
In this blog post, I will walk you through the process of fine-tuning and evaluating Llama-3 and DeepSeek-Coder for detecting software vulnerabilities. I will share valuable insights and key takeaways gained from this work.
Large Language Models (LLMs) have become present everywhere on the internet, known for their versatility in performing a wide range of tasks. At inovex, we leverage LLMs for various internal and external projects. In my thesis, I explored the potential of LLMs to detect software vulnerabilities and enhance their performance through fine-tuning.
The Problem
Software vulnerabilities can emerge in any project, no matter its size. Detecting them quickly is important, as undetected vulnerabilities can result in significant financial losses and mitigate user trust. [1]
To address this issue, static application security testing (SAST) tools are commonly used, which rely on pattern matching, data and control flow analysis, and more. However, traditional SAST tools have limitations in identifying more complex vulnerabilities and cannot adapt to new ones. This is where advanced approaches, such as leveraging machine learning, come into play. These approaches are able to generalize to unseen cases and detect emerging vulnerabilities. Whereby fine-tuning LLMs, I aimed to improve the detection of intricate vulnerabilities that conventional tools might miss.
Experimental Evaluation
In the following, I will introduce the dataset and the prompts used for the experiments. Figure 1 shows the fine-tuning and evaluation process, offering a structured overview.
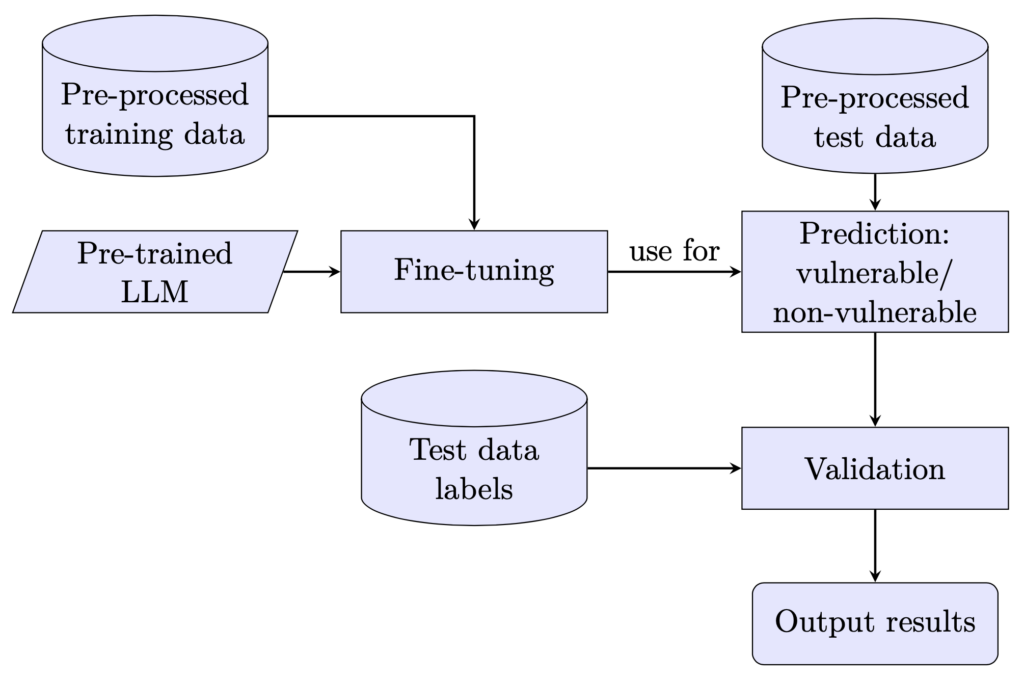
Dataset
I chose to use the Draper VDISC dataset, as it provides 1.27 million synthetic and real-world function-level samples of C and C++ source code. Each data point is labeled with its respective Common Weakness Enumeration (CWE), summarized in Table 1.
| CWE | Frequency | Description |
|---|---|---|
| CWE-120 | 3.70% | Buffer Copy without Checking Size of Input (‚Classic Buffer Overflow‘) |
| CWE-119 | 1.90% | Improper Restriction of Operations within the Bounds of a Memory Buffer |
| CWE-469 | 0.95% | Use of Pointer Subtraction to Determine Size |
| CWE-476 | 0.21% | NULL Pointer Dereference |
| CWE-other | 2.70% | Improper Input Validation, Use of Uninitialized Variables, Buffer Access with Incorrect Length Value, etc. |
This dataset was chosen as most system-level vulnerabilities emerge from C and C++ code. Since both C and C++ allow for manual memory handling, they provide programmers with a high degree of control and flexibility over system resources. However, this flexibility comes at the cost of increased risk of memory management errors, such as buffer overflows, use-after-free vulnerabilities, and dangling pointers.
Prompt design
As prompt design has a great impact on the performance of LLMs, I decided to use well-performing prompts from related works instead of creating new ones. The used prompts are displayed in Table 2. Both prompts provide a binary response, allowing for easy automatic classification.
| Prompt ID | Prompt |
|---|---|
| PD-1 [2] | Is this code vulnerable? Answer in only Yes or No. |
| PD-2 [3] | I want you to act as a vulnerability detection system. Is the following function buggy? Please answer Yes or No. |
Results of pre-trained LLMs
To compare the effectiveness of the pre-trained and fine-tuned models, I conducted an evaluation of several pre-trained large language models. Among these, GPT-4-0613 was used as the baseline for comparison. This approach allowed for a clear assessment of the improvements gained through fine-tuning.
Due to the limitations of most models in providing strictly „yes“ or „no“ answers, I initially reviewed some outputs manually and identified specific keywords for pattern matching the results. Examples of keywords for positive responses include “yes“ and “is vulnerable“. Additionally, responses that were not automatically classified using these keywords were then manually reviewed and classified.
| Model | Prompt | Unclassified | Precision | Recall | F1-score |
|---|---|---|---|---|---|
| Deepseek-coder-6.7b-instruct | PD-1 | 143 | 0.040 | 0.378 | 0.072 |
| GPT-4-0613 | PD-1 | 1 | 0.164 | 0.442 | 0.239 |
| Llama-2-7b-chat | PD-1 | 129 | 0.052 | 0.957 | 0.099 |
| Llama-2-7b-chat | PD-2 | 394 | 0.051 | 1.000 | 0.098 |
| Llama-3-8B-Instruct | PD-1 | 138 | 0.073 | 0.638 | 0.131 |
| Mistral-7B-Instruct-v0.2 | PD-1 | 360 | 0.055 | 0.513 | 0.100 |
| Mistral-7B-Instruct-v0.2 | PD-2 | 941 | 0.103 | 0.600 | 0.177 |
The results indicated that the prompt design PD-1 performed greatly better than PD-2. Especially in providing a reasonable and classifiable output.
GPT-4 performed best overall and did a great job in only returning “yes“ or “no“ with just one sample remaining unclassified.
For the fine-tuning process I chose Llama-3 and DeepSeek-Coder. Llama-3 has the best performance among the open-weight models, and DeepSeek-Coder was mainly trained on source-code, which could help with understanding the given code.
Fine-Tuning Llama-3 and DeepSeek-Coder
For fine-tuning both models, I used the script provided by Phil Schmid in his blog post about fine-tuning LLama-3-70B. I will share interesting insights gained from the experiments that could be important for further experiments in that direction. The insights are pretty similar between Llama-3 and DeepSeek-Coder. Some of these might also apply to other tasks where the LLM should classify things in binary classes. The insights concern the chat template for Llama-3 and the hyperparameters.
Chat template:
Phil Schmid provided an Anthropic-/ Vicuna-like chat template and used it in his work. In my experiments, I discovered that the Llama-3 specific chat template greatly improved the performance. Since the model was trained on the Llama-3 template, it can better use its previous knowledge. The number of unclassified samples of the fine-tuned models was reduced from around 20% to 0.
Batch size:
Typically, a larger batch size ensures stability during fine-tuning and allows for a more stable process. A batch size greater than 4 led to almost 0 as positive classified samples. As the dataset is unbalanced, each batch contains more negative samples than positive, which leads to training mostly towards negative responses.
Training split:
There exist several approaches to generating a training dataset. Most sources suggest a 50:50 split [4] to reduce overfitting on the majority class. During my tests, a training dataset where 25% of the samples were vulnerable worked the best. The given dataset split does not provide enough vulnerable samples, and a 50:50 split led to too many false positives.
Fine-Tuned Results
Table 4 shows the results from the best fine-tuned models as well as the best pre-trained model. Fine-tuning the models greatly improves their performance and allows them to outperform GPT-4-0613, with an F1-score almost twice as high.
| Model | Unclassified | Precision | Recall | F1-score |
|---|---|---|---|---|
| Llama-3 | 0 | 0.391 | 0.457 | 0.422 |
| Deepseek-Coder | 0 | 0.277 | 0.440 | 0.340 |
| GPT-4-0613 | 1 | 0.164 | 0.442 | 0.239 |
Performance per CWE
An interesting measurement is the performance per CWE class. Table 5 shows the accuracy of the best-performing fine-tuned Llama-3 model. Its performance is noticeably low for CWE-476 which is a NULL pointer dereference. This kind of vulnerability cannot be detected well in a function itself. The model might need more context of how the function is used. Also, the performance for the CWE-other class is considerably low, which could arise from few examples per specific CWEs in the training data.
| CWE | Correct | Incorrect | Accuracy |
|---|---|---|---|
| CWE-119 | 60 | 42 | 0.588 |
| CWE-120 | 56 | 36 | 0.609 |
| CWE-469 | 5 | 3 | 0.625 |
| CWE-476 | 5 | 51 | 0.089 |
| CWE-other | 34 | 58 | 0.370 |
| Non-vulnerable | 4401 | 249 | 0.946 |
model.
Conclusion
In this blog post, LLMs were used for software vulnerability detection, both in their pre-trained and fine-tuned state. Fine-tuning greatly helps the model to understand the given task and reduce the amount of false positives, allowing it to beat GPT-4.
Nevertheless, this experiment shows that there is still a lot of work to be done before LLMs can be used for reliable vulnerability detection. One important step is creating a large training dataset with reliable labels. Another step could include providing additional context to improve the classification of complex vulnerabilities.
A different work using abstract syntax trees from Feras Zaher-Alnaem achieved better results than the fine-tuned LLMs.
References
[1] A. Anwar et al. “Measuring the cost of software vulnerabilities“, 2020.
[2] Moumita D. Purba et al. “Software Vulnerability Detection using Large Language Models“. 2023.
[3] Benjamin Steenhoek et al. “A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection“. 2024.
[4] Susan S, Kumar A. “The balancing trick: Optimized sampling of imbalanced datasets—A brief survey of the recent State of the Art“. 2021.


