Nullen im Zählerstand die Accuracy minimal (Vergleich(4) und (3)). Bei der Berechnung der Accuracy des gesamten Zählerstand wird betrachtet, ob jede einzelne Ziffer im Zählerstand richtig ermittelt wurde. Dies zusammen mit der angeführten Problematik der letzten Ziffer führt dazu, dass die Accuracy des gesamten Zählerstands auf jeden Fall noch ausbaufähig ist. Zur weiteren Verbesserung wäre jedoch eine Erweiterung des Ansatzes notwendig und dies ist unabhängig von der erfolgreichen Reduktion der Größe des Modells zu sehen.
Die Ergebnisse dieser Tests decken sich mit den Ergebnissen aus den bisherigen Tests, die mit dem Testdatensatz durchgeführt wurden.
Fazit
In diesem Blog-Artikel haben wir einen funktionierenden und anschaulichen Showcase für die TinyML-Technologie beschrieben und dabei die Herausforderungen, die ein solches Projekt, das stets eine enge Zusammenarbeit von Data Scientists und Embedded-Entwickler:innen erfordert, mit sich bringt, diskutiert. Im Speziellen haben wir etablierte Verfahren zur Verkleinerung neuronaler Netze aufgezeigt und praktisch an unserem Showcase demonstriert. Mit diesen Verfahren war es uns möglich, ein mehrere MB großes neuronales Netz auf ca. 50 KB bei minimalem Performanceverlust zu verkleinern. Der Showcase wurde durch die Einbettung des neuronalen Netzes in ein funktionierendes und benutzerfreundliches Gesamtsystem vervollständigt.
Einige „Lessons learned“, die auch für zukünftige Projekte relevant sind, werden im Folgenden zusammengefasst:
- Machine-Learning-Modelle auf leistungsschwacher Hardware auszuführen ist möglich. Gängige Frameworks, wie TensorFlow, unterstützen bereits Verfahren zur Verkleinerung und Optimierung dieser Modelle.
- Ein klassisches neuronales Netz kann deutlich verkleinert werden. In unserem Fall, sogar ohne große Einbußen bei der Performance.
- TinyML ist bereits soweit ausgereift, dass man auch praktisch relevante Projekte damit implementieren kann. Sowohl die Hardware und auch die Software sind für die breite Masse verfügbar.
- Eine optimale Lösung von komplizierten Fällen bzw. Sonderfälle bei überwachtem Lernen (wie die Ermittlung der letzten Ziffer in unserem Showcase) stellen eine größere Herausforderung dar und benötigen oft zusätzlichen Aufwand, um zu guten Ergebnissen zu gelangen. Gerade im Embedded-Kontext ist typischerweise eine Kosten/Nutzen-Abwägung für den konkreten Anwendungsfall notwendig.
- Wir konnten für unseren Showcase die Plattform, mit der wir gearbeitet haben, und die Frameworks, die wir benutzt haben, selber aussuchen. In der Praxis ist dies häufig nicht der Fall und weitere Einschränkungen und zusätzliche Anforderungen auf Kundenseite können zu weiteren Herausforderungen führen.
Zusammenfassend sind wir der Überzeugung, dass TinyML als Technologie ein großes Potenzial aufweist und damit in Zukunft bei der Lösung vieler spannender Anwendungsfälle, eine entscheidende Rolle spielen wird.


