
Notice:
This post is older than 5 years – the content might be outdated.
Text classification is a field in natural language processing (NLP), which assigns text to given classes. With applications in sentiment analysis, spam detection or information retrieval, text classification has been widely researched. In this blogpost, I want to present my master’s thesis, which focused on transfer learning for text classification.
Thereby, one shot learning is a classification method aiming at learning from one or few samples per class. I was inspired by this paper from Koch et al., where one shot learning was applied on image classification. Similar to this approach, I want to use the architecture of the Siamese network for text classification. This network architecture can be found in the classification of images (Koch et al., 2015) and signature verification (Bromely et al., 1994) but was barely used in the field of NLP. In this blogpost, I want to give an overview of transfer learning with Siamese networks.
Transfer Learning
Recently, neural networks have been established as a popular approach in the field of NLP, requiring a large amount of labeled data. With the expansion of the online world, user comments are increasing daily and thus offer a versatile source to analyze; they just have to be labeled. Unfortunately, this process is often manual and therefore time consuming. Thus, one could assume that there is not enough data available for the task of aspect extraction. We want to overcome this problem by using transfer learning, an approach which learns with a small amount of data.
An extreme case of transfer learning is one shot learning, a classification method that learns from one or only a few samples per class. It addresses the real problem of often not having many data points available. The idea is based on the fact that the model tries to predict classes from which only one or a few samples exist in the evaluation set (Fei-Fei et al., 2006). In the field of image classification, one shot learning has been researched widely (e.g. Koch et al, 2015 or Fei Fei et al. 2016), but we want to integrate one shot learning for text classification.
Use case
The increasing popularity of online platforms encourages users to pose their opinions in various fields, such as products, movies and food. These opinions are often biased, with emotions being a valuable source to analyze. Opinion mining is a task in NLP, which deals with the analysis of text towards an emotion. Question-answering forums and social media platforms are its main sources. In opinion mining, the aspect-based sentiment analysis (ABSA) plays an important role. It deals with the aspect, or topic, extraction and sentiment classification of a text block. In this way, ABSA helps finding out what the text block thematizes and with with emotion it encompasses specific topics. In this use case, transfer learning can be used by learning on text similarity and applying on aspect extraction, the first step of ABSA. This blogpost will focus on the application of aspect extraction, although the task can be easily applied to several other use cases.
Problem description
The main goal is to extract an aspect, or label, from a text block, which can be a sentence or an entire comment. In the following, we use sentences for simplification. In the experiments, we compare a test sentence to other sentences whose labels are known. These sentences form a support set. For the label prediction of a test sentence, we assign the label of the most similar sentence in the support set to the test set. In addition to the transfer learning approach, we combine this with one shot learning. The method selects one sentence from each label class in order to compare it to the test sentence. If we select \(k\) sentences from each label class, we call this setting few shot learning. Formally, the problem is defined as follows: Let \(L\) be the number of label classes. Given a test sentence \(s\) and few samples \({s_l}^L_{l=1}\) with \(i \in { 1,..,L }\) from a support set, compare \(s\) to \(s_l\) and assign \(s\) the aspect of the most similar sentence to it (Koch et al., 2015):
\(L^∗ =\arg \max p^{(l)}\),
with \(p^{(l)}\) representing the similarity.
Siamese Networks
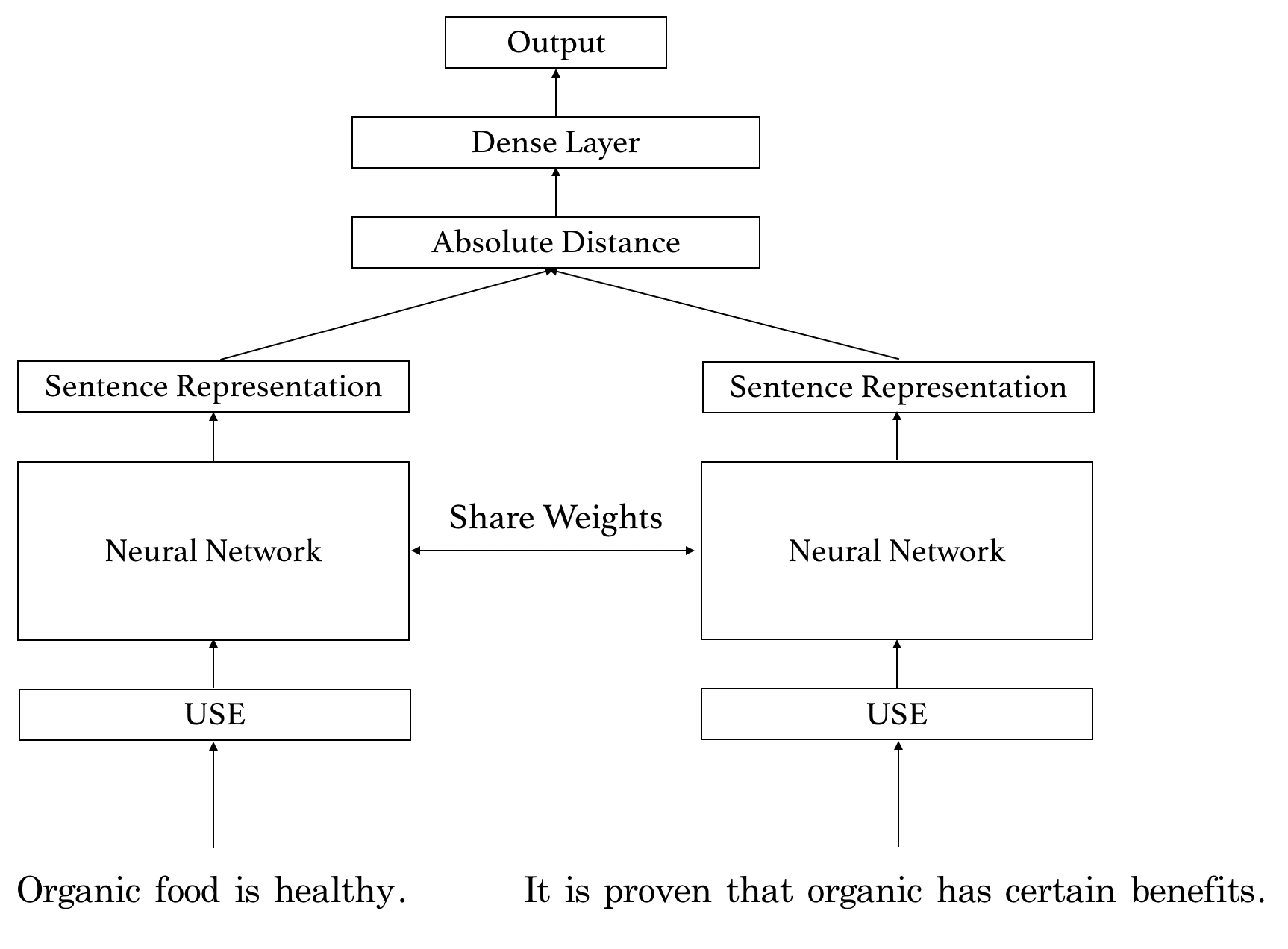
Named after the Siamese twins (or conjoined twins), the network architecture consists of two input objects and one output that ideally indicates the similarity between the two input objects (Bromley et al., 1994). The objects are pushed into the network which consists of two distinct sub-networks sharing their weights such that similar input objects are mapped in a similar way. These networks create a common representation of the input objects which are merged with a layer. That layer can employ a distance function and the output is mainly a probability value ranging between 0 and 1. In this blogpost, the Siamese network takes two text blocks as input and outputs their similarity. Below, we show the abstract building blocks of the network.
In the first step, the network takes the sentence in a raw text format as input. Afterwards, it computes the sentence embedding of dimension 512 with the help of the Google Universal Sentence Encoder (USE) (Cer et al., 2018). This embedding is then pushed through a neural network, which maps the USE sentence embedding to a smaller dimension. The neural network consists of one to two dense layers. The other input sentence is similarly processed through the exact same network, while the neural networks share their weights. In this way, it is guaranteed that similar sentences pushed through different neural networks do not have completely different sentence embeddings. The final sentence representations are compared to each other using the absolute distance. This distance is pushed through another dense layer which is our output layer and produces the probability \(p \in [0,1]\), which denotes the similarity score between the two inputs.
The training proceeds as follows in that we sample equally similar and dissimilar sentence pairs per batch. The similarity is based on the grouping of the dataset. Take the use case of ABSA as an example. In this case, two sentences might be similar when they are labeled with the same aspect. The training for dissimilarity follows in the same way. We performed the training on a dataset which contains roughly 10.000 sentences about organic food crawled from question-answering forums. In total, we can generate \(\frac{n \cdot (n-1)}{2}\) sentence pairs. Thus, the training can already be performed on a small dataset.
Learning approaches
One Shot Learning
In real life settings, we might only have a few sentences per class. Often, the dataset is unbalanced so that some classes have many sentences and some only have one. We reproduce this setting by selecting exactly one sentence per aspect class at random. The idea behind this setting is that the selected sentence acts as a representative for this class. In this experiment, we would like to find out if the Siamese network is able to detect text similarity based on one shot per class.
Few Shot Learning
Text is random in nature and when crawled from social media platforms it might be grammatically wrong or contain words in non-standard spelling. We want to guarantee a reliable representation for an entire class because one sentence might not be sufficient when picked at random. Since we do not want to influence the sampling with domain knowledge, we extend the idea of one shot learning by sampling not only one but \(k \in N\) sentences from a class. This setting is referred to as few shot learning. In this way, we hope to make the classes more representative during the evaluation. Additionally, we were interested in how well the model performs when we do not sample the sentences but simply compare \(s\) to all sentences from all classes in the evaluation set. This implies that the classes are not treated fairly since some have less sentences than others. Nevertheless, the experiment adapts to realistic settings and acts as a reference to the experiments with a fixed \(k\).
Text classification
Let us now have a look at the results of the text classification. We select the following exemplary sentences from the topic organic food in order to demonstrate the aspect prediction:
Genetically Modified Organisms (GMO)
- Genetically modified food might taste better but is unhealthy!
- GMO turned out to trigger allergic reactions.
Environment
- The popularity of organic food has increased since it turned out to be good for the environment.
- Producing organically excludes the use of pesticides and chemicals.
Social Factors
- Food produced organically is too expensive and definitely not affordable for everyone.
- The geographic distance between farmer and consumer can lead to higher prices.
Health
- It is proven that organic has certain health benefits.
- Organic food is healthy.
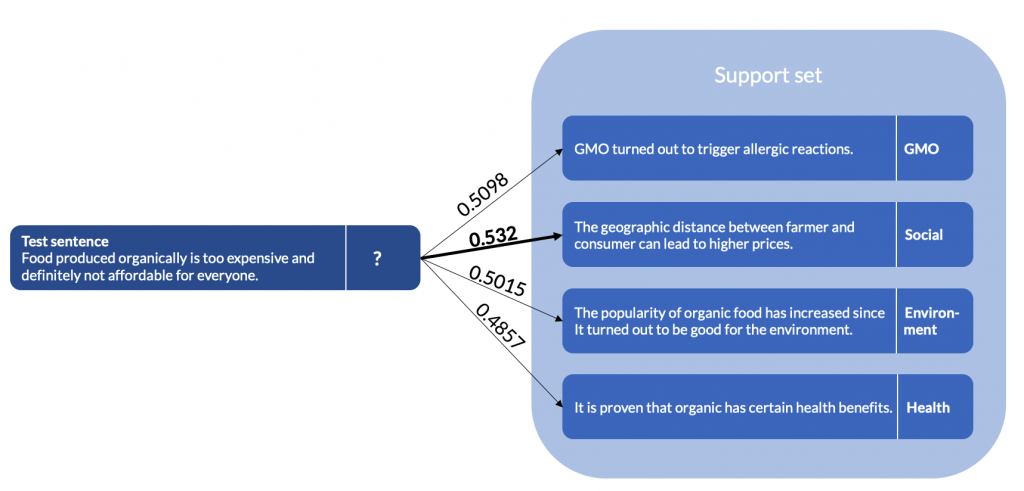
When classifying the sentences, we declare one sentence as test sentence and compare it with several other sentences. Since the setting is one shot learning, we sample exactly one sentence per class and compare these to the test sentence. An exemplary comparison is visualized in the figure below. On the left, we see the test sentence, on the right the support set with the sentences whose labels are known. Since the second comparison delivers the highest similarity score, we conclude that these sentences are the most similar to each other. Thus, we assign the aspect Social to the test sentence. When we have a look at the definitions above, this classification is correct.
In addition, the experiment was processed for several other sentences whose results are listed in the table below. In the one shot learning approach, we can see that the last sentence pair is classified correctly to Social factors according to our definitions. Unfortunately, the first and the second classification did not match according to our definitions. In the first classification, the sentence It is proven that organic has certain health benefits. was categorized into the aspect class health, while the second sentence The popularity of organic food has increased since it turned out to be good for the environment. belongs to the class environment.
In the second classification, the sentence Producing organically excludes the use of pesticides and chemicals. was defined to be from the category environment, while the sentence GMO turned out to trigger allergic reactions. was categorized into GMO. Since both sentences thematize modified food, the classification is not completely wrong, but just does not fit our definitions. Contrary, the few shot learning approach improves the classification by far. In average, this learning approach categorizes the sentences more often correctly, which can be seen in the three classifications below. The only classification which did not fit our definitions is the second sentence pair, which is equivalent to the second sentence pair in the one shot learning approach.
Conclusion
In this blogpost, we investigated how transfer learning can be used for text classification, computing text similarity with the architecture of a Siamese networks. We saw that text similarity can be learned and applied to the task of aspect extraction. In this setting, we introduced one shot learning and few shot learning. One shot learning turned out to be difficult for text classification, while few shot learning can achieve significantly better results, increasing the constant \(k\). Lastly, the experiments showed that the prediction highly depends on the dataset and its class definitions.
Sources
- Bromley et al., Signature Verification using a „Siamese“ Time Delay Neural Network 1994
- Cer et al., Universal Sentence Encoder 2018
- Fei Fei et al., One-Shot Learning of Object Categories 2006
- Koch et al., Siamese Neural Networks for One-shot Image Recognition 2015


